RF 机器学习
RF(随机森林)是一种强大的机器学习算法,广泛应用于分类、回归和特征选择等任务。RF 通过构建多个决策树并对它们的结果进行集成,以减少过拟合和提高模型泛化能力。
RF 的工作原理
1. 构建多棵决策树: RF 首先构建多棵决策树,每棵树都基于原始数据集的一个随机子集。子集的选择可以通过自助采样法(bootstrap sampling)实现,即从原始数据集中有放回地随机抽取样本。2. 随机特征选择: 在构建每棵树时,RF 会从所有特征中随机选择一部分特征,用于划分节点。这样可以增加模型的多样性,并减少对单个特征的依赖。3. 树的生长: 每棵树都根据选定的特征进行分裂,直到达到预设的深度或满足其他停止条件。4. 集成预测: 对所有树的预测结果进行集成,得到最终的预测结果。集成方式可以是多数投票法(分类任务)或平均法(回归任务)。
RF 的优势
强大的泛化能力: 通过集成多棵树,RF 可以有效地减少过拟合,提高模型的泛化能力。 鲁棒性: RF 对异常值和噪声不敏感,能够处理缺失数据。 特征选择: RF 可以用于特征选择,识别对预测结果贡献最大的特征。 易于解释: 相比于其他复杂的机器学习算法,RF 的结果更容易解释。
RF 的应用
分类: RF 可以用于各种分类任务,例如垃圾邮件过滤、疾病诊断等。 回归: RF 可以用于各种回归任务,例如房价预测、股票价格预测等。 特征选择: RF 可以用于识别对预测结果贡献最大的特征,从而简化模型并提高效率。 异常检测: RF 可以用于检测数据集中的异常值。
RF 的参数
树的数量: 树的数量越多,模型的泛化能力越强,但计算成本也越高。 树的最大深度: 树的深度越大,模型越复杂,但也更容易过拟合。 特征的数量: 在每棵树中选择的特征数量越多,模型的多样性越高,但也更容易过拟合。
RF 的实现
RF 可以使用多种编程语言实现,例如 Python、R 和 MATLAB。常用的 Python 库包括 scikitlearn 和 TensorFlow。
RF 是一种强大的机器学习算法,具有强大的泛化能力、鲁棒性和特征选择能力。它广泛应用于各种机器学习任务,是机器学习领域的重要工具之一。
希望以上信息能帮助您更好地理解 RF 机器学习算法。如果您有任何其他问题,请随时提问。
深入解析RF机器学习:随机森林算法的应用与优势
随着大数据时代的到来,机器学习技术在各个领域得到了广泛应用。其中,随机森林(Random Forest,RF)算法因其强大的预测能力和良好的泛化性能,成为机器学习领域的一大亮点。本文将深入解析RF算法,探讨其在实际应用中的优势。
一、什么是随机森林算法?
随机森林算法是一种基于决策树的集成学习方法。它通过构建多个决策树,并对它们的预测结果进行投票或平均,从而得到最终的预测结果。与单个决策树相比,随机森林算法具有以下特点:
强泛化能力:随机森林算法能够有效降低过拟合现象,提高模型的泛化性能。
鲁棒性:随机森林算法对噪声数据具有较强的鲁棒性,能够处理大规模数据集。
可解释性:随机森林算法可以评估特征的重要性,有助于理解模型的预测过程。
二、随机森林算法的工作原理
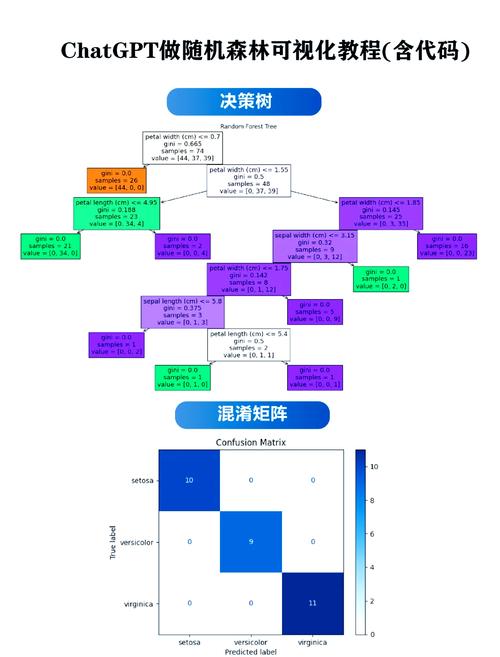
随机森林算法的工作原理主要包括以下步骤:
从原始数据集中随机抽取一定数量的样本,构建多个决策树。
在每个决策树的构建过程中,随机选择部分特征进行划分,以增加模型的多样性。
对每个决策树的预测结果进行投票或平均,得到最终的预测结果。
三、随机森林算法的应用场景
随机森林算法在各个领域都有广泛的应用,以下列举一些常见的应用场景:
金融领域:风险评估、信用评分、股票预测等。
医疗领域:疾病诊断、药物研发、患者预后等。
生物信息学:基因功能预测、蛋白质结构预测等。
自然语言处理:文本分类、情感分析等。
四、随机森林算法的优势
随机森林算法具有以下优势:
强大的预测能力:随机森林算法能够处理大规模数据集,并具有较高的预测精度。
良好的泛化性能:随机森林算法能够有效降低过拟合现象,提高模型的泛化性能。
可解释性:随机森林算法可以评估特征的重要性,有助于理解模型的预测过程。
鲁棒性:随机森林算法对噪声数据具有较强的鲁棒性,能够处理大规模数据集。
随机森林算法作为一种强大的机器学习算法,在各个领域都有广泛的应用。其强大的预测能力、良好的泛化性能和可解释性等特点,使其成为机器学习领域的一大亮点。随着技术的不断发展,相信随机森林算法将在更多领域发挥重要作用。