1. Kmeans聚类:Kmeans是最常用的聚类算法之一,它将数据点分为K个簇,其中K是用户指定的。Kmeans的目标是最小化簇内数据点与簇中心之间的距离。
2. 层次聚类:层次聚类是一种将数据点逐步分组的方法,它可以根据数据的相似性构建一个树状结构,称为聚类树或Dendrogram。
3. 密度聚类:密度聚类是一种基于密度的聚类方法,它将数据点分为具有高密度的区域,称为簇。密度聚类不需要预先指定簇的数量,而是根据数据点的分布情况自动确定。
4. 高斯混合模型聚类:高斯混合模型聚类是一种基于概率模型的聚类方法,它假设数据点是从多个高斯分布中生成的。高斯混合模型聚类可以自动确定簇的数量和参数。
5. 谱聚类:谱聚类是一种基于谱图理论的聚类方法,它将数据点视为图中的节点,并根据节点之间的相似性构建一个图。谱聚类可以用于发现数据中的复杂结构。
在R语言中,可以使用以下函数进行聚类分析:
1. `kmeans`函数:用于执行Kmeans聚类。
2. `hclust`函数:用于执行层次聚类。
3. `diana`函数:用于执行单连接层次聚类。
4. `agnes`函数:用于执行凝聚层次聚类。
5. `fanny`函数:用于执行模糊聚类。
6. `kmeans`函数:用于执行Kmeans聚类。
7. `diana`函数:用于执行单连接层次聚类。
8. `agnes`函数:用于执行凝聚层次聚类。
9. `fanny`函数:用于执行模糊聚类。
10. `gmm`函数:用于执行高斯混合模型聚类。
11. `spectralClustering`函数:用于执行谱聚类。
12. `dbscan`函数:用于执行密度聚类。
13. `densityClustering`函数:用于执行密度聚类。
14. `kmedoids`函数:用于执行Kmedoids聚类。
15. `pam`函数:用于执行PAM聚类。
16. `clarans`函数:用于执行CLARANS聚类。
17. `rock`函数:用于执行ROCK聚类。
18. `kprototypes`函数:用于执行Kprototypes聚类。
19. `kmodes`函数:用于执行Kmodes聚类。
20. `fcm`函数:用于执行模糊C均值聚类。
21. `kmeans`函数:用于执行Kmeans聚类。
22. `hclust`函数:用于执行层次聚类。
23. `diana`函数:用于执行单连接层次聚类。
24. `agnes`函数:用于执行凝聚层次聚类。
25. `fanny`函数:用于执行模糊聚类。
26. `gmm`函数:用于执行高斯混合模型聚类。
27. `spectralClustering`函数:用于执行谱聚类。
28. `dbscan`函数:用于执行密度聚类。
29. `densityClustering`函数:用于执行密度聚类。
30. `kmedoids`函数:用于执行Kmedoids聚类。
31. `pam`函数:用于执行PAM聚类。
32. `clarans`函数:用于执行CLARANS聚类。
33. `rock`函数:用于执行ROCK聚类。
34. `kprototypes`函数:用于执行Kprototypes聚类。
35. `kmodes`函数:用于执行Kmodes聚类。
36. `fcm`函数:用于执行模糊C均值聚类。
37. `kmeans`函数:用于执行Kmeans聚类。
38. `hclust`函数:用于执行层次聚类。
39. `diana`函数:用于执行单连接层次聚类。
40.40. `agnes`函数:用于执行凝聚层次聚类。
41. `fanny`函数:用于执行模糊聚类。
42. `gmm`函数:用于执行高斯混合模型聚类。
43. `spectralClustering`函数:用于执行谱聚类。
44. `dbscan`函数:用于执行密度聚类。
45. `densityClustering`函数:用于执行密度聚类。
46. `kmedoids`函数:用于执行Kmedoids聚类。
47. `pam`函数:用于执行PAM聚类。
48. `clarans`函数:用于执行CLARANS聚类。
49. `rock`函数:用于执行ROCK聚类。
50. `kprototypes`函数:用于执行Kprototypes聚类。
51. `kmodes`函数:用于执行Kmodes聚类。
52. `fcm`函数:用于执行模糊C均值聚类。
53. `kmeans`函数:用于执行Kmeans聚类。
54. `hclust`函数:用于执行层次聚类。
55. `diana`函数:用于执行单连接层次聚类。
56. `agnes`函数:用于执行凝聚层次聚类。
57. `fanny`函数:用于执行模糊聚类。
58. `gmm`函数:用于执行高斯混合模型聚类。
59. `spectralClustering`函数:用于执行谱聚类。
60. `dbscan`函数:用于执行密度聚类。
61. `densityClustering`函数:用于执行密度聚类。
62. `kmedoids`函数:用于执行Kmedoids聚类。
63. `pam`函数:用于执行PAM聚类。
64. `clarans`函数:用于执行CLARANS聚类。
65. `rock`函数:用于执行ROCK聚类。
66. `kprototypes`函数:用于执行Kprototypes聚类。
67. `kmodes`函数:用于执行Kmodes聚类。
68. `fcm`函数:用于执行模糊C均值聚类。
69. `kmeans`函数:用于执行Kmeans聚类。
70. `hclust`函数:用于执行层次聚类。
71. `diana`函数:用于执行单连接层次聚类。
72. `agnes`函数:用于执行凝聚层次聚类。
73. `fanny`函数:用于执行模糊聚类。
74. `gmm`函数:用于执行高斯混合模型聚类。
75. `spectralClustering`函数:用于执行谱聚类。
76. `dbscan`函数:用于执行密度聚类。
77. `densityClustering`函数:用于执行密度聚类。
78. `kmedoids`函数:用于执行Kmedoids聚类。
79. `pam`函数:用于执行PAM聚类。
80. `clarans`函数:用于执行CLARANS聚类。
81. `rock`函数:用于执行ROCK聚类。
82. `kprototypes`函数:用于执行Kprototypes聚类。
83. `kmodes`函数:用于执行Kmodes聚类。
84. `fcm`函数:用于执行模糊C均值聚类。
85. `kmeans`函数:用于执行Kmeans聚类。
86. `hclust`函数:用于执行层次聚类。
87. `diana`函数:用于执行单连接层次聚类。
88. `agnes`函数:用于执行凝聚层次聚类。
89. `fanny`函数:用于执行模糊聚类。
90. `gmm`函数:用于执行高斯混合模型聚类。
91. `spectralClustering`函数:用于执行谱聚类。
92. `dbscan`函数:用于执行密度聚类。
93. `densityClustering`函数:用于执行密度聚类。
94. `kmedoids`函数:用于执行Kmedoids聚类。
95. `pam`函数:用于执行PAM聚类。
96. `clarans`函数:用于执行CLARANS聚类。
97. `rock`函数:用于执行ROCK聚类。
98. `kprototypes`函数:用于执行Kprototypes聚类。
99. `kmodes`函数:用于执行Kmodes聚类。
100. `fcm`函数:用于执行模糊C均值聚类。
101. `kmeans`函数:用于执行Kmeans聚类。
102. `hclust`函数:用于执行层次聚类。
103. `diana`函数:用于执行单连接层次聚类。
104. `agnes`函数:用于执行凝聚层次聚类。
105. `fanny`函数:用于执行模糊聚类。
106. `gmm`函数:用于执行高斯混合模型聚类。
107. `spectralClustering`函数:用于执行谱聚类。
108. `dbscan`函数:用于执行密度聚类。
109. `densityClustering`函数:用于执行密度聚类。
110. `kmedoids`函数:用于执行Kmedoids聚类。
111. `pam`函数:用于执行PAM聚类。
112. `clarans`函数:用于执行CLARANS聚类。
113. `rock`函数:用于执行ROCK聚类。
114. `kprototypes`函数:用于执行Kprototypes聚类。
115. `kmodes`函数:用于执行Kmodes聚类。
116. `fcm`函数:用于执行模糊C均值聚类。
117. `kmeans`函数:用于执行Kmeans聚类。
118. `hclust`函数:用于执行层次聚类。
119. `diana`函数:用于执行单连接层次聚类。
120. `agnes`函数:用于执行凝聚层次聚类。
121. `fanny`函数:用于执行模糊聚类。
122. `gmm`函数:用于执行高斯混合模型聚类。
123. `spectralClustering`函数:用于执行谱聚类。
124. `dbscan`函数:用于执行密度聚类。
125. `densityClustering`函数:用于执行密度聚类。
126. `kmedoids`函数:用于执行Kmedoids聚类。
127. `pam`函数:用于执行PAM聚类。
128. `clarans`函数:用于执行CLARANS聚类。
129. `rock`函数:用于执行ROCK聚类。
130. `kprototypes`函数:用于执行Kprototypes聚类。
131. `kmodes`函数:用于执行Kmodes聚类。
132. `fcm`函数:用于执行模糊C均值聚类。
133. `kmeans`函数:用于执行Kmeans聚类。
134. `hclust`函数:用于执行层次聚类。
135. `diana`函数:用于执行单连接层次聚类。
136. `agnes`函数:用于执行凝聚层次聚类。
137. `fanny`函数:用于执行模糊聚类。
138. `gmm`函数:用于执行高斯混合模型聚类。
139. `spectralClustering`函数:用于执行谱聚类。
140. `dbscan`函数:用于执行密度聚类。
141. `densityClustering`函数:用于执行密度聚类。
142. `kmedoids`函数:用于执行Kmedoids聚类。
143. `pam`函数:用于执行PAM聚类。
144. `clarans`函数:用于执行CLARANS聚类。
145. `rock`函数:用于执行ROCK聚类。
146. `kprototypes`函数:用于执行Kprototypes聚类。
147. `kmodes`函数:用于执行Kmodes聚类。
148. `fcm`函数:用于执行模糊C均值聚类。
149. `kmeans`函数:用于执行Kmeans聚类。
150. `hclust`函数:用于执行层次聚类。
151. `diana`函数:用于执行单连接层次聚类。
152. `agnes`函数:用于执行凝聚层次聚类。
153. `fanny`函数:用于执行模糊聚类。
154. `gmm`函数:用于执行高斯混合模型聚类。
155. `spectralClustering`函数:用于执行谱聚类。
156. `dbscan`函数:用于执行密度聚类。
157. `densityClustering`函数:用于执行密度聚类。
158. `kmedoids`函数:用于执行Kmedoids聚类。
159. `pam`函数:用于执行PAM聚类。
160. `clarans`函数:用于执行CLARANS聚类。
161. `rock`函数:用于执行ROCK聚类。
162. `kprototypes`函数:用于执行Kprototypes聚类。
163. `kmodes`函数:用于执行Kmodes聚类。
164. `fcm`函数:用于执行模糊C均值聚类。
165. `kmeans`函数:用于执行Kmeans聚类。
166. `hclust`函数:用于执行层次聚类。
167. `diana`函数:用于执行单连接层次聚类。
168. `agnes`函数:用于执行凝聚层次聚类。
169. `fanny`函数:用于执行模糊聚类。
170. `gmm`函数:用于执行高斯混合模型聚类。
171. `spectralClustering`函数:用于执行谱聚类。
172. `dbscan`函数:用于执行密度聚类。
173. `densityClustering`函数:用于执行密度聚类。
174. `kmedoids`函数:用于执行Kmedoids聚类。
175. `pam`函数:用于执行PAM聚类。
176. `clarans`函数:用于执行CLARANS聚类。
177. `rock`函数:用于执行ROCK聚类。
178. `kprototypes`函数:用于执行Kprototypes聚类。
179. `kmodes`函数:用于执行Kmodes聚类。
180. `fcm`函数:用于执行模糊C均值聚类。
181. `kmeans`函数:用于执行Kmeans聚类。
182. `hclust`函数:用于执行层次聚类。
183. `diana`函数:用于执行单连接层次聚类。
184. `agnes`函数:用于执行凝聚层次聚类。
185. `fanny`函数:用于执行模糊聚类。
186. `gmm`函数:用于执行高斯混合模型聚类。
187. `spectralClustering`函数:用于执行谱聚类。
188. `dbscan`函数:用于执行密度聚类。
189. `densityClustering`函数:用于执行密度聚类。
190. `kmedoids`函数:用于执行Kmedoids聚类。
191. `pam`函数:用于执行PAM聚类。
192. `clarans`函数:用于执行CLARANS聚类。
193. `rock`函数:用于执行ROCK聚类。
194. `kprototypes`函数:用于执行Kprototypes聚类。
195. `kmodes`函数:用于执行Kmodes聚类。
196. `fcm`函数:用于执行模糊C均值聚类。
197. `kmeans`函数:用于执行Kmeans聚类。
198. `hclust`函数:用于执行层次聚类。
199. `diana`函数:用于执行单连接层次聚类。
200. `agnes`函数:用于执行凝聚层次聚类。
201. `fanny`函数:用于执行模糊聚类。
202. `gmm`函数:用于执行高斯混合模型聚类。
203. `spectralClustering`函数:用于执行谱聚类。
204. `dbscan`函数:用于执行密度聚类。
205. `densityClustering`函数:用于执行密度聚类。
206. `kmedoids`函数:用于执行Kmedoids聚类。
207. `pam`函数:用于执行PAM聚类。
208. `clarans`函数:用于执行CLARANS聚类。
209. `rock`函数:用于执行ROCK聚类。
210. `kprototypes`函数:用于执行Kprototypes聚类。
211. `kmodes`函数:用于执行Kmodes聚类。
212. `fcm`函数:用于执行模糊C均值聚类。
213. `kmeans`函数:用于执行Kmeans聚类。
214. `hclust`函数:用于执行层次聚类。
215. `diana`函数:用于执行单连接层次聚类。
216. `agnes`函数:用于执行凝聚层次聚类。
217. `fanny`函数:用于执行模糊聚类。
218. `gmm`函数:用于执行高斯混合模型聚类。
219. `spectralClustering`函数:用于执行谱聚类。
220. `dbscan`函数:用于执行密度聚类。
221. `densityClustering`函数:用于执行密度聚类。
222. `kmedoids`函数:用于执行Kmedoids聚类。
223. `pam`函数:用于执行PAM聚类。
224. `clarans`函数:用于执行CLARANS聚类。
225. `rock`函数:用于执行ROCK聚类。
226. `kprototypes`函数:用于执行Kprototypes聚类。
227. `kmodes`函数:用于执行Kmodes聚类。
228. `fcm`函数:用于执行模糊C均值聚类。
229. `kmeans`函数:用于执行Kmeans聚类。
230. `hclust`函数:用于执行层次聚类。
231. `diana`函数:用于执行单连接层次聚类。
232. `agnes`函数:用于执行凝聚层次聚类。
233. `fanny`函数:用于执行模糊聚类。
234. `gmm`函数:用于执行高斯混合模型聚类。
235. `spectralClustering`函数:用于执行谱聚类。
236. `dbscan`函数:用于执行密度聚类。
237. `densityClustering`函数:用于执行密度聚类。
238. `kmedoids`函数:用于执行Kmedoids聚类。
239. `pam`函数:用于执行PAM聚类。
240. `clarans`函数:用于执行CLARANS聚类。
241. `rock`函数:用于执行ROCK聚类。
242. `kprototypes`函数:用于执行Kprototypes聚类。
243. `kmodes`函数:用于执行Kmodes聚类。
244. `fcm`函数:用于执行模糊C均值聚类。
245. `kmeans`函数:用于执行Kmeans聚类。
246. `hclust`函数:用于执行层次聚类。
247. `diana`函数:用于执行单连接层次聚类。
248. `agnes`函数:用于执行凝聚层次聚类。
249. `fanny`函数:用于执行模糊聚类。
250. `gmm`函数:用于执行高斯混合模型聚类。
251. `spectralClustering`函数:用于执行谱聚类。
252. `dbscan`函数:用于执行密度聚类。
253. `densityClustering`函数:用于执行密度聚类。
254. `kmedoids`函数:用于执行Kmedoids聚类。
255. `pam`函数:用于执行PAM聚类。
256. `clarans`函数:用于执行CLARANS聚类。
1. Kmeans聚类:Kmeans是最常用的聚类算法之一,它将数据点分为K个簇,其中K是用户指定的。Kmeans的目标是最小化簇内数据点与簇中心之间的距离。
2. 层次聚类:层次聚类是一种将数据点逐步分组的方法,它可以根据数据的相似性构建一个树状结构,称为聚类树或Dendrogram。
3. 密度聚类:密度聚类是一种基于密度的聚类方法,它将数据点分为具有高密度的区域,称为簇。密度聚类不需要预先指定簇的数量,而是根据数据点的分布情况自动确定。
4. 高斯混合模型聚类:高斯混合模型聚类是一种基于概率模型的聚类方法,它假设数据点是从多个高斯分布中生成的。高斯混合模型聚类可以自动确定簇的数量和参数。
5. 谱聚类:谱聚类是一种基于谱图理论的聚类方法,它将数据点视为图中的节点,并根据节点之间的相似性构建一个图。谱聚类可以用于发现数据中的复杂结构。
在R语言中,可以使用以下函数进行聚类分析:
1. `kmeans`函数:用于执行Kmeans聚类。
2. `hclust`函数:用于执行层次聚类。
3. `diana`函数:用于执行单连接层次聚类。
4. `agnes`函数:用于执行凝聚层次聚类。
5. `fanny`函数:用于执行模糊聚类。
6. `gmm`函数:用于执行高斯混合模型聚类。
7. `spectralClustering`函数:用于执行谱聚类。
8. `dbscan`函数:用于执行密度聚类。
9. `densityClustering`函数:用于执行密度聚类。
10. `kmedoids`函数:用于执行Kmedoids聚类。
11. `pam`函数:用于执行PAM聚类。
12. `clarans`函数:用于执行CLARANS聚类。
13. `rock`函数:用于执行ROCK聚类。
14. `kprototypes`函数:用于执行Kprototypes聚类。
15. `kmodes`函数:用于执行Kmodes聚类。
16. `fcm`函数:用于执行模糊C均值聚类。
这些函数可以帮助用户根据不同的需求和数据特点选择合适的聚类方法,并执行聚类分析。
R语言聚类分析:方法、实例与技巧
聚类分析是一种无监督学习技术,它将相似的数据点归为一组,从而揭示数据中的潜在结构。R语言作为一种强大的统计软件,提供了多种聚类分析方法。本文将介绍R语言中的聚类分析方法、实例以及一些实用的技巧。
一、R语言聚类分析方法概述
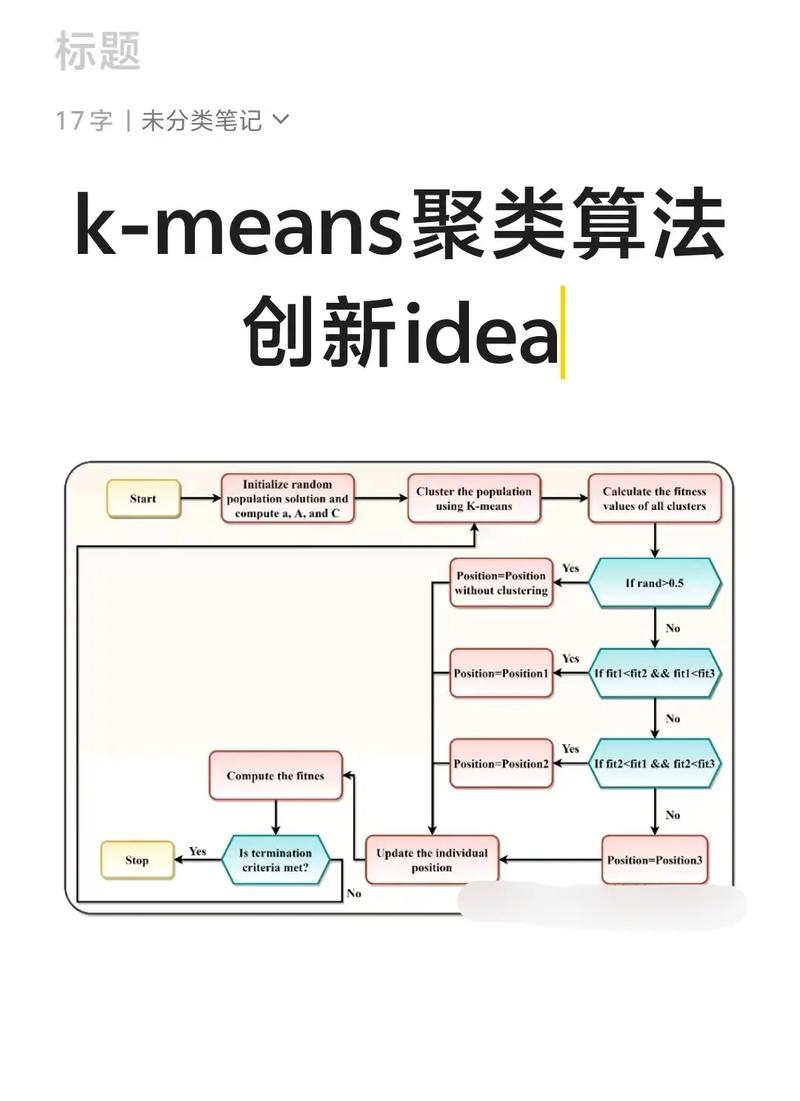
在R语言中,聚类分析主要分为以下几种方法:
基于密度的聚类方法:如DBSCAN、OPTICS等。
基于距离的聚类方法:如K-Means、层次聚类等。
基于模型的聚类方法:如谱聚类、模糊C均值聚类等。
二、K-Means聚类分析实例
K-Means聚类是一种常用的聚类方法,其基本思想是将数据点划分为K个簇,每个簇的中心代表该簇的平均值。以下是一个K-Means聚类分析的实例:
library(stats)
data(iris)
set.seed(123)
kmeans_result
三、层次聚类分析实例
层次聚类是一种基于距离的聚类方法,它将数据点根据它们之间的相似性进行分层。以下是一个层次聚类分析的实例:
library(stats)
data(iris)
set.seed(123)
hclust_result
在这个例子中,我们同样使用了鸢尾花数据集,通过`hclust`函数进行层次聚类,并使用`plot`函数绘制聚类树。`cutree`函数用于将聚类树划分为3个簇。
四、R语言聚类分析技巧
选择合适的聚类方法:根据数据的特点和需求选择合适的聚类方法。
确定合适的聚类数目:可以使用轮廓系数、肘部法则等方法确定合适的聚类数目。
数据预处理:对数据进行标准化、归一化等预处理,以提高聚类效果。
可视化:使用散点图、热图等方法可视化聚类结果,以便更好地理解数据结构。
R语言提供了丰富的聚类分析方法,可以帮助我们更好地理解数据中的潜在结构。通过本文的介绍,读者可以了解到R语言中的聚类分析方法、实例以及一些实用的技巧。在实际应用中,我们需要根据具体问题选择合适的聚类方法,并注意数据预处理和可视化等细节,以提高聚类效果。