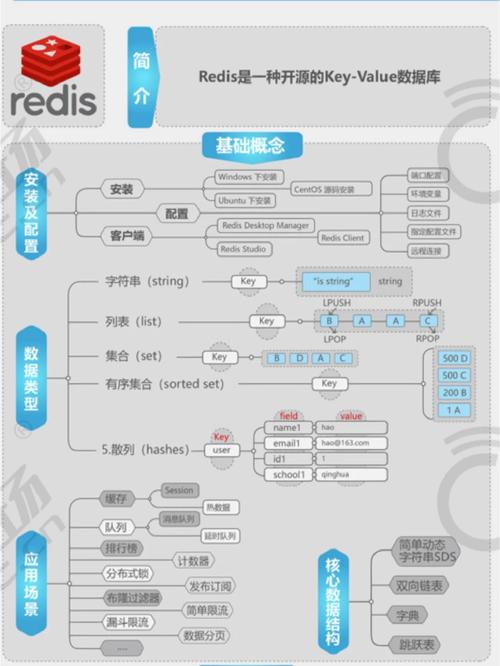
处理大数据的基本思路可以分为以下几个步骤:
1. 数据收集:从多个来源收集原始数据,这些来源可能包括数据库、日志文件、社交媒体、传感器数据等。
2. 数据存储:将收集到的数据存储在合适的存储系统中,如Hadoop分布式文件系统(HDFS)、云存储服务(如Amazon S3)等。
3. 数据预处理:在进行分析之前,对数据进行清洗、转换和归一化处理,以提高数据的质量和一致性。
4. 数据探索:使用统计分析和可视化工具对数据进行初步探索,以发现数据中的模式和趋势。
5. 数据建模:根据业务需求和数据分析目标,选择合适的算法和模型对数据进行建模,如机器学习、深度学习等。
6. 数据训练:使用训练数据集对模型进行训练,以优化模型参数,提高模型的预测精度。
7. 模型评估:使用测试数据集对模型进行评估,以验证模型的性能和泛化能力。
8. 模型部署:将训练好的模型部署到生产环境中,以实现实时的数据分析和预测。
9. 数据监控和维护:对模型和数据进行持续的监控和维护,以确保数据的质量和模型的准确性。
10. 业务决策:根据数据分析的结果,制定相应的业务策略和决策,以优化业务流程和提高业务效率。
在整个大数据处理过程中,需要注重数据安全和隐私保护,遵守相关法律法规和道德规范。同时,也需要关注数据处理的技术发展和创新,以提高数据处理效率和准确性。
处理大数据的基本思路
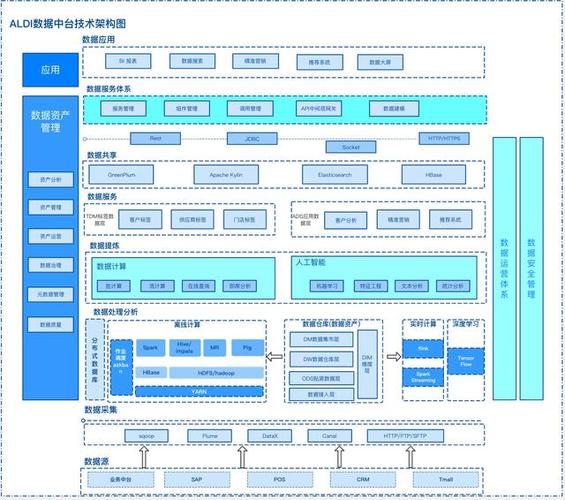
随着信息技术的飞速发展,大数据已经成为当今社会的重要资源。如何高效、准确地处理海量数据,成为企业和研究机构关注的焦点。本文将探讨处理大数据的基本思路,帮助读者了解大数据处理的关键步骤和常用技术。
一、数据预处理

数据预处理是大数据处理的第一步,其目的是提高数据质量,为后续的数据分析和挖掘奠定基础。
数据清理:包括格式标准化、异常数据清除、错误纠正、重复数据的清除等,确保数据的一致性和准确性。
数据集成:将来自不同来源、不同格式的数据进行整合,形成统一的数据视图。
数据转换:将数据转换为适合分析和挖掘的格式,如数值化、归一化等。
二、数据存储与管理
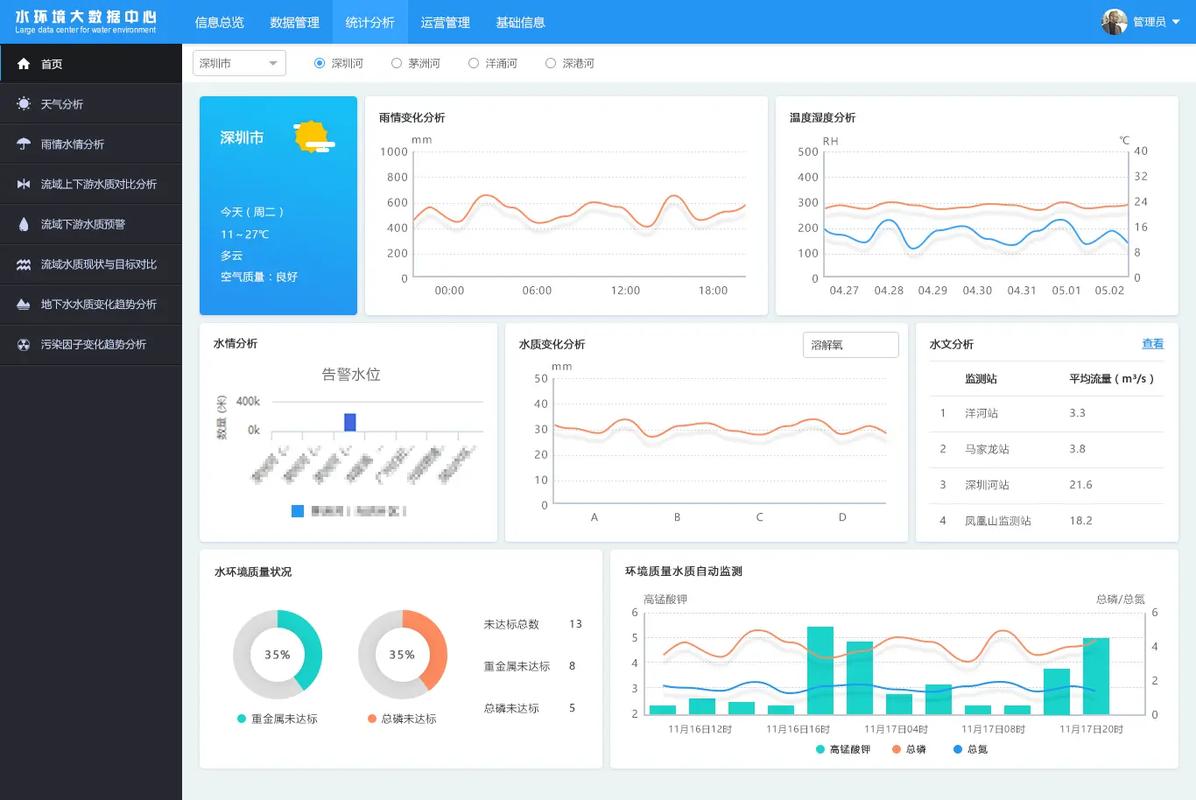
大数据处理需要高效、可靠的数据存储与管理技术。
分布式文件系统:如Hadoop的HDFS,适用于存储海量数据。
数据库技术:如关系型数据库、NoSQL数据库等,适用于存储和管理结构化或半结构化数据。
数据仓库:如星罗棋布(StarRocks)、阿里云ADB等,适用于存储和管理大规模数据集,支持复杂查询和分析。
三、数据处理与分析

数据处理与分析是大数据处理的核心环节。
数据挖掘:通过挖掘算法从海量数据中提取有价值的信息和知识。
统计分析:运用统计学方法对数据进行描述、推断和预测。
机器学习:通过算法模型从数据中学习规律,实现智能决策。
四、数据可视化

数据可视化是将数据以图形、图像等形式展示出来,帮助人们直观地理解数据。
图表工具:如ECharts、Highcharts等,适用于展示各类图表。
数据可视化平台:如Tableau、Power BI等,提供丰富的可视化功能和交互式分析。
五、大数据处理技术

大数据处理需要高效、可靠的技术支持。
分布式计算框架:如Hadoop、Spark等,适用于处理大规模数据集。
流处理技术:如Apache Flink、Apache Kafka等,适用于实时处理和分析数据。
数据挖掘算法:如聚类、分类、关联规则挖掘等,适用于从数据中提取有价值的信息。
处理大数据需要综合考虑数据预处理、存储与管理、数据处理与分析、数据可视化以及相关技术等多个方面。通过掌握这些基本思路,企业和研究机构可以更好地应对大数据时代的挑战,挖掘数据价值,推动业务发展。