向量数据库(Vector Database)是一种专门用于存储和检索向量数据的数据库。向量数据通常指的是多维空间中的点,这些点可以表示各种类型的数据,如文本、图像、音频等。向量数据库允许用户通过相似度查询来检索数据,这对于许多机器学习应用来说是非常重要的。
在向量数据库中,向量通常被存储为高维空间中的点,每个维度代表一个特征。这些向量可以用于各种机器学习任务,如聚类、分类、异常检测等。
以下是一个简单的向量数据库的概念代码示例,使用Python和SQLite来实现:
```pythonimport sqlite3import numpy as np
创建数据库连接conn = sqlite3.connectcursor = conn.cursor
创建向量表cursor.execute'''qwe2
插入向量数据def insert_vector: vector_bytes = np.array.tobytes cursor.execute VALUES ', qwe2 conn.commit
检索最相似的向量def retrieve_most_similar: vector_bytes = np.array.tobytes cursor.execute vectors = cursor.fetchall distances = , dtype=np.float32qwe2 vectorqwe2 for v in vectorsqwe2 closest_indices = np.argsort return for i in closest_indicesqwe2
示例使用vectors = , np.random.rand, np.random.randqwe2
for v in vectors: insert_vector
most_similar = retrieve_most_similarqwe2print```
这个代码示例创建了一个简单的向量数据库,其中包括插入向量和检索最相似向量的功能。在这个例子中,我们使用SQLite作为数据库后端,并使用numpy来处理向量数据。这个示例只是一个概念验证,实际应用中可能需要更复杂的查询和索引策略来提高性能。
向量数据库概念与代码实践
随着大数据和人工智能技术的快速发展,向量数据库作为一种新型的数据库技术,逐渐受到广泛关注。向量数据库能够高效地存储、检索和处理高维向量数据,广泛应用于推荐系统、图像识别、自然语言处理等领域。本文将介绍向量数据库的基本概念,并通过实际代码示例展示如何使用向量数据库进行数据存储和检索。
向量数据库的定义

向量数据库是一种专门用于存储和检索高维向量数据的数据库。与传统的关系型数据库不同,向量数据库以向量作为数据的基本存储单位,通过向量空间模型进行数据检索。向量数据库通常具有以下特点:
- 高维数据存储:能够存储和处理高维向量数据,如文本、图像、音频等。
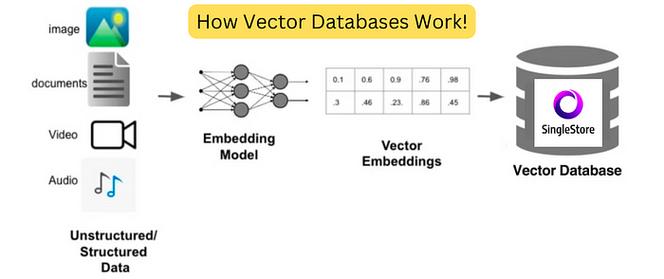
- 相似性搜索:支持向量之间的相似性搜索,如最近邻搜索(Nearest Neighbor Search,简称NN)。
- 高效索引:采用高效的索引结构,如倒排索引、HNSW等,以实现快速检索。
向量数据库的应用场景
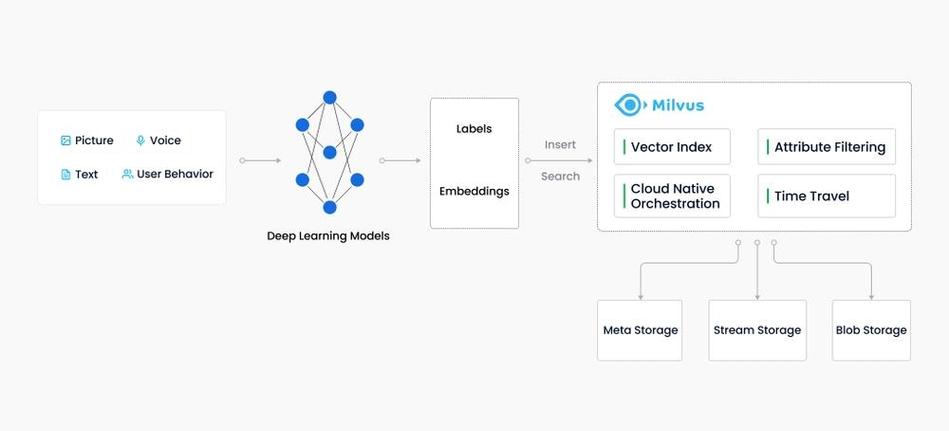
- 推荐系统:用于相似商品推荐、电影推荐等。
- 图像识别:用于人脸识别、物体识别等。
- 自然语言处理:用于文本相似度比较、情感分析等。

- 生物信息学:用于基因序列相似性搜索等。
向量数据库的常见类型

目前市场上常见的向量数据库包括以下几种:
- Milvus:由Zilliz公司开发,支持多种索引结构和查询语言。
- Faiss:由Facebook AI Research开发,适用于大规模向量数据的相似性搜索和聚类。
- Elasticsearch:虽然不是专门的向量数据库,但通过插件支持向量搜索。
向量数据库的代码实践
以下是一个使用Milvus向量数据库进行数据存储和检索的简单示例:
安装Milvus
首先,您需要安装Milvus向量数据库。以下是使用Docker安装Milvus的命令:
```bash
docker pull zilliz/milvus:latest
docker run -d --name milvus -p 19530:19530 zilliz/milvus:latest
创建Collection
在Milvus中,首先需要创建一个Collection来存储向量数据。以下是一个创建Collection的Python代码示例:
```python
from pymilvus import connections, Collection, FieldSchema, DataType
连接到Milvus服务器
connections.connect(\