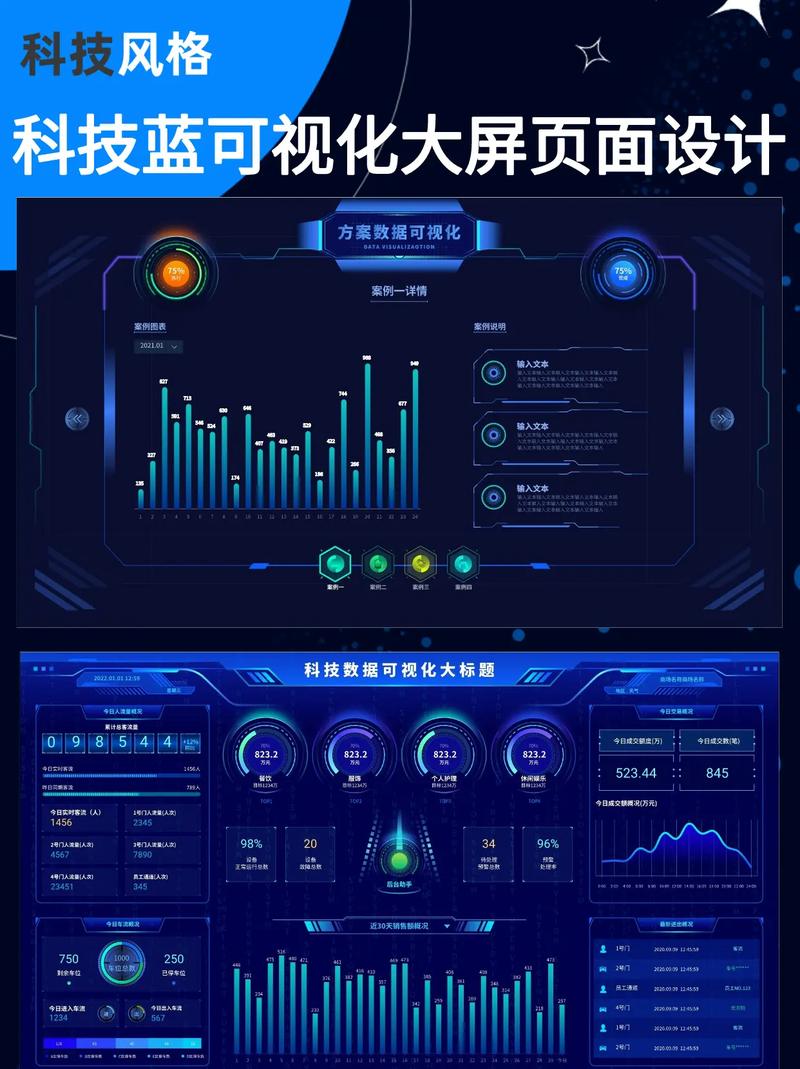
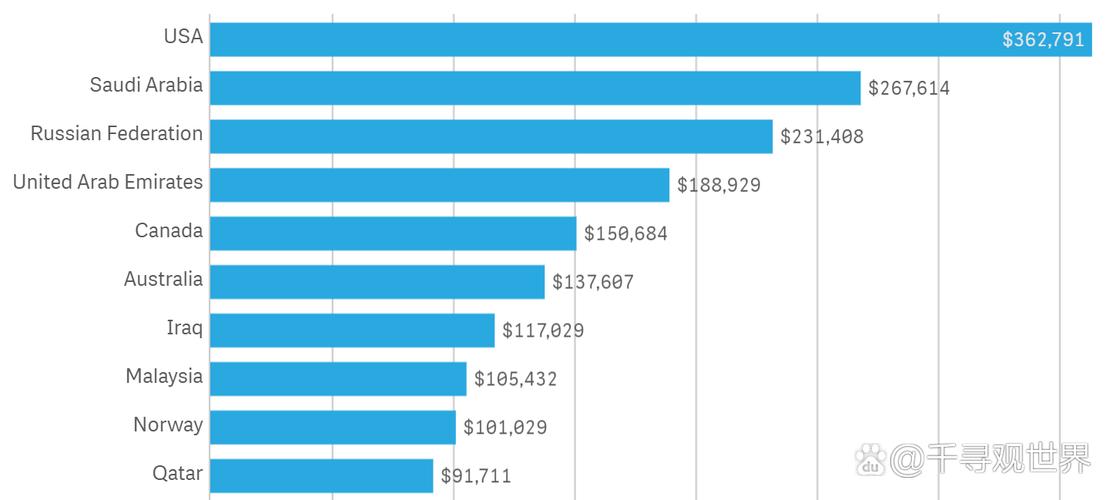
1. 数据采集:从各种来源收集数据,包括传感器、社交媒体、交易记录等。2. 数据存储:使用大规模的存储系统,如分布式文件系统(如Hadoop的HDFS)或云存储服务,来存储大量的数据。3. 数据处理:使用分布式计算框架(如Hadoop的MapReduce、Spark等)来处理和分析数据。4. 数据分析和挖掘:利用统计、机器学习等技术,从数据中提取模式和洞察。5. 数据可视化:将分析结果以图表、报告等形式展示出来,帮助用户理解数据。6. 数据安全和隐私:确保数据的安全性和用户的隐私。
大数据后台通常用于支持商业智能、客户关系管理、风险管理和许多其他需要大量数据处理的领域。随着技术的进步,大数据后台系统也在不断发展和完善,以应对不断增长的数据量和复杂性。
大数据后台:揭秘企业数据驱动的核心力量

在当今这个数据爆炸的时代,大数据已经成为企业竞争的重要武器。大数据后台作为企业数据驱动的核心力量,承载着数据收集、存储、处理和分析的重要任务。本文将深入探讨大数据后台的作用、架构以及如何实现高效的数据驱动决策。
一、大数据后台的作用

1. 数据收集:大数据后台负责从各种数据源(如数据库、日志文件、传感器等)收集数据,确保数据的全面性和实时性。
2. 数据存储:通过分布式存储技术,大数据后台能够存储海量数据,保证数据的安全性和可靠性。
3. 数据处理:大数据后台采用高效的数据处理算法,对数据进行清洗、转换和整合,为后续分析提供高质量的数据。
4. 数据分析:通过数据挖掘、机器学习等技术,大数据后台能够从海量数据中提取有价值的信息,为企业决策提供支持。
5. 数据可视化:大数据后台将分析结果以图表、报表等形式展示,便于用户直观地了解数据背后的规律。
二、大数据后台的架构

1. 数据采集层:负责从各种数据源收集原始数据,如日志、传感器数据、网络数据等。
2. 数据存储层:采用分布式存储技术,如Hadoop、Spark等,实现海量数据的存储和管理。
3. 数据处理层:通过MapReduce、Spark等计算框架,对数据进行清洗、转换和整合。
4. 数据分析层:运用数据挖掘、机器学习等技术,对数据进行深度分析,提取有价值的信息。
5. 数据可视化层:将分析结果以图表、报表等形式展示,便于用户直观地了解数据。
三、大数据后台的实现
1. 技术选型:根据企业需求,选择合适的大数据技术栈,如Hadoop、Spark、Flink等。
2. 数据采集:采用Flume、Kafka等工具,实现数据的实时采集和传输。
3. 数据存储:利用HDFS、Cassandra等分布式存储技术,实现海量数据的存储。
4. 数据处理:运用Spark、Flink等计算框架,对数据进行高效处理。
5. 数据分析:采用Python、R等编程语言,结合数据挖掘、机器学习等技术,进行深度分析。
6. 数据可视化:利用ECharts、Tableau等工具,将分析结果以图表、报表等形式展示。
四、大数据后台的优势
1. 提高决策效率:通过大数据后台,企业能够快速获取有价值的信息,提高决策效率。
2. 降低运营成本:大数据后台能够帮助企业优化资源配置,降低运营成本。
3. 提升用户体验:通过分析用户行为数据,企业能够更好地了解用户需求,提升用户体验。
4. 增强竞争力:大数据后台为企业提供数据驱动的决策支持,增强企业在市场竞争中的优势。
大数据后台作为企业数据驱动的核心力量,在当今这个数据爆炸的时代,发挥着越来越重要的作用。通过深入了解大数据后台的作用、架构和实现方法,企业能够更好地利用大数据技术,实现数据驱动决策,提升企业竞争力。