HTML文件下载主要有以下几种方法:
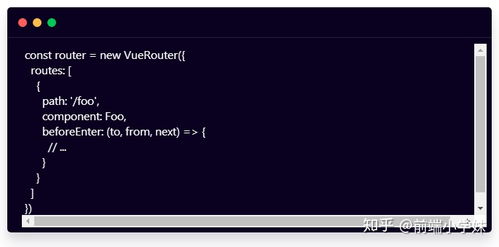
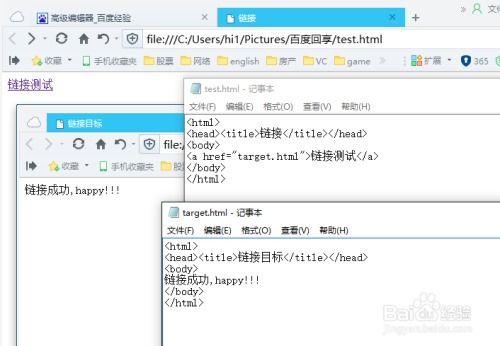
`href`属性:指定文件路径,可以是相对路径或绝对路径。 `download`属性:指定下载时文件的名称。如果省略,会使用文件的默认名称。 示例: ```html 点击此处下载文件 ``` 当用户点击该链接时,浏览器会下载文件名为`myfile.pdf`的PDF文件。
示例: ```javascript var a = document.createElement; a.href = URL.createObjectURL, {type: 'application/pdf'}qwe2qwe2; a.download = 'downloadedFile.pdf'; a.click; ``` 该代码会创建一个临时的下载链接,点击后会下载一个PDF文件。
3. 使用Blob对象和FileSaver.js库Blob对象和FileSaver.js库可以用来实现更复杂的文件下载功能。
示例: ```javascript var file = new Blob, {type: 'application/pdf'}qwe2; saveAs; ``` `saveAs`函数来自FileSaver.js库,可以下载各种类型的文件。
4. 使用URL.createObjectURL通过`URL.createObjectURL`方法可以创建一个临时的URL,用于下载文件。
示例: ```javascript var url = URL.createObjectURL, {type: 'application/pdf'}qwe2qwe2; var a = document.createElement; a.href = url; a.download = 'downloadedFile.pdf'; document.body.appendChild; a.click; document.body.removeChild; URL.revokeObjectURL; ``` 创建一个临时的下载链接,点击后会下载一个PDF文件,然后清理创建的URL。
5. 使用Fetch API下载Blob文件Fetch API可以用来下载文件,并将其转换为Blob对象,再进行下载。
示例: ```javascript fetch .thenqwe2 .then; var a = document.createElement; a.href = url; a.download = 'downloadedFile.pdf'; document.body.appendChild; a.click; document.body.removeChild; URL.revokeObjectURL; }qwe2; ``` 使用Fetch API获取文件,然后创建一个临时的下载链接,点击后会下载一个PDF文件。
6. 使用iframe触发下载通过创建一个隐藏的iframe,可以触发文件的下载。
示例: ```javascript var iframe = document.createElement; iframe.style.display = 'none'; iframe.src = 'path/to/file.pdf'; document.body.appendChild; ``` 创建一个隐藏的iframe,设置其`src`属性为文件路径,从而触发下载。
7. 使用XMLHttpRequest下载Blob文件XMLHttpRequest可以用来下载文件,并将其转换为Blob对象,再进行下载。
示例: ```javascript var xhr = new XMLHttpRequest; xhr.open; xhr.responseType = 'blob'; xhr.onload = function { if { var blob = this.response; var url = URL.createObjectURL; var a = document.createElement; a.href = url; a.download = 'downloadedFile.pdf'; document.body.appendChild; a.click; document.body.removeChild; URL.revokeObjectURL; } }; xhr.send; ``` 使用XMLHttpRequest获取文件,然后创建一个临时的下载链接,点击后会下载一个PDF文件。
8. 使用表单提交通过表单提交可以触发文件的下载。
示例: ```html ``` 表单提交后,服务器会处理下载请求。
这些方法适用于不同的场景和需求,可以根据具体情况进行选择和使用。
HTML文件下载详解
在互联网的世界中,文件下载是一个常见的操作。无论是用户下载软件、文档还是图片,HTML都为我们提供了丰富的下载功能。本文将详细介绍HTML文件下载的相关知识,包括下载原理、实现方法以及注意事项。
一、下载原理
1.1 文件类型判断
浏览器会根据文件的扩展名来判断文件类型。例如,`.txt`文件通常会被认为是纯文本文件,`.jpg`文件会被认为是图片文件。不同的文件类型,浏览器会有不同的处理方式。
1.2 下载与打开
当用户点击一个带有`href`属性的链接时,浏览器会根据以下规则决定是下载文件还是打开文件:
- 如果文件类型是浏览器支持直接打开的类型(如`.txt`、`.jpg`等),浏览器会尝试打开文件。
- 如果文件类型不是浏览器支持直接打开的类型,或者用户在下载对话框中选择“保存文件”,浏览器会启动下载过程。
二、实现方法

这是最简单也是最常用的下载方法。以下是一个简单的示例:
```html