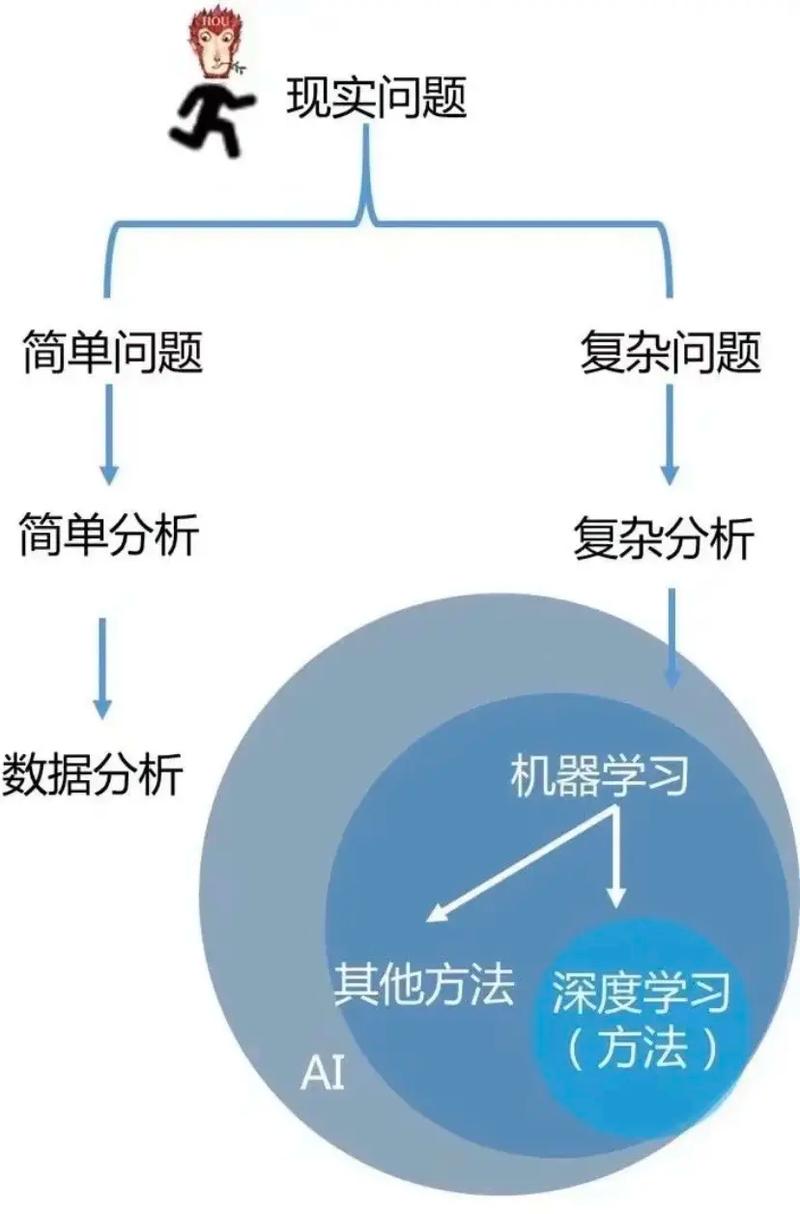
机器学习数据通常是指用于训练和测试机器学习模型的数据集。这些数据集可以包含各种类型的数据,如文本、图像、音频、视频等。机器学习数据通常具有以下特点:
2. 特征:机器学习数据通常包含特征,这些特征是用于描述数据集的属性。例如,在图像分类任务中,特征可以是图像的像素值。
3. 量:机器学习数据集通常需要包含大量的数据,以便模型能够学习到有效的特征和模式。
5. 分布:机器学习数据集的分布对于模型的泛化能力至关重要。数据集应该具有代表性的分布,以便模型能够学习到各种不同的特征和模式。
7. 多样性:机器学习数据集应该具有多样性,以便模型能够学习到各种不同的特征和模式。
8. 适应性:机器学习数据集应该具有适应性,以便模型能够适应不同的环境和任务。
9. 透明性:机器学习数据集应该具有透明性,以便研究人员和开发者能够了解数据集的来源和特性。
10. 可扩展性:机器学习数据集应该具有可扩展性,以便模型能够适应不断变化的数据和任务。
11. 安全性:机器学习数据集应该具有安全性,以便保护数据隐私和防止数据泄露。
12. 可用性:机器学习数据集应该具有可用性,以便研究人员和开发者能够轻松地访问和使用数据集。
13. 可解释性:机器学习数据集应该具有可解释性,以便研究人员和开发者能够理解模型的学习过程和结果。
14. 可重用性:机器学习数据集应该具有可重用性,以便模型能够在不同的任务和环境中进行重用。
15. 可维护性:机器学习数据集应该具有可维护性,以便研究人员和开发者能够对数据集进行更新和维护。
机器学习数据的质量和特性对于模型的性能和泛化能力至关重要。因此,在构建机器学习模型之前,需要对数据进行适当的清洗、预处理和选择,以确保数据的质量和特性符合模型的要求。
机器学习数据的重要性

在机器学习领域,数据是构建和训练模型的基础。没有高质量的数据,机器学习算法就无法有效地学习和做出准确的预测。因此,了解机器学习数据的重要性是至关重要的。
数据质量对模型性能的影响
数据质量直接影响到机器学习模型的性能。高质量的数据意味着数据是准确、完整、无噪声的,这样的数据有助于模型更好地学习特征和模式。相反,低质量的数据可能会导致模型学习到错误的模式,从而影响其预测能力。
数据预处理的重要性

在将数据用于机器学习之前,通常需要进行预处理。数据预处理包括数据清洗、数据转换、数据归一化等步骤。这些步骤有助于提高数据质量,减少噪声,并使数据更适合模型训练。
数据集的选择与构建
选择合适的数据集对于机器学习项目的成功至关重要。数据集应该包含足够的数据点,以使模型能够学习到足够的特征。此外,数据集应该具有代表性,能够反映真实世界的情况。
数据标注与数据增强

数据隐私与伦理问题

随着机器学习在各个领域的应用日益广泛,数据隐私和伦理问题也日益凸显。在使用数据时,必须确保遵守相关法律法规,尊重个人隐私,并避免数据滥用。
数据集成与数据管理

在处理大量数据时,数据集成和数据管理变得尤为重要。数据集成涉及将来自不同来源的数据合并成一个统一的数据集。数据管理则包括数据的存储、检索、备份和恢复等操作。
数据可视化与探索

数据可视化是一种强大的工具,可以帮助我们更好地理解数据。通过可视化,我们可以发现数据中的模式、趋势和异常。数据探索则是对数据进行深入分析,以揭示数据背后的故事。
机器学习数据工具与技术

为了有效地处理和分析机器学习数据,研究人员和工程师使用了一系列工具和技术。这些工具包括数据清洗库(如Pandas)、数据可视化工具(如Matplotlib和Seaborn)、机器学习框架(如TensorFlow和PyTorch)等。
结论
机器学习数据是机器学习成功的关键。通过确保数据质量、进行有效的数据预处理、选择合适的数据集、处理数据隐私问题以及使用适当的工具和技术,我们可以构建出更准确、更可靠的机器学习模型。随着机器学习技术的不断发展,数据在其中的作用将更加重要。
- 机器学习
- 数据质量
- 数据预处理
- 数据集
- 数据标注
- 数据增强
- 数据隐私
- 数据集成
- 数据可视化
- 数据管理
- 机器学习工具
- 机器学习框架