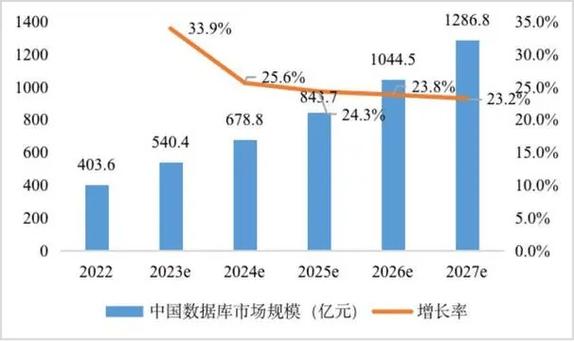
大数据整理是一个涉及数据收集、存储、处理和分析的复杂过程,旨在从大量的数据中提取有价值的信息和洞察。以下是大数据整理的一般步骤:
1. 数据收集:首先,需要从各种来源收集数据,这些来源可能包括数据库、文件、网络、传感器等。收集的数据可以是结构化的(如关系型数据库中的数据)或非结构化的(如文本、图像、视频等)。
2. 数据清洗:收集到的数据往往存在错误、重复、缺失等问题,需要进行清洗和预处理。这可能包括去除重复数据、填补缺失值、纠正错误数据等。
3. 数据整合:将来自不同来源的数据整合到一个统一的格式中,以便进行后续的分析和处理。这可能涉及到数据转换、数据映射等操作。
4. 数据存储:将整理好的数据存储在合适的数据存储系统中,如关系型数据库、NoSQL数据库、数据仓库等。存储系统的选择取决于数据的类型、规模和访问需求。
5. 数据处理:对存储的数据进行计算和分析,以提取有价值的信息和洞察。这可能包括数据挖掘、机器学习、统计分析等操作。
6. 数据可视化:将处理后的数据以图形、图表等形式展示出来,以便更直观地理解和分析数据。这有助于发现数据中的模式和趋势,以及做出基于数据的决策。
7. 数据安全:在整个大数据整理过程中,需要确保数据的安全性和隐私性。这可能涉及到数据加密、访问控制、审计等安全措施。
大数据整理是一个不断发展和演变的领域,随着技术的进步和数据的增长,新的工具和方法不断涌现。因此,大数据整理的实践者需要不断学习和适应新的技术和方法,以应对不断变化的数据挑战。
大数据整理的重要性

在当今信息爆炸的时代,大数据已经成为企业、政府和研究机构的重要资产。数据的价值并非与生俱来,而是需要经过一系列的整理和处理过程。大数据整理,作为数据治理的关键环节,对于数据价值的挖掘和利用至关重要。
数据整理的定义与目标
数据整理,顾名思义,就是对原始数据进行清洗、转换、整合和优化,使其能够满足特定需求的过程。其目标在于提高数据质量、降低数据冗余、增强数据可用性,从而为后续的数据分析、挖掘和应用提供可靠的基础。
数据整理的关键步骤
1. 数据采集:首先,需要从各种渠道收集所需的数据,包括内部数据库、外部数据源、社交媒体等。这一步骤要求确保数据的完整性和准确性。
2. 数据清洗:对采集到的数据进行初步的清洗,去除重复、错误、缺失等无效数据,提高数据质量。
3. 数据转换:将不同格式的数据转换为统一的格式,以便后续处理和分析。例如,将文本数据转换为数值型数据,或将不同时间格式的数据统一为标准格式。
4. 数据整合:将来自不同来源的数据进行整合,形成一个统一的数据集。这一步骤要求解决数据之间的冲突和矛盾,确保数据的一致性。
5. 数据优化:对整理后的数据进行优化,提高数据存储和查询效率。例如,通过建立索引、压缩数据等手段,降低数据存储空间和查询时间。
数据整理的技术手段
1. 数据清洗工具:如Python的Pandas库、R语言的dplyr包等,可以方便地进行数据清洗和转换。
2. 数据集成工具:如Apache Hadoop、Spark等,可以实现对大规模数据的分布式存储和处理。
3. 数据可视化工具:如Tableau、Power BI等,可以帮助用户直观地展示数据整理的结果。
数据整理的应用场景
1. 企业运营:通过数据整理,企业可以更好地了解客户需求、优化产品和服务、提高运营效率。
2. 政府决策:政府可以利用数据整理技术,对民生、经济、环境等领域的数据进行分析,为政策制定提供依据。
3. 学术研究:数据整理有助于研究人员获取高质量的数据,提高研究结果的可靠性和可信度。
数据整理的挑战与应对策略
1. 数据质量:数据质量是数据整理的核心问题。应对策略包括建立数据质量评估体系、加强数据清洗和校验等。
2. 数据安全:在数据整理过程中,需要确保数据安全,防止数据泄露和滥用。应对策略包括数据加密、访问控制、数据脱敏等。
3. 技术挑战:数据整理涉及多种技术手段,对技术人员的专业能力要求较高。应对策略包括加强人才培养、引进先进技术等。
大数据整理是数据治理的重要环节,对于数据价值的挖掘和利用具有重要意义。通过掌握数据整理的技术手段和应用场景,我们可以更好地应对数据时代的挑战,为企业、政府和研究机构创造更大的价值。