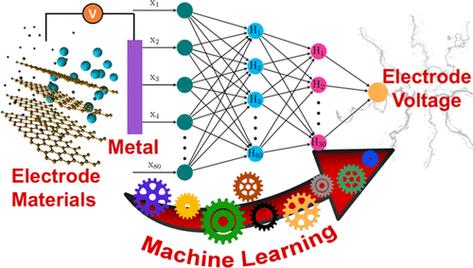
机器学习模型通常包括以下几个步骤来运行:
1. 数据准备:首先需要收集和准备数据,这包括数据清洗、数据转换和数据归一化等。数据质量对模型的性能至关重要。
2. 选择模型:根据问题的类型(如分类、回归、聚类等)选择合适的机器学习算法。常用的算法包括线性回归、决策树、支持向量机、神经网络等。
3. 训练模型:使用准备好的数据来训练模型。训练过程涉及调整模型的参数,使其能够从数据中学习并做出准确的预测。
4. 评估模型:在训练完成后,使用测试数据集来评估模型的性能。这可以通过计算准确率、召回率、F1分数等指标来完成。
5. 调整模型:根据评估结果,可能需要对模型进行进一步的调整,如调整参数、增加或减少特征等,以提高模型的性能。
6. 部署模型:一旦模型达到满意的性能,就可以将其部署到生产环境中,用于实际的数据分析和预测。
7. 监控和维护:模型部署后,需要定期监控其性能,并根据需要进行维护和更新,以确保其持续有效。
请注意,这只是一个大致的框架,具体的步骤可能会因问题的性质、数据的特点和所使用的工具而有所不同。
机器学习模型运行全攻略:从搭建到优化
一、环境搭建

在运行机器学习模型之前,首先需要搭建一个合适的环境。以下是搭建环境的基本步骤:
选择合适的操作系统:Windows、Linux或macOS均可,但Linux系统在运行深度学习模型时性能更佳。
安装Python:Python是机器学习的主要编程语言,需要安装Python解释器和pip包管理器。
安装必要的库:根据所使用的机器学习框架(如TensorFlow、PyTorch等),安装相应的库和依赖项。
配置GPU支持:如果使用GPU加速,需要安装CUDA和cuDNN等驱动程序。
二、数据准备
数据是机器学习模型的基础,准备高质量的数据对于模型的性能至关重要。以下是数据准备的基本步骤:
数据收集:根据模型需求,从各种渠道收集数据,如公开数据集、数据库或传感器数据。
数据清洗:对收集到的数据进行清洗,去除噪声、缺失值和异常值。
数据预处理:对数据进行标准化、归一化等处理,以便模型更好地学习。
数据划分:将数据划分为训练集、验证集和测试集,用于模型训练、验证和评估。
三、模型训练
在数据准备完成后,接下来就是模型训练环节。以下是模型训练的基本步骤:
选择模型架构:根据问题类型和数据特点,选择合适的模型架构,如神经网络、决策树等。
配置模型参数:设置模型的超参数,如学习率、批大小、迭代次数等。
训练模型:使用训练集对模型进行训练,不断调整模型参数以优化性能。
验证模型:使用验证集评估模型性能,调整超参数以防止过拟合。
四、模型评估
模型训练完成后,需要对其性能进行评估。以下是模型评估的基本步骤:
选择评估指标:根据问题类型和数据特点,选择合适的评估指标,如准确率、召回率、F1值等。
计算评估指标:使用测试集计算模型的评估指标,以评估模型性能。
分析结果:分析评估指标,了解模型的优缺点,为后续优化提供依据。
五、模型优化

在评估模型性能后,如果发现模型存在不足,需要进行优化。以下是模型优化的基本步骤:
调整模型架构:尝试不同的模型架构,以寻找更适合问题的模型。
调整超参数:调整模型的超参数,如学习率、批大小、迭代次数等,以优化模型性能。
数据增强:对训练数据进行增强,提高模型的泛化能力。
交叉验证:使用交叉验证方法,进一步评估模型性能。
运行一个机器学习模型需要经历多个步骤,包括环境搭建、数据准备、模型训练、评估和优化。通过本文的介绍,相信读者已经对机器学习模型的运行过程有了基本的了解。在实际应用中,不断优化和调整模型,以提高其性能和泛化能力。