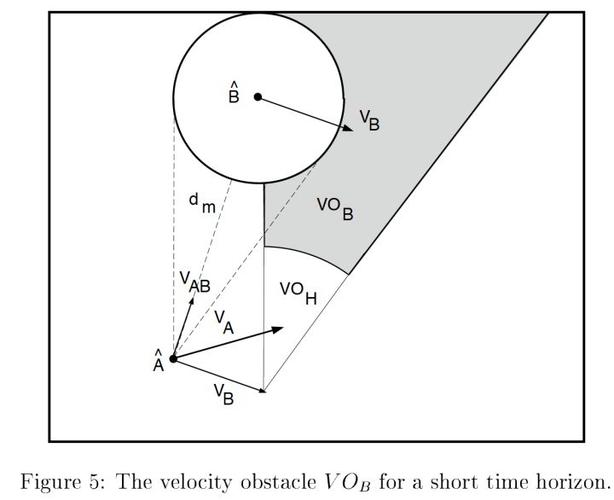
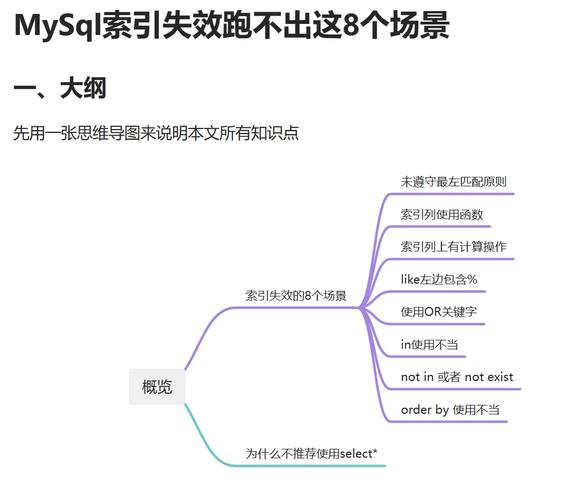
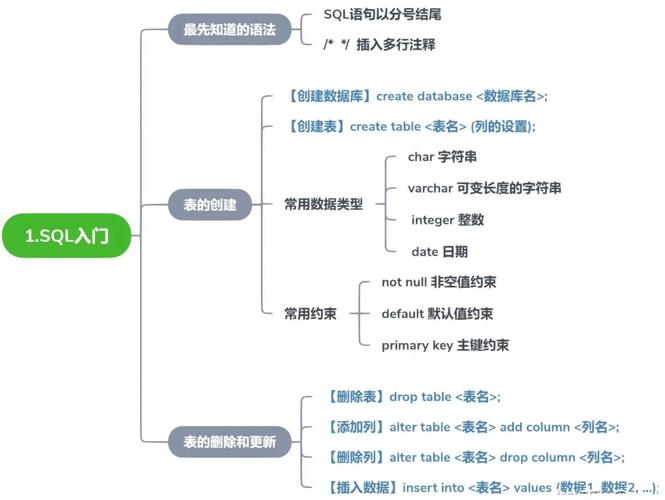
1. 物理存储层面:在数据库的物理存储层面,一级数据库可能指的是直接存储在硬盘上的数据文件,这些文件包含了数据库中的所有数据。一级数据库在这个层面上通常指的是最底层的存储结构,即数据文件本身。
2. 逻辑结构层面:在数据库的逻辑结构层面,一级数据库可能指的是数据库中的基本数据结构,如表、视图、索引等。这些数据结构是数据库中最基本的组成部分,它们共同构成了数据库的逻辑结构。
3. 访问方式层面:在数据库的访问方式层面,一级数据库可能指的是直接通过SQL(结构化查询语言)等数据库查询语言来访问和操作数据库的方式。这种方式是数据库访问中最常见和最基础的方式。
4. 数据库管理系统层面:在数据库管理系统的层面,一级数据库可能指的是数据库管理系统中的核心组件,如查询处理器、事务处理器、存储引擎等。这些组件共同构成了数据库管理系统的核心功能。
5. 应用层面:在应用层面,一级数据库可能指的是某个具体的应用程序所使用的数据库。这个数据库可能是应用程序的一部分,也可能是独立于应用程序的。
需要注意的是,以上解释并不是唯一的,一级数据库的具体含义可能因上下文而异。在实际应用中,需要根据具体的上下文来理解一级数据库的含义。
一级数据库概述

一级数据库,也称为原始数据库或一级数据资源,是生物信息学领域中最为基础的数据存储形式。它包含了生物分子数据的原始信息,如基因序列、蛋白质结构、代谢网络等。一级数据库是后续生物信息学研究和数据分析的基础,对于理解生物体系的复杂性和功能至关重要。
一级数据库的类型
一级数据库主要分为以下几类:
基因序列数据库:如NCBI的GenBank、EMBL的European Nucleotide Archive(ENA)等,存储了大量的基因序列信息。
蛋白质结构数据库:如RCSB PDB、PDBe等,提供了蛋白质的三维结构信息。
代谢组学数据库:如KEGG、MetaboBank等,记录了生物体内的代谢物及其相互作用信息。
基因组变异数据库:如dbSNP、gnomAD等,收集了人类基因组中的单核苷酸多态性(SNP)和结构变异信息。
一级数据库的特点
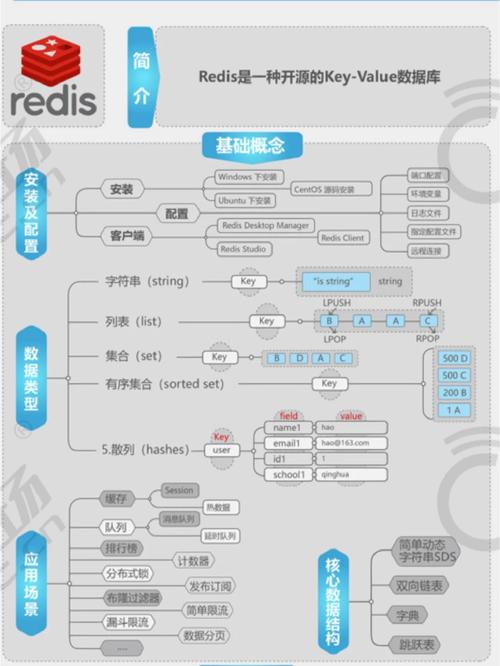
一级数据库具有以下特点:
原始性:一级数据库存储的是未经处理的原始数据,为后续研究提供了可靠的数据基础。
多样性:一级数据库涵盖了生物分子数据的各个方面,为研究者提供了丰富的数据资源。
动态性:一级数据库中的数据不断更新,反映了生物科学领域的最新研究成果。
开放性:一级数据库通常对公众开放,便于全球范围内的科研人员共享和利用。
一级数据库的应用

一级数据库在生物信息学研究中具有广泛的应用,主要包括以下方面:
基因功能预测:通过分析基因序列,预测基因的功能和调控机制。
蛋白质结构预测:基于蛋白质序列,预测蛋白质的三维结构和功能。
系统生物学研究:整合多源数据,研究生物体系的整体功能和调控网络。
药物研发:利用生物信息学技术,发现新的药物靶点和先导化合物。
一级数据库的挑战与展望
随着生物信息学的发展,一级数据库面临着以下挑战:
数据量激增:随着测序技术的进步,生物分子数据量呈指数级增长,对数据库的存储和处理能力提出了更高要求。
数据质量:保证数据库中数据的准确性和可靠性,是生物信息学研究的基础。
数据共享:促进全球范围内的数据共享,提高生物信息学研究的效率。
开发高效的数据存储和处理技术,提高数据库的性能。
建立严格的数据质量控制体系,确保数据的准确性和可靠性。
推动数据共享,促进全球范围内的科研合作。
总之,一级数据库在生物信息学研究中具有举足轻重的地位。随着技术的不断进步,一级数据库将发挥更大的作用,为生物科学的发展提供有力支持。
一级数据库,生物信息学,基因序列,蛋白质结构,代谢组学,基因组变异,数据共享,挑战与展望