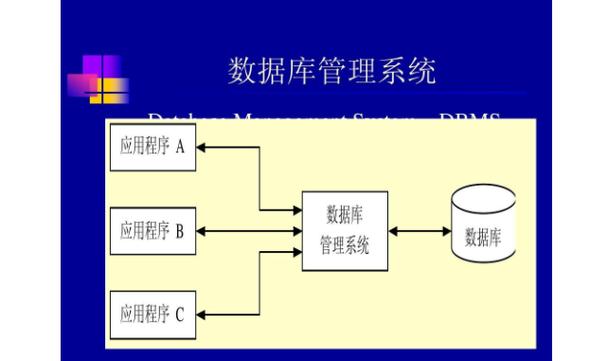
CAZy数据库(CarbohydrateActive enZYmes Database)是一个专门用于研究和分类碳水化合物活性酶(CAZymes)的数据库。该数据库自1998年起上线,致力于展示和分析与碳水化合物活性酶相关的基因组、结构以及生化信息。
主要功能1. 数据展示和分析:CAZy数据库通过浏览序列家族或基因组中的碳水化合物活性酶内容来提供数据。2. 酶系家族分类:CAZy数据库根据蛋白质结构域中氨基酸序列的相似性,将碳水化合物活性酶家族分为多个类别,如糖苷水解酶、糖基转移酶等。3. 宏基因组研究支持:CAZy数据库在宏基因组研究中被广泛用于功能挖掘和物种分类。4. 数据查询和分析:用户可以通过关键词、序列、结构等多种方式在CAZy数据库中进行搜索和筛选酶家族的成员。
数据内容CAZy数据库中包含了碳水化合物酶类的物种来源、酶功能EC分类、基因序列、蛋白质序列及其结构等信息。随着宏基因组学技术的发展,CAZy数据库中家族内序列数据量不断增加,这为家族内进一步进行亚家族分类奠定了基础,并提高了酶分子功能预测的准确度。
应用领域1. 生物质转化:CAZy数据库的数据和分析工具可以帮助指导酶分子理性设计,提高特定功能酶组分设计的成功概率,从而推动生物质转化产业的发展。2. 基因组学研究:在基因组学研究中,CAZy数据库支持对宏基因组数据进行物种注释和功能挖掘,特别是碳水化合物活性酶的分类、酶类功能及在不同生物体中的应用。
使用方法1. 访问官方网站:用户可以通过访问CAZy数据库的官方网站获取最新版本的数据库和相关工具和资源。2. 数据查询和分析:用户可以在网站上找到详细的文档和使用说明,使用关键词、序列、结构等不同的方式搜索和筛选酶家族的成员。
总之,CAZy数据库是一个功能强大且应用广泛的生物信息学工具,对于研究和分析碳水化合物活性酶具有重要作用。
CAZy数据库:碳水化合物活性酶的宝库
碳水化合物活性酶(Carbohydrate-active enzymes,CAZy)在生物体内发挥着至关重要的作用,它们参与着碳水化合物的合成、分解和修饰等过程。为了更好地研究和利用这些酶,CAZy数据库应运而生,成为了一个宝贵的生物信息资源。
CAZy数据库是一个专门收录碳水化合物活性酶的数据库,它基于蛋白质结构域中的氨基酸序列相似性,将碳水化合物活性酶类归入不同的蛋白质家族。该数据库由欧洲生物信息研究所(EBI)维护,包含了碳水化合物酶类的物种来源、酶功能EC分类、基因序列、蛋白质序列及其结构等信息。
CAZy数据库主要分为六大类,每一类都有相应的编号。这些类别包括:碳水化合物结合酶(CBM)、碳水化合物水解酶(GH)、碳水化合物异构酶(GI)、碳水化合物转移酶(GT)、碳水化合物裂解酶(PL)和碳水化合物修饰酶(PM)。每个类别下又细分为多个家族,例如GH13家族、GH157家族等。
蛋白质功能预测:通过CAZy数据库,研究人员可以快速了解未知蛋白质的功能,从而为后续实验提供方向。
酶工程:CAZy数据库中的酶序列和结构信息,有助于设计具有特定功能的酶,用于工业生产或生物催化。
生物多样性研究:CAZy数据库收录了来自不同物种的酶序列,有助于揭示生物多样性与碳水化合物代谢之间的关系。
疾病研究:某些碳水化合物活性酶与人类疾病的发生发展密切相关,CAZy数据库有助于研究这些酶在疾病中的作用机制。
要使用CAZy数据库,首先需要访问其官方网站(https://www.cazy.org/)。以下是使用CAZy数据库的基本步骤:
在首页输入要查询的酶名称或序列,点击“Search”按钮。
在搜索结果中,选择相应的酶条目。
查看酶的基本信息,如家族、序列、结构等。
下载所需的数据,如FASTA格式序列、结构文件等。
随着生物信息学技术的不断发展,CAZy数据库也在不断更新和完善。未来,CAZy数据库有望在以下方面取得突破:
收录更多酶序列和结构信息,提高数据库的全面性。
开发更强大的搜索和数据分析工具,方便用户使用。
与其他数据库进行整合,形成更加完善的生物信息资源体系。
推动CAZy数据库在更多领域的应用,如药物研发、生物能源等。
CAZy数据库作为一个重要的生物信息资源,为碳水化合物活性酶的研究提供了有力支持。随着数据库的不断发展和完善,CAZy数据库将在生物研究领域发挥越来越重要的作用。