
机器学习数据湖是一个集中存储、管理和处理大量数据的系统,用于支持机器学习模型的训练和部署。它通常包括以下关键组件:
1. 数据存储:数据湖支持多种数据格式的存储,包括结构化、半结构化和非结构化数据。数据可以存储在Hadoop分布式文件系统(HDFS)、Amazon S3、Azure Data Lake Storage等分布式存储系统中。
2. 数据处理:数据湖提供数据处理工具,如Apache Spark、Hive和Pig,用于对数据进行清洗、转换、分析和挖掘。这些工具可以处理大规模数据集,并支持分布式计算。
3. 数据管理:数据湖提供数据管理功能,如数据目录、元数据管理和数据治理。这些功能有助于用户发现、理解和管理数据湖中的数据。
4. 机器学习框架:数据湖支持各种机器学习框架,如TensorFlow、PyTorch和scikitlearn。这些框架可以与数据湖中的数据处理工具集成,用于训练和部署机器学习模型。
5. 可扩展性:数据湖具有可扩展性,可以处理不断增长的数据量。它支持横向扩展,即增加更多的计算和存储资源来满足需求。
6. 安全性:数据湖提供数据安全功能,如访问控制、加密和审计。这些功能有助于保护数据湖中的数据免受未经授权的访问和篡改。
7. 分析和可视化:数据湖提供分析和可视化工具,如Tableau、Power BI和QlikView。这些工具可以帮助用户从数据湖中提取洞察,并将其可视化。
机器学习数据湖的优势包括:
集中存储和管理数据,提高数据可用性和可访问性。 支持多种数据格式和类型,满足不同机器学习应用的需求。 提供数据处理和分析工具,简化机器学习模型的训练和部署。 具有可扩展性,可以处理大规模数据集。 提供数据安全功能,保护数据湖中的数据。
总之,机器学习数据湖是一个强大的系统,可以支持机器学习模型的训练和部署,提高数据分析和洞察的效率。
机器学习数据湖:构建高效数据处理的未来

随着大数据时代的到来,机器学习在各个领域的应用日益广泛。为了满足机器学习对海量数据的需求,数据湖作为一种新型的数据存储和管理技术应运而生。本文将探讨机器学习数据湖的概念、优势以及在实际应用中的挑战。
一、数据湖的概念
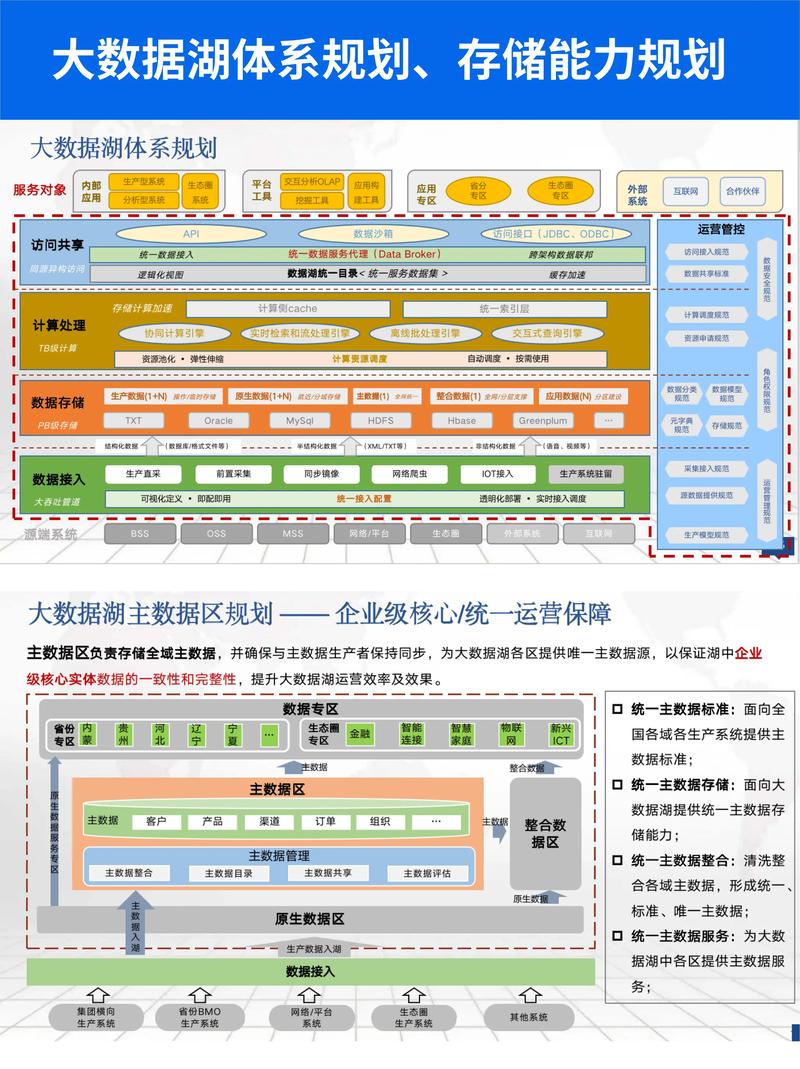
数据湖是一种分布式存储系统,用于存储和管理大规模、多样化的数据。与传统的数据仓库相比,数据湖具有以下特点:
存储格式多样:支持结构化、半结构化和非结构化数据,如文本、图片、视频等。
数据无需预处理:数据湖中的数据按照原始格式存储,无需进行结构化处理。
弹性扩展:数据湖可以根据需求动态扩展存储空间。
低成本:数据湖采用分布式存储,降低了存储成本。
二、机器学习数据湖的优势

数据湖在机器学习领域具有以下优势:
数据多样性:数据湖可以存储各种类型的数据,为机器学习提供了丰富的数据来源。
数据无需预处理:数据湖中的数据无需进行结构化处理,降低了数据预处理的工作量。
高效的数据访问:数据湖采用分布式存储,提高了数据访问速度。
灵活的数据处理:数据湖支持多种数据处理技术,如批处理、实时处理等。
三、机器学习数据湖的应用场景

机器学习数据湖在以下场景中具有广泛的应用:
推荐系统:通过分析用户行为数据,为用户推荐感兴趣的商品或内容。
欺诈检测:通过分析交易数据,识别潜在的欺诈行为。
智能语音识别:通过分析语音数据,实现语音识别和语音合成。
图像识别:通过分析图像数据,实现图像分类和目标检测。
四、机器学习数据湖的挑战
尽管机器学习数据湖具有诸多优势,但在实际应用中仍面临以下挑战:
数据质量:数据湖中的数据质量参差不齐,需要建立数据治理机制。
数据安全:数据湖存储了大量敏感数据,需要加强数据安全防护。
数据管理:数据湖中的数据量庞大,需要建立高效的数据管理机制。
技术选型:数据湖涉及多种技术,需要根据实际需求进行技术选型。
机器学习数据湖作为一种新型的数据存储和管理技术,在机器学习领域具有广泛的应用前景。通过解决数据质量、数据安全、数据管理和技术选型等挑战,机器学习数据湖将为构建高效数据处理的未来提供有力支持。








