查询大数据通常涉及以下几个步骤:
1. 确定查询目标:首先明确你想要查询的具体数据类型、数据源、数据量以及查询的目的。
2. 选择合适的工具或平台:根据数据的特点和查询需求,选择适合的大数据查询工具或平台。常见的工具包括Hadoop、Spark、Flink等,以及商业化的数据分析平台如Tableau、Power BI等。
3. 数据预处理:在查询之前,可能需要对数据进行清洗、转换、集成等预处理工作,以确保数据的准确性和一致性。
4. 构建查询语句:使用SQL、HiveQL、SparkSQL等查询语言构建查询语句。这些语言允许你以类似SQL的方式对大数据进行查询。
5. 执行查询:在选定的工具或平台上执行查询语句,并等待查询结果。
6. 结果分析和展示:对查询结果进行分析,并根据需要以图表、报告等形式展示结果。
7. 优化查询:根据查询性能和结果质量,对查询语句和数据处理流程进行优化。
8. 安全性和合规性:确保查询过程符合相关的数据安全法规和公司政策。
9. 文档和记录:记录查询过程和结果,以便于后续的审计和问题追踪。
10. 持续学习和改进:随着大数据技术的不断发展和数据量的增加,持续学习和改进查询技能和方法。
在查询大数据时,还需要考虑数据的分布、存储方式、计算资源等因素,以确保查询的效率和准确性。同时,也要注意保护数据隐私和安全,遵守相关的法律法规。
大数据查询入门指南
随着大数据时代的到来,如何高效地查询和分析海量数据成为了一个关键问题。本文将为您介绍大数据查询的基本概念、常用工具以及一些实用的查询技巧。
在开始查询大数据之前,我们需要了解一些基本概念。
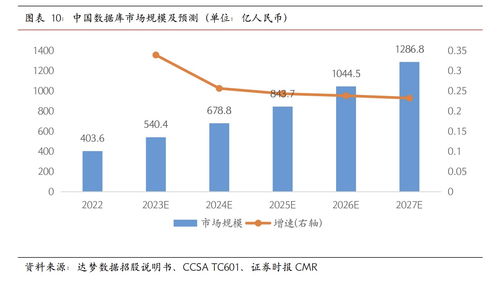
数据量:大数据通常指的是规模庞大的数据集,其数据量可能达到PB(Petabyte,百万亿字节)级别。
数据多样性:大数据不仅包括结构化数据,还包括半结构化数据和非结构化数据。
数据速度:大数据处理需要快速响应,以满足实时分析的需求。
Hadoop:Hadoop是一个开源的分布式计算框架,它支持对大规模数据集的处理。
Hive:Hive是基于Hadoop的数据仓库工具,它允许用户使用类似SQL的查询语言(HiveQL)来查询数据。
Spark:Spark是一个快速、通用的大数据处理引擎,它支持多种数据源和计算模式。
Impala:Impala是一个开源的、高性能的大数据查询引擎,它可以直接在Hadoop文件系统上执行SQL查询。
创建表:使用CREATE TABLE语句创建表,并定义列和数据类型。
数据导入:使用LOAD DATA INPATH语句将数据导入到Hive表中。
查询数据:使用SELECT语句查询数据,包括过滤、排序、聚合等操作。
使用窗口函数:窗口函数可以在查询结果集的基础上进行计算,并为每一行数据返回一个结果。
使用CTE(公用表表达式):CTE可以简化查询逻辑,并提高查询的可读性。
使用子查询:子查询可以嵌套在其他查询中,用于过滤或计算数据。
使用连接查询:连接查询可以将多个表中的数据合并在一起,以便进行更复杂的分析。
使用聚合函数:聚合函数可以对查询结果集中的数据进行聚合操作,例如SUM、AVG、MAX、MIN等。
数据分区:数据分区可以将数据分散到不同的分区中,以提高查询性能。
在处理大数据查询时,了解数据血缘追踪也非常重要。
数据血缘:数据血缘是指数据从产生到最终消亡整个过程中,数据的起源、转换、流转等关系。
数据血缘追踪:数据血缘追踪是一种技术和方法,用于追溯数据的来源、跟踪数据在系统中的流动路径以及在每个处理步骤中的变化情况。
大数据查询是一个复杂的过程,需要掌握一定的技术和技巧。通过本文的介绍,相信您已经对大数据查询有了基本的了解。在实际应用中,不断学习和实践,才能更好地应对大数据查询的挑战。