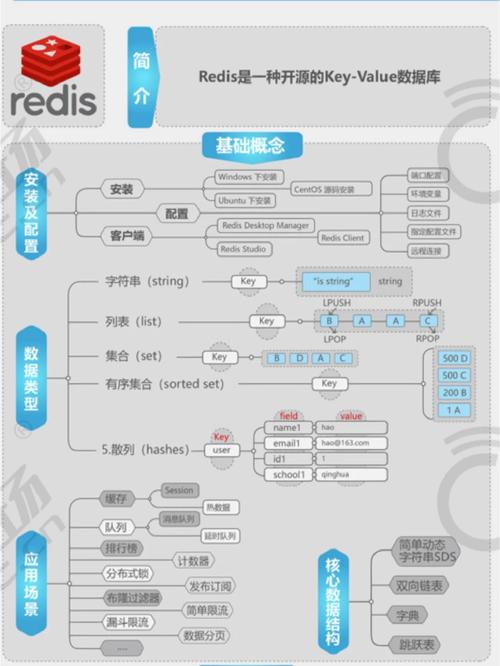
选择向量数据库时,需要考虑以下几个关键因素:
1. 数据规模:考虑你需要存储的向量数量和大小,以及是否需要支持实时更新和查询。
2. 查询性能:评估数据库的查询速度和效率,特别是对于高维向量的相似度搜索。
3. 索引方法:了解数据库使用的索引算法,如LSH、Annoy、Faiss等,以及它们对查询性能和存储效率的影响。
4. 可扩展性:考虑数据库是否支持分布式存储和计算,以适应数据规模的扩展。
5. 可用性和可靠性:评估数据库的故障恢复能力和数据备份机制,确保数据的安全性和稳定性。
6. 社区和支持:考虑数据库的社区活跃度和官方支持情况,以便在遇到问题时能够得到及时的帮助。
7. 成本:评估数据库的授权费用、硬件成本和维护成本,选择性价比高的解决方案。
根据这些因素,你可以选择适合自己需求的向量数据库。一些流行的向量数据库包括:
1. Faiss:由Facebook AI Research开发,支持多种索引算法,适用于大规模向量数据的相似度搜索。
2. Annoy:由Spotify开发,使用近似最近邻搜索算法,适用于高维向量的快速查询。
3. Elasticsearch:虽然不是专门为向量数据设计的,但通过插件和扩展,可以支持向量数据的存储和查询。
4. Milvus:由Zilliz开发,是一个开源的向量数据库,支持多种索引算法和查询接口,适用于大规模向量数据的存储和搜索。
5. Redisearch:基于Redis的向量搜索模块,支持向量数据的存储和查询,适用于需要高性能和低延迟的场景。
选择向量数据库时,建议先进行充分的调研和测试,评估不同数据库的性能和适用性,以便选择最适合自己需求的解决方案。
向量数据库选择指南:如何找到最适合您的解决方案
随着大数据和人工智能技术的快速发展,向量数据库作为一种高效处理和检索高维数据的工具,越来越受到重视。选择合适的向量数据库对于提高数据处理的效率和准确性至关重要。本文将为您介绍如何选择合适的向量数据库,并提供一些实用的建议。
一、了解向量数据库的基本概念

向量数据库是一种专门用于存储和检索高维数据的数据库。它通过将数据转换为向量形式,利用向量空间模型进行数据存储和检索。与传统的键值对数据库相比,向量数据库在处理高维数据时具有更高的效率和准确性。
二、确定您的需求

数据类型:确定您需要存储的数据类型,如文本、图像、音频等。
数据量:了解您的数据量大小,以便选择合适的数据库规模。
查询性能:根据您的查询需求,选择具有高性能的数据库。
扩展性:考虑数据库的扩展性,以便在数据量增长时进行扩展。
成本:根据您的预算,选择性价比高的数据库。
三、评估向量数据库的性能
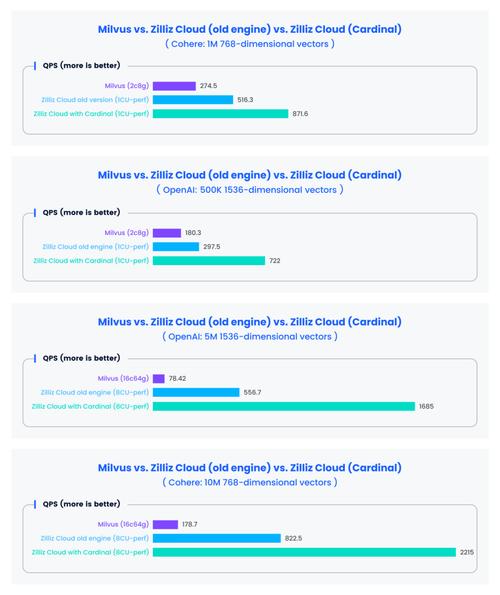
向量数据库的性能主要取决于以下几个方面:
索引算法:不同的索引算法对查询性能有较大影响。常见的索引算法包括HNSW、IVF、LSH等。
查询优化:数据库的查询优化能力对查询性能至关重要。
分布式架构:分布式架构可以提高数据库的扩展性和并发处理能力。
在评估数据库性能时,可以参考以下指标:
查询响应时间:数据库处理查询所需的时间。
吞吐量:数据库在单位时间内处理的查询数量。
内存和存储占用:数据库在运行过程中所需的内存和存储空间。
四、考虑数据库的生态系统和社区支持
社区活跃度:社区活跃度可以反映数据库的受欢迎程度和用户支持。
文档和教程:完善的文档和教程可以帮助用户快速上手。
第三方工具和库:丰富的第三方工具和库可以扩展数据库的功能。
五、选择合适的向量数据库

Milvus:一款开源的向量数据库,具有高性能、易用性和可扩展性。
FAISS:Facebook AI Research提出的向量索引库,支持多种索引算法。
Qdrant:一款开源的向量数据库,支持多种索引算法和查询语言。
选择合适的向量数据库对于提高数据处理的效率和准确性至关重要。通过了解向量数据库的基本概念、确定需求、评估性能、考虑生态系统和社区支持等因素,您可以找到最适合您的解决方案。希望本文能为您提供一些有用的参考。