机器学习预测模型是一种利用历史数据来预测未来趋势或事件的技术。以下是几种常见的机器学习预测模型:
1. 线性回归:线性回归是一种最简单的机器学习预测模型,它通过寻找一条直线来最小化预测值与实际值之间的差异。线性回归适用于预测具有线性关系的变量。
2. 决策树:决策树是一种基于树形结构的预测模型,它通过一系列规则将数据划分为不同的类别。决策树适用于分类和回归问题。
3. 随机森林:随机森林是一种集成学习方法,它结合了多个决策树来提高预测准确性。随机森林适用于分类和回归问题。
4. 支持向量机(SVM):支持向量机是一种基于核函数的预测模型,它通过寻找一个超平面来最大程度地分离不同类别的数据点。支持向量机适用于分类和回归问题。
5. 神经网络:神经网络是一种模拟人脑神经元结构的预测模型,它通过多层神经元之间的连接来学习和预测数据。神经网络适用于复杂的非线性问题。
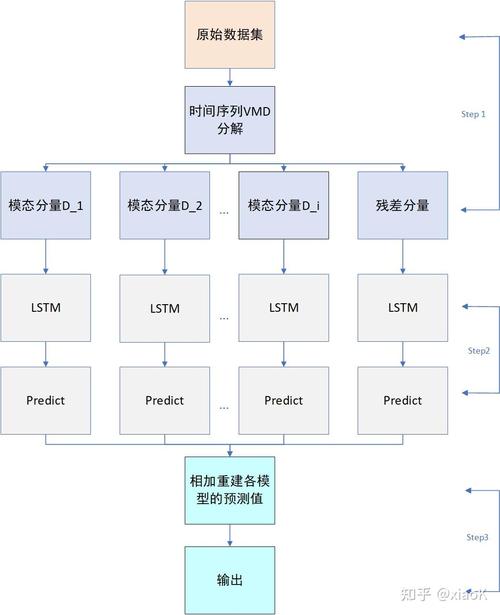
6. 时间序列分析:时间序列分析是一种专门用于处理时间序列数据的预测模型,它通过分析历史时间序列数据来预测未来的趋势。时间序列分析适用于预测具有时间依赖性的变量。
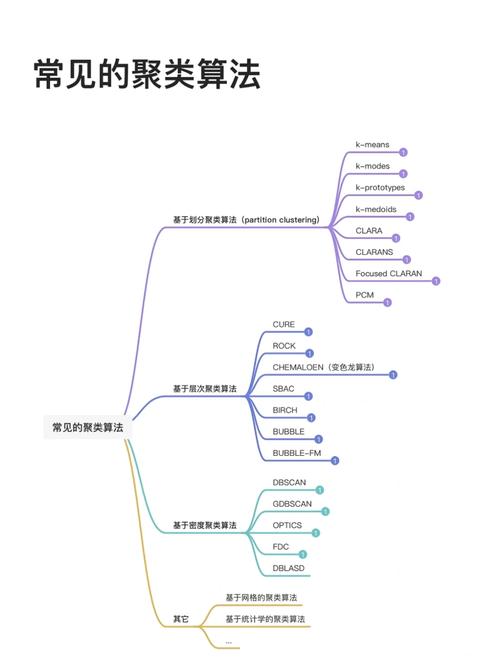
7. 聚类分析:聚类分析是一种无监督学习算法,它将数据点分为不同的簇。聚类分析可以用于预测数据点的相似性或分组。
8. 关联规则挖掘:关联规则挖掘是一种用于发现数据中频繁出现的关系的预测模型。关联规则挖掘可以用于预测商品之间的购买关系。
这些只是机器学习预测模型中的一部分,还有许多其他的模型和算法可以用于预测不同的数据类型和问题。选择合适的模型取决于数据的性质、问题的复杂性和预测的准确性要求。
机器学习预测模型:揭秘未来趋势的利器
随着大数据时代的到来,机器学习(Machine Learning,ML)技术逐渐成为各行各业关注的焦点。机器学习预测模型作为一种强大的数据分析工具,能够帮助我们预测未来趋势,为决策提供有力支持。本文将深入探讨机器学习预测模型的基本原理、应用领域以及未来发展趋势。
一、机器学习预测模型的基本原理
机器学习预测模型是基于数据驱动的方法,通过分析历史数据,建立数学模型,从而预测未来趋势。其基本原理如下:
数据收集:从各种渠道收集相关数据,如历史销售数据、用户行为数据等。
数据预处理:对收集到的数据进行清洗、转换和归一化等操作,提高数据质量。
特征工程:从原始数据中提取有价值的信息,形成特征向量。
模型选择:根据预测任务选择合适的机器学习算法,如线性回归、决策树、支持向量机等。
模型训练:使用历史数据对模型进行训练,使模型学会从数据中提取规律。
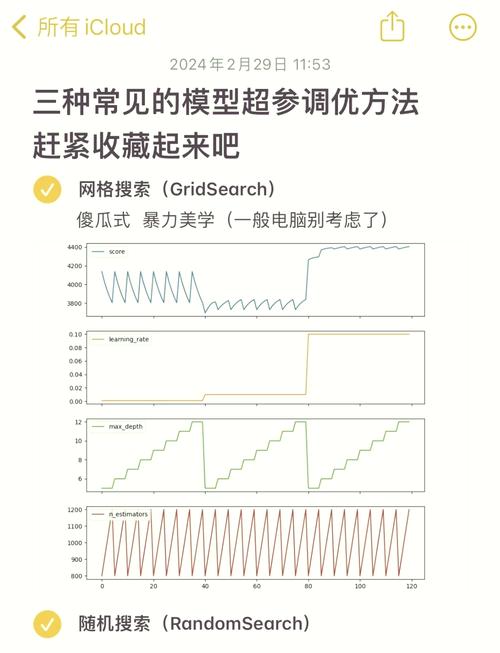
模型评估:使用测试数据对模型进行评估,调整模型参数,提高预测精度。
预测:使用训练好的模型对未知数据进行预测,得出未来趋势。
二、机器学习预测模型的应用领域
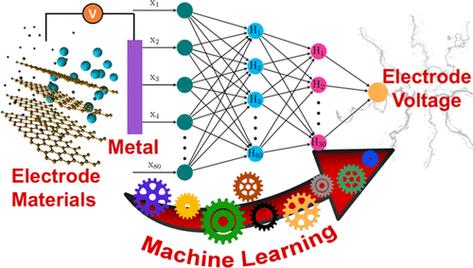
机器学习预测模型在各个领域都有广泛的应用,以下列举几个典型应用场景:
金融领域:预测股票价格、风险评估、信用评分等。
医疗领域:疾病预测、药物研发、患者预后等。
零售领域:销售预测、库存管理、客户细分等。
交通领域:交通流量预测、交通事故预测、智能交通管理等。
能源领域:电力需求预测、能源消耗预测、可再生能源优化等。
三、机器学习预测模型的发展趋势
深度学习:深度学习在图像识别、语音识别等领域取得了显著成果,未来有望在预测模型中得到更广泛的应用。
迁移学习:迁移学习能够将已有模型的知识迁移到新任务上,提高模型训练效率。
联邦学习:联邦学习能够在保护用户隐私的前提下,实现大规模数据共享和模型训练。
可解释性:提高预测模型的可解释性,使决策者能够理解模型的预测依据。
机器学习预测模型作为一种强大的数据分析工具,在各个领域都发挥着重要作用。随着技术的不断发展,机器学习预测模型将更加智能化、高效化,为人类生活带来更多便利。了解机器学习预测模型的基本原理、应用领域和发展趋势,有助于我们更好地把握未来趋势,为决策提供有力支持。