
机器学习的基本步骤包括:
1. 数据收集:收集与任务相关的数据。2. 数据预处理:清洗和转换数据,以便模型可以理解。3. 特征工程:选择和创建有助于模型预测的特征。4. 模型选择:选择一个适合任务的机器学习模型。5. 模型训练:使用训练数据来训练模型。6. 模型评估:使用测试数据来评估模型的性能。7. 模型部署:将模型部署到生产环境中,以便它可以做出预测。
要入门机器学习,你可以学习以下编程语言和工具:
1. Python:这是机器学习中最常用的编程语言,因为它有许多用于机器学习的库,如scikitlearn、TensorFlow和PyTorch。2. R:这是一种流行的统计编程语言,也常用于机器学习。3. Jupyter Notebook:这是一个交互式计算环境,可以用来编写和执行Python代码。4. Git:这是一个版本控制系统,可以用来管理代码和协作。
此外,还有一些在线课程和书籍可以帮助你入门机器学习:
1. Coursera上的“机器学习”课程(由吴恩达教授)2. edX上的“机器学习基础”课程3. “Python机器学习基础教程”书籍4. “机器学习实战”书籍
机器学习入门指南:从基础到实践

一、什么是机器学习?
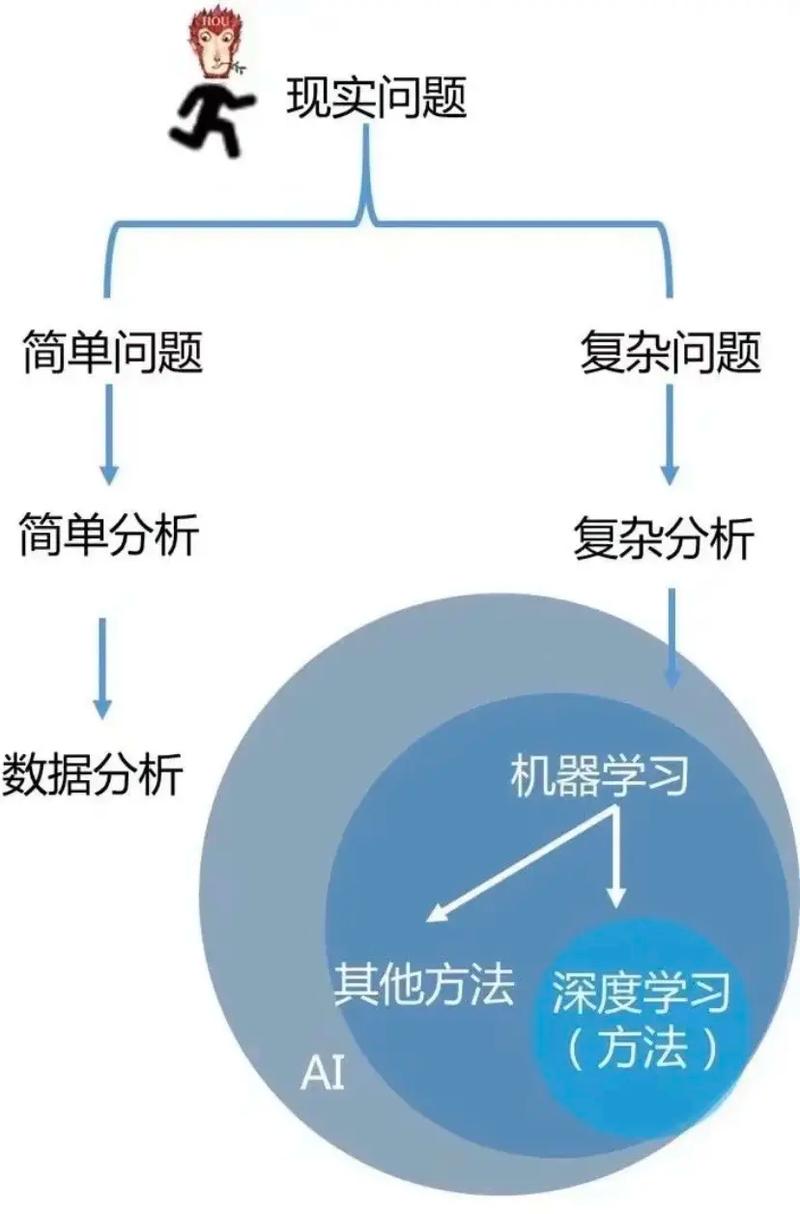
机器学习是一种使计算机系统能够从数据中学习并做出决策或预测的技术。简单来说,就是让计算机通过学习数据来提高其性能,而不是通过编程直接告诉它如何执行任务。
二、机器学习的基本类型
根据学习方式和应用场景,机器学习可以分为以下几种类型:
监督学习:通过已标记的训练数据来训练模型,使其能够对未知数据进行预测。
无监督学习:通过未标记的数据来发现数据中的模式和结构。
半监督学习:结合了监督学习和无监督学习的方法,使用部分标记和部分未标记的数据进行训练。
强化学习:通过奖励和惩罚机制来指导模型学习,使其在特定环境中做出最优决策。
三、机器学习的基本概念

在深入学习机器学习之前,了解以下基本概念是很有帮助的:
特征:用于描述数据的属性或变量。
模型:用于从数据中学习并做出预测的算法。
训练集:用于训练模型的已标记数据集。
测试集:用于评估模型性能的未标记数据集。
评估指标:用于衡量模型性能的指标,如准确率、召回率、F1分数等。
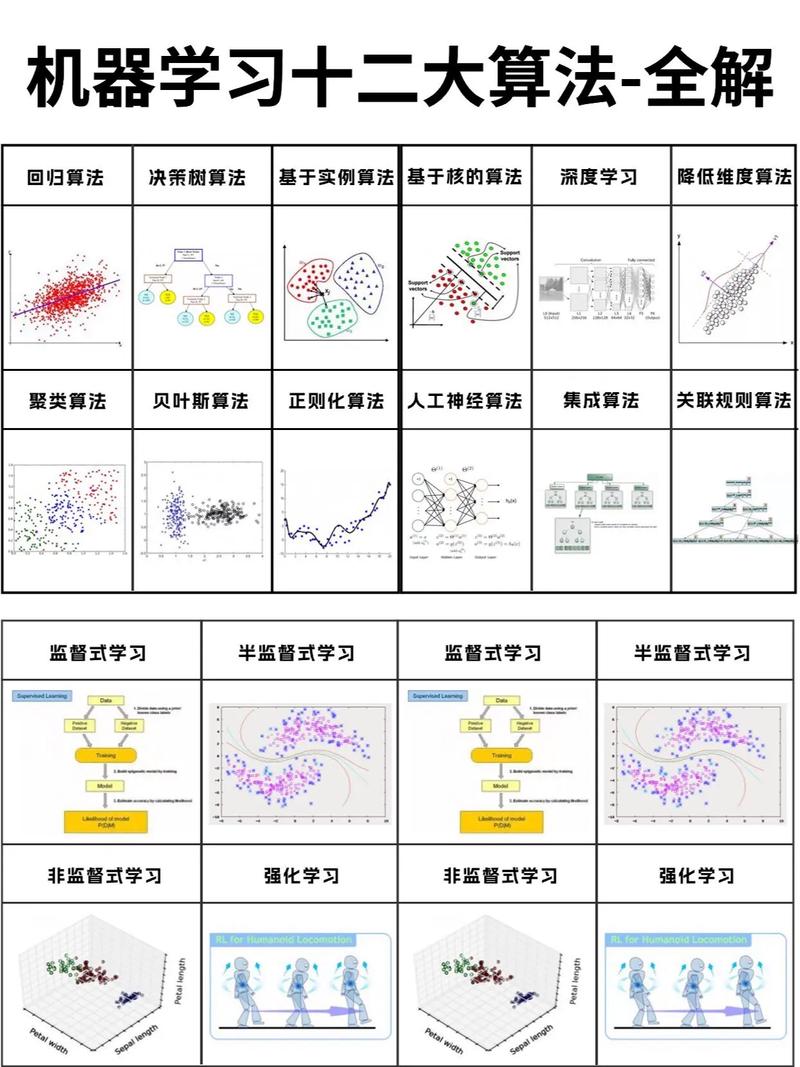
四、机器学习的主要算法
线性回归:用于预测连续值,如房价、股票价格等。
逻辑回归:用于预测离散值,如分类问题,如垃圾邮件检测、疾病诊断等。
决策树:用于分类和回归问题,具有直观的解释能力。
支持向量机(SVM):用于分类和回归问题,特别适用于高维数据。
神经网络:用于复杂的模式识别和预测,如图像识别、语音识别等。
五、机器学习的实践步骤

以下是一个简单的机器学习实践步骤,帮助您从零开始:
收集数据:从各种来源收集相关数据。
预处理数据:清洗、转换和标准化数据。
选择模型:根据问题类型选择合适的算法。
训练模型:使用训练集对模型进行训练。
评估模型:使用测试集评估模型性能。
优化模型:根据评估结果调整模型参数。
部署模型:将模型应用于实际场景。
六、学习资源与社区
在线课程:Coursera、edX、Udacity等平台提供了丰富的机器学习课程。







