
1. 分类问题: 垃圾邮件过滤:通过学习电子邮件的内容,分类电子邮件为垃圾邮件或正常邮件。 手写数字识别:通过学习手写数字的图像,识别数字09。 图像分类:例如,将图片分类为猫、狗或其他动物。
2. 回归问题: 房价预测:通过学习房屋的特征(如面积、房间数、位置等),预测房价。 股票价格预测:通过学习股票的历史价格和其他相关数据,预测未来的股票价格。
3. 聚类问题: 客户细分:根据客户的购买行为和其他特征,将客户分为不同的群体。 文档聚类:将大量的文档根据其内容分为不同的主题。
4. 降维: 主成分分析(PCA):通过降维技术,将高维数据映射到低维空间,同时保留大部分信息。
5. 自然语言处理: 情感分析:通过学习文本内容,判断其情感倾向(如正面、负面或中性)。 机器翻译:将一种语言的文本翻译成另一种语言。
6. 推荐系统: 电影推荐:根据用户的观看历史和评分,推荐用户可能喜欢的电影。 商品推荐:根据用户的购买历史和浏览行为,推荐用户可能感兴趣的商品。
7. 异常检测: 信用卡欺诈检测:通过学习正常的信用卡交易模式,识别异常的交易行为。
8. 强化学习: 自动驾驶:通过学习如何驾驶,使自动驾驶汽车能够在各种路况下安全行驶。 游戏AI:通过学习游戏规则和策略,使AI在游戏中取得好成绩。
9. 深度学习: 图像生成:通过生成对抗网络(GANs),生成逼真的图像。 语音识别:通过深度学习模型,将语音转换为文字。
这些实例只是冰山一角,机器学习的应用非常广泛,几乎涵盖了所有领域。随着技术的不断发展,机器学习的应用将会越来越广泛。
Python机器学习经典实例:从鸢尾花数据集到市场细分

随着大数据时代的到来,机器学习技术在各个领域得到了广泛应用。Python作为一种简洁、高效、功能强大的编程语言,成为了机器学习领域的首选工具。本文将介绍几个经典的Python机器学习实例,帮助读者了解机器学习的基本原理和应用场景。
一、鸢尾花数据集分类
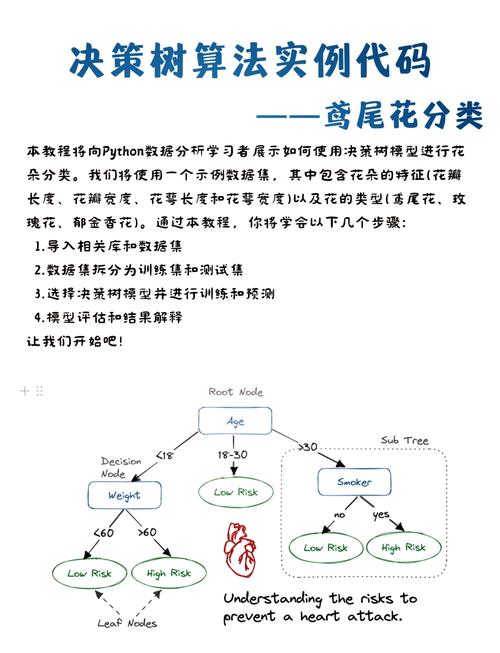
鸢尾花数据集是机器学习领域最经典的数据集之一,它包含了150个样本,每个样本由4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)组成,分为3个类别。这个数据集常用于测试分类算法的性能。
1.1 使用Scikit-learn进行鸢尾花数据集分类
Scikit-learn是一个开源的Python机器学习库,提供了丰富的算法和工具。以下是一个使用Scikit-learn对鸢尾花数据集进行分类的示例代码:
```python
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
加载数据集
iris = load_iris()
X = iris.data
y = iris.target
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
使用SVM进行分类
clf = SVC(kernel='linear')
clf.fit(X_train, y_train)
评估模型
score = clf.score(X_test, y_test)
print(\








