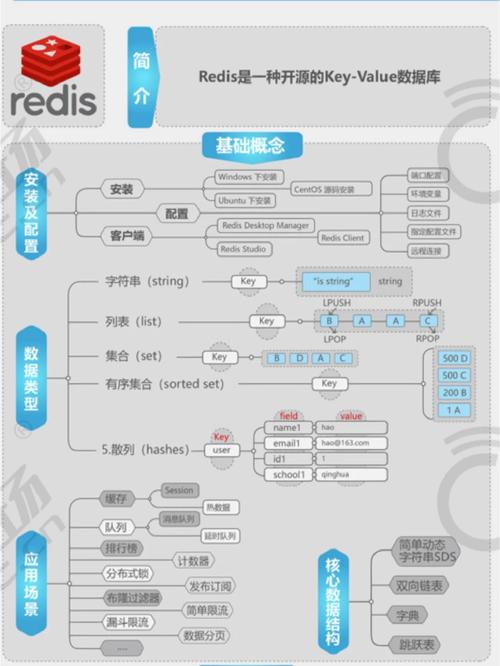
Apache Pig是一个用于处理和分析大规模数据集的编程框架,它是Apache Hadoop生态系统的一部分。以下是关于Pig的一些关键特点和优势:
1. 数据流语言和执行环境: Pig包括两部分:Pig Latin(一种描述数据流的高级语言)和Pig执行环境(用于运行Pig Latin程序的执行平台)。
2. 面向过程的语言: Pig是一种面向过程的数据流语言,适用于实时分析场n3. 高效和轻量级: Pig设计为轻量级,执行效率较高,适合需要快速处理大量数据的场合。
4. Pig Latin语言: Pig Latin是一种类似于SQL的语言,用户可以使用它来编写数据处理和转换任务。这种语言简洁易用,使得编程更加直观。
5. 自动优化: Pig的任务会自动进行优化,程序员只需要关注语言的语义,而不需要深入关注底层实现细节。
6. 丰富的运算符集: Pig提供了丰富的运算符,如join、sort、filter等,使得数据处理更加灵活和高效。
7. 与Hadoop的集成: Pig可以与Hadoop无缝集成,它将复杂的MapReduce任务简化为Pig Latin脚本,使得非专业的Hadoop开发者也能高效地处理大规模数据集。
8. 适用场n通过这些特点,Apache Pig简化了大数据处理的复杂性,让数据分析师和开发人员能够更专注于业务逻辑而非技术细节。
大数据时代下的Pig:概述与重要性

什么是Pig

Pig是由Apache Hadoop项目开发的一种高级数据流语言,用于简化Hadoop中的数据转换。它允许用户使用类似SQL的查询语言(Pig Latin)来处理大规模数据集。Pig的主要目的是将复杂的数据处理任务转化为简单的数据流操作,从而降低编程难度,提高数据处理效率。
Pig的特点与优势
Pig具有以下特点与优势:
易用性:Pig Latin语法简单,易于学习和使用。
高效性:Pig能够高效地处理大规模数据集,提高数据处理速度。
可扩展性:Pig可以与Hadoop生态系统中的其他工具无缝集成,如Hive、HBase等。
灵活性:Pig支持多种数据源,如文本文件、关系数据库等。
Pig的应用场景

Pig在以下场景中具有广泛的应用:
数据清洗:Pig可以快速处理大量数据,进行数据清洗和预处理。
数据转换:Pig可以将不同格式的数据转换为统一的格式,方便后续处理。
数据挖掘:Pig可以用于数据挖掘,发现数据中的潜在价值。
机器学习:Pig可以与机器学习算法结合,实现大规模数据集的机器学习任务。
Pig与Hadoop的关系
Pig是Hadoop生态系统中的重要组成部分,与Hadoop紧密相连。Pig Latin编写的脚本可以在Hadoop集群上运行,充分利用Hadoop的分布式计算能力。Pig与Hadoop的关系如下:
Pig Latin脚本被编译成MapReduce作业,由Hadoop执行。
Pig支持多种数据存储格式,如HDFS、HBase、Hive等,可以与Hadoop生态系统中的其他工具协同工作。
Pig可以优化MapReduce作业,提高数据处理效率。
Pig的未来发展趋势

随着大数据技术的不断发展,Pig在未来将呈现以下发展趋势:
性能优化:Pig将继续优化其性能,提高数据处理速度。
功能扩展:Pig将增加更多功能,如支持更多数据源、更复杂的查询操作等。
与其他大数据技术的融合:Pig将与更多大数据技术融合,如机器学习、人工智能等。
Pig作为一种高效的大数据处理工具,在当今大数据时代具有广泛的应用前景。随着技术的不断发展,Pig将在数据处理领域发挥越来越重要的作用。了解Pig的特点、应用场景和发展趋势,有助于我们更好地应对大数据时代的挑战。