
分布式机器学习是指利用多台计算机或处理器协同工作来执行机器学习任务的一种计算方式。它允许机器学习模型在更大的数据集上训练,并加速模型的训练过程。分布式机器学习通常涉及到以下几个关键方面:
1. 数据分发:在分布式环境中,数据通常被分散存储在多个节点上。数据分发策略需要考虑如何有效地将数据分配到各个节点上,以便并行处理。
2. 模型训练:分布式机器学习中的模型训练通常采用并行化技术,如数据并行或模型并行。数据并行将数据分散到多个节点上,每个节点独立训练模型的一部分,然后将结果合并。模型并行则将模型的不同部分分配到不同的节点上,每个节点负责训练模型的一部分。
3. 参数同步:在分布式训练过程中,各个节点需要定期同步模型的参数,以确保模型的训练一致性。参数同步策略需要平衡通信开销和计算开销,以优化整体训练性能。
4. 负载均衡:分布式机器学习系统需要考虑如何合理分配计算任务和数据,以实现负载均衡。负载均衡策略可以确保各个节点的工作负载相对均衡,避免某些节点过载而其他节点空闲。
5. 容错性:分布式系统需要具备容错能力,以应对节点故障、网络故障等异常情况。容错策略可以包括数据备份、任务重试、节点替换等。
6. 可扩展性:分布式机器学习系统需要具备良好的可扩展性,以适应不断增长的数据规模和计算需求。可扩展性可以通过增加节点数量、优化算法和系统架构等方式实现。
7. 资源管理:分布式机器学习系统需要有效管理计算资源,包括CPU、内存、磁盘等。资源管理策略可以包括资源分配、任务调度、资源监控等。
分布式机器学习在处理大规模数据集、提高训练速度、实现负载均衡和容错性等方面具有优势。它也面临一些挑战,如通信开销、同步延迟、节点故障等。因此,设计高效的分布式机器学习系统需要综合考虑多个因素,以实现最优的性能和可靠性。
分布式机器学习:大数据时代的解决方案
一、分布式机器学习的概念与优势
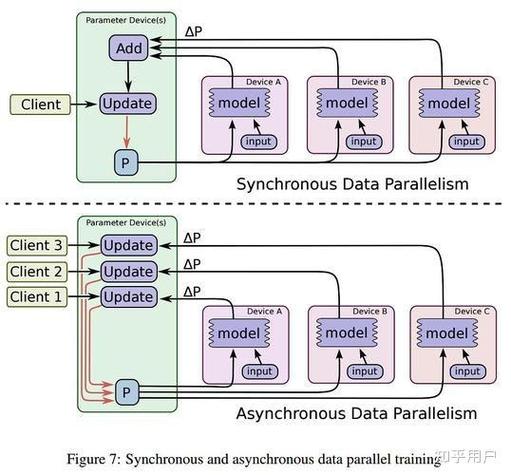
分布式机器学习是指将机器学习任务分解成多个子任务,在多个计算节点上并行执行,最终合并结果以完成整个任务。这种模式具有以下优势:
提高计算效率:通过并行计算,分布式机器学习可以显著缩短计算时间,满足实时性需求。
扩展性强:分布式机器学习可以轻松扩展到更多计算节点,适应大规模数据集的处理。
容错性好:在分布式系统中,单个节点的故障不会影响整个系统的运行,提高了系统的稳定性。
二、分布式机器学习框架
目前,分布式机器学习框架主要包括以下几种:
MapReduce编程模型:Hadoop MapReduce框架是典型的MapReduce编程模型,适用于大规模数据集的分布式计算。
Spark:Spark是一个开源的分布式计算系统,具有高效、易用、通用性强等特点,适用于各种分布式计算任务。
TensorFlow:TensorFlow是Google开发的开源机器学习框架,支持分布式计算,适用于构建大规模机器学习模型。
三、分布式机器学习算法
分布式机器学习算法主要包括以下几种:
并行决策树:通过将决策树算法分解成多个子任务,在多个节点上并行训练,提高计算效率。
并行k-均值算法:将k-均值算法分解成多个子任务,在多个节点上并行执行,提高聚类效率。
四、分布式机器学习在实践中的应用
分布式机器学习在各个领域都有广泛的应用,以下列举几个典型应用场景:
金融领域:分布式机器学习可以用于风险评估、欺诈检测、信用评分等任务。
医疗健康领域:分布式机器学习可以用于疾病预测、药物研发、个性化医疗等任务。
零售领域:分布式机器学习可以用于客户细分、需求预测、库存管理等任务。
分布式机器学习是大数据时代解决复杂计算问题的有效途径。随着技术的不断发展,分布式机器学习将在更多领域发挥重要作用,推动人工智能技术的进步。








