
“深入浅出机器学习”是一个比较宽泛的概念,它涉及到如何以简单易懂的方式介绍机器学习的基础知识和原理,同时也可能涉及到如何通过实际案例来深入理解机器学习的高级应用。
1. 机器学习的基本概念:包括监督学习、无监督学习、强化学习等基本概念,以及它们之间的区别和联系。
2. 常用的机器学习算法:如线性回归、决策树、支持向量机、神经网络等,以及这些算法的基本原理和应用场景。
3. 机器学习的应用案例:通过具体的案例,如图像识别、自然语言处理、推荐系统等,来展示机器学习在实际问题中的应用。
4. 机器学习的挑战和未来方向:包括数据隐私、模型可解释性、模型泛化能力等挑战,以及机器学习在未来的可能发展方向。
5. 实践指南:如何选择合适的机器学习算法,如何处理数据,如何评估模型的性能等。
6. 学习资源:推荐一些学习机器学习的书籍、课程、博客等资源。
7. 行业应用:机器学习在各个行业中的应用,如医疗、金融、交通、零售等。
8. 伦理和社会影响:机器学习对伦理和社会的影响,如算法偏见、就业影响等。
9. 与深度学习的联系:深度学习是机器学习的一个分支,了解深度学习的基本概念和与机器学习的关系。
10. 最新的研究进展:介绍机器学习领域的一些最新研究成果和技术进展。
以上内容可以根据你的具体需求进行调整和补充。如果你有特定的学习目标或兴趣点,可以进一步细化这些内容。
什么是机器学习?

机器学习(Machine Learning)是人工智能(Artificial Intelligence,AI)的一个子领域,它使计算机系统能够从数据中学习并做出决策或预测,而无需显式编程。简单来说,机器学习就是让计算机通过经验改进其性能的过程。
机器学习的基本概念
在深入探讨机器学习之前,我们需要了解一些基本概念:
数据(Data):机器学习的基础是数据,它可以是文本、图像、声音或其他形式。
特征(Features):数据中的特定属性或变量,用于描述数据。
算法(Algorithm):用于训练模型和进行预测的数学方法。
训练(Training):使用数据集对模型进行训练,使其能够学习并改进。
测试(Testing):使用测试数据集评估模型的性能。
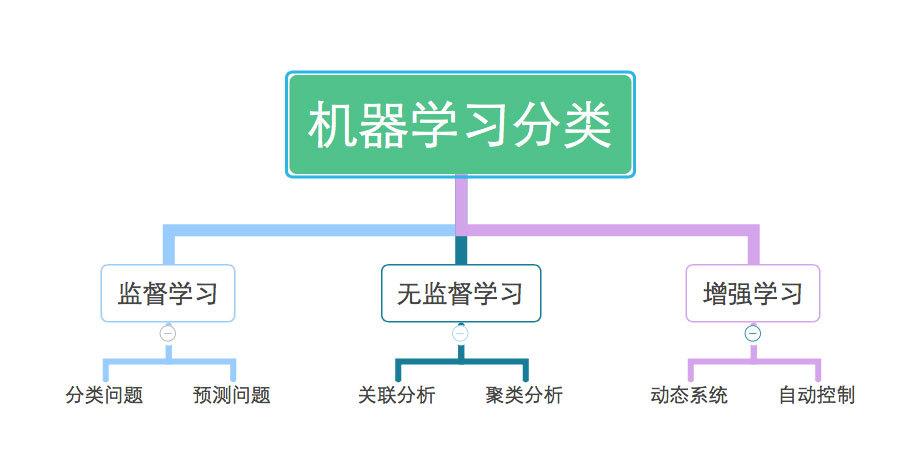
机器学习的类型

根据学习方式和数据类型,机器学习可以分为以下几种类型:
监督学习(Supervised Learning):使用标记数据集进行训练,如分类和回归问题。
无监督学习(Unsupervised Learning):使用未标记数据集进行训练,如聚类和降维问题。
半监督学习(Semi-supervised Learning):结合标记和未标记数据集进行训练。
强化学习(Reinforcement Learning):通过与环境交互进行学习,并基于奖励和惩罚进行决策。
常见的机器学习算法
线性回归(Linear Regression):用于预测连续值。
逻辑回归(Logistic Regression):用于预测离散的二分类结果。
支持向量机(Support Vector Machine,SVM):用于分类和回归问题。
决策树(Decision Tree):用于分类和回归问题,通过树状结构进行决策。
随机森林(Random Forest):集成学习算法,通过构建多个决策树进行预测。
神经网络(Neural Network):模拟人脑神经元连接的算法,用于复杂的数据处理。
机器学习的应用
推荐系统(Recommendation Systems):如Netflix和Amazon的产品推荐。
自然语言处理(Natural Language Processing,NLP):如机器翻译和情感分析。
图像识别(Image Recognition):如人脸识别和物体检测。
医疗诊断(Medical Diagnosis):如疾病预测和患者分类。
金融分析(Financial Analysis):如信用评分和风险控制。
机器学习的挑战
尽管机器学习取得了巨大进步,但仍面临一些挑战:
数据质量:高质量的数据对于训练有效的模型至关重要。
过拟合(Overfitting):模型在训练数据上表现良好,但在新数据上表现不佳。
可解释性(Explainability):理解模型决策背后的原因。
隐私保护(Privacy Protection):确保数据隐私不被侵犯。
机器学习是一个快速发展的领域,它正在改变我们的世界。通过理解其基本概念、类型、算法和应用,我们可以更好地利用机器学习技术解决实际问题。尽管存在挑战,但机器学习的前景仍然非常广阔。







