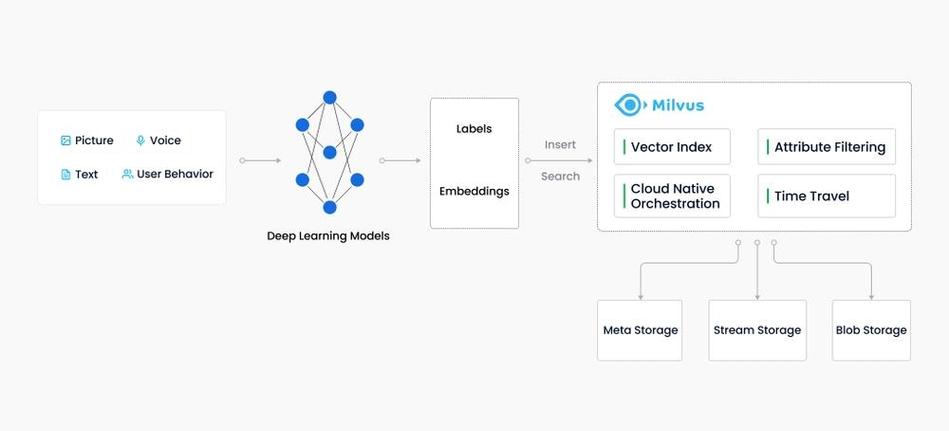
向量数据库(Vector Database)是一种专门用于存储和检索向量数据的数据库系统。它们在处理高维数据,如文本、图像或音频数据时,通常与机器学习模型(如深度学习模型)结合使用。这些模型可以生成数据的高效表示,称为向量,然后向量数据库可以存储这些向量并提供快速的搜索功能。
1. Faiss:由Facebook AI Research开发,是一个库,用于高效相似性搜索和密集向量聚类。它不是数据库,但可以与数据库系统结合使用。
2. Annoy:由Spotify开发,是一个小型的、快速的库,用于近似最近邻搜索。
3. Elasticsearch:虽然Elasticsearch主要是一个搜索引擎,但它也可以用于存储和搜索向量数据,尤其是在与Elasticsearch ML插件结合使用时。
4. Milvus:由Zilliz开发,是一个开源的向量数据库,专为存储和搜索高维向量数据而设计。
5. Pinecone:一个基于云的向量数据库服务,提供快速、可扩展的向量搜索功能。
6. Qdrant:一个开源的向量数据库,由Yandex开发,用于存储和搜索高维向量数据。
7. Weaviate:一个开源的向量数据库,专注于语义搜索和向量搜索。
8. Scai:一个商业化的向量数据库,提供快速的向量搜索和可扩展性。
9. RediSearch:由Redis Labs开发,是一个Redis模块,用于实现全文搜索和向量搜索。
10. Dense Vector Index:由Apache Solr开发,是一个用于存储和搜索高维向量的插件。
这些向量数据库系统通常不直接提供大模型,但它们可以与各种机器学习模型结合使用。例如,用户可以使用深度学习模型(如BERT、GPT3等)来生成文本数据的高效表示,然后将这些向量存储在向量数据库中,以便进行快速的搜索和检索。
向量数据库:大模型时代的核心基础设施
一、向量数据库的定义与作用

向量数据库是一种专门用于存储和检索高维空间中向量数据的数据库。在大模型时代,向量数据库主要用于存储和检索大模型训练过程中产生的向量数据,如文本、图像、音频等。这些向量数据经过向量化处理后,可以方便地进行相似度计算和检索,从而提高大模型的性能和效率。
二、向量数据库在大模型中的应用场景
向量数据库在大模型中的应用场景主要包括以下几个方面:
文本检索:通过将文本数据向量化,向量数据库可以快速检索与查询文本相似的内容,应用于搜索引擎、问答系统等。
图像识别:将图像数据向量化后,向量数据库可以用于图像检索、图像分类等任务,如人脸识别、物体检测等。
语音识别:语音数据向量化后,向量数据库可以用于语音检索、语音识别等任务,如语音助手、语音翻译等。
推荐系统:向量数据库可以用于存储用户行为数据,通过相似度计算为用户提供个性化的推荐内容。
三、向量数据库的优势
向量数据库在大模型时代具有以下优势:
高效检索:向量数据库采用高效的索引结构,如球树、k-d树等,可以快速检索相似向量。
高精度计算:向量数据库支持多种相似度计算方法,如余弦相似度、欧氏距离等,可以保证检索结果的准确性。
可扩展性:向量数据库支持分布式存储和计算,可以满足大规模数据存储和检索的需求。
安全性:向量数据库支持数据加密、访问控制等安全机制,保障数据安全。
四、向量数据库的发展趋势
随着大模型技术的不断发展,向量数据库也将呈现出以下发展趋势:
智能化:向量数据库将结合人工智能技术,实现自动索引、自动优化等智能化功能。
多模态融合:向量数据库将支持多种数据类型的存储和检索,如文本、图像、音频等,实现多模态数据的融合。
云原生:向量数据库将更加注重云原生架构,提供更加灵活、可扩展的云服务。
开源生态:向量数据库将积极参与开源社区,推动开源生态的发展。
向量数据库在大模型时代扮演着核心基础设施的角色。随着大模型技术的不断发展,向量数据库将发挥越来越重要的作用。了解向量数据库的定义、应用场景、优势和发展趋势,有助于我们更好地把握大模型时代的发展脉搏。