
机器学习数据预测是一种利用历史数据来预测未来趋势或事件的技术。它通过从大量数据中学习规律和模式,来建立数学模型,并使用这些模型来预测未来的数据点。
在机器学习数据预测中,通常需要以下几个步骤:
1. 数据收集:收集与预测目标相关的历史数据。
2. 数据预处理:对收集到的数据进行清洗、转换和归一化等操作,以提高数据的质量和可用性。
3. 特征工程:从原始数据中提取有用的特征,以供模型训练使用。
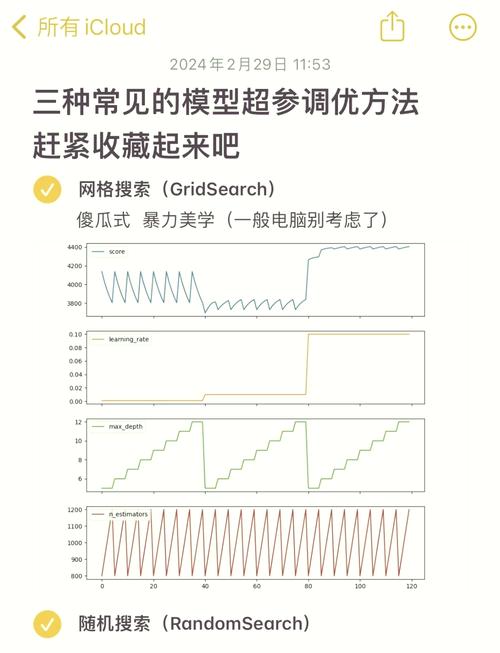
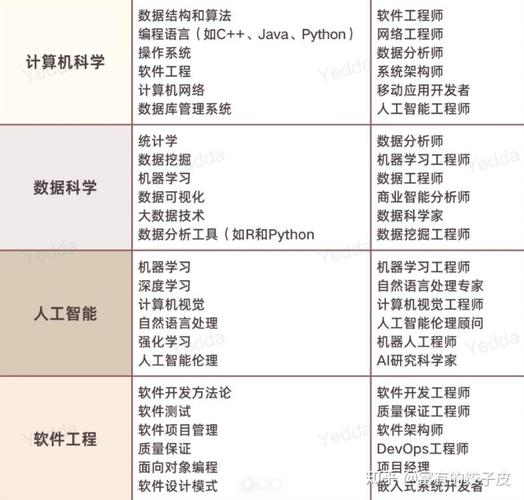
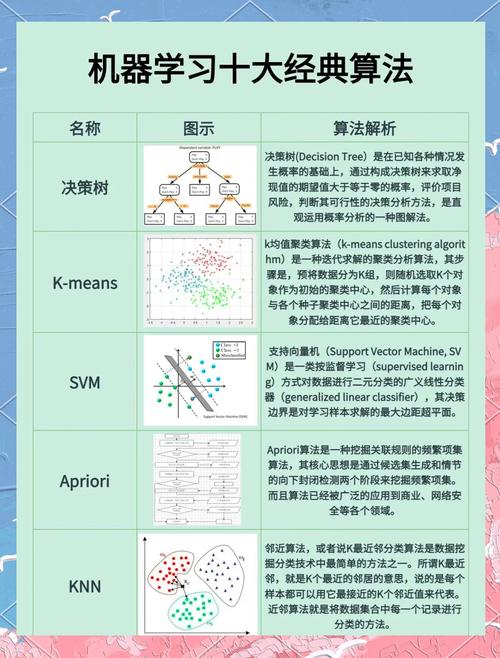
4. 模型选择:选择适合的机器学习算法来建立预测模型,如线性回归、决策树、随机森林、支持向量机等。
5. 模型训练:使用训练数据来训练预测模型,调整模型的参数以优化其性能。
6. 模型评估:使用验证数据来评估模型的性能,如准确率、召回率、F1分数等指标。
7. 模型部署:将训练好的模型部署到实际应用中,进行实时或离线的预测。
8. 模型维护:定期更新模型,以适应数据的变化和预测目标的更新。
机器学习数据预测在许多领域都有广泛的应用,如金融预测、股票市场分析、天气预报、疾病预测等。通过利用历史数据来预测未来,可以帮助企业和个人做出更明智的决策。
机器学习数据预测:揭秘未来趋势的利器
随着信息技术的飞速发展,大数据时代已经来临。在这个时代,数据成为了企业、政府乃至个人决策的重要依据。而机器学习作为一种强大的数据分析工具,正逐渐成为预测未来趋势的利器。本文将深入探讨机器学习数据预测的原理、应用以及面临的挑战。
一、机器学习数据预测的原理
机器学习数据预测是基于历史数据,通过算法模型对未知数据进行预测的一种方法。其核心思想是让计算机从数据中学习规律,从而实现对未来趋势的预测。以下是机器学习数据预测的基本原理:
数据采集:收集与预测目标相关的历史数据。
数据预处理:对采集到的数据进行清洗、转换等操作,提高数据质量。
特征工程:从原始数据中提取对预测目标有重要影响的特征。
模型选择:根据预测任务选择合适的机器学习算法。
模型训练:使用历史数据对模型进行训练,使其学会预测规律。
模型评估:使用测试数据对模型进行评估,调整模型参数。
预测:使用训练好的模型对未知数据进行预测。
二、机器学习数据预测的应用
金融领域:预测股票价格、汇率走势、信用风险等。
医疗领域:预测疾病发生、患者预后、药物效果等。
电商领域:预测商品销量、用户行为、推荐系统等。
交通领域:预测交通流量、事故发生概率、出行路线等。
能源领域:预测能源消耗、设备故障、发电量等。
三、机器学习数据预测面临的挑战
尽管机器学习数据预测在各个领域取得了显著成果,但仍面临以下挑战:
数据质量:数据质量直接影响预测结果的准确性,因此需要保证数据的质量。
特征选择:特征选择对预测结果至关重要,但如何选择合适的特征仍是一个难题。
模型选择:不同的预测任务需要选择不同的机器学习算法,如何选择合适的算法是一个挑战。
过拟合:过拟合是指模型在训练数据上表现良好,但在测试数据上表现不佳,如何避免过拟合是一个关键问题。
可解释性:机器学习模型往往缺乏可解释性,如何提高模型的可解释性是一个挑战。
机器学习数据预测作为一种强大的数据分析工具,在各个领域都取得了显著成果。要充分发挥其潜力,还需要克服数据质量、特征选择、模型选择等挑战。随着技术的不断发展,相信机器学习数据预测将在未来发挥更加重要的作用。








