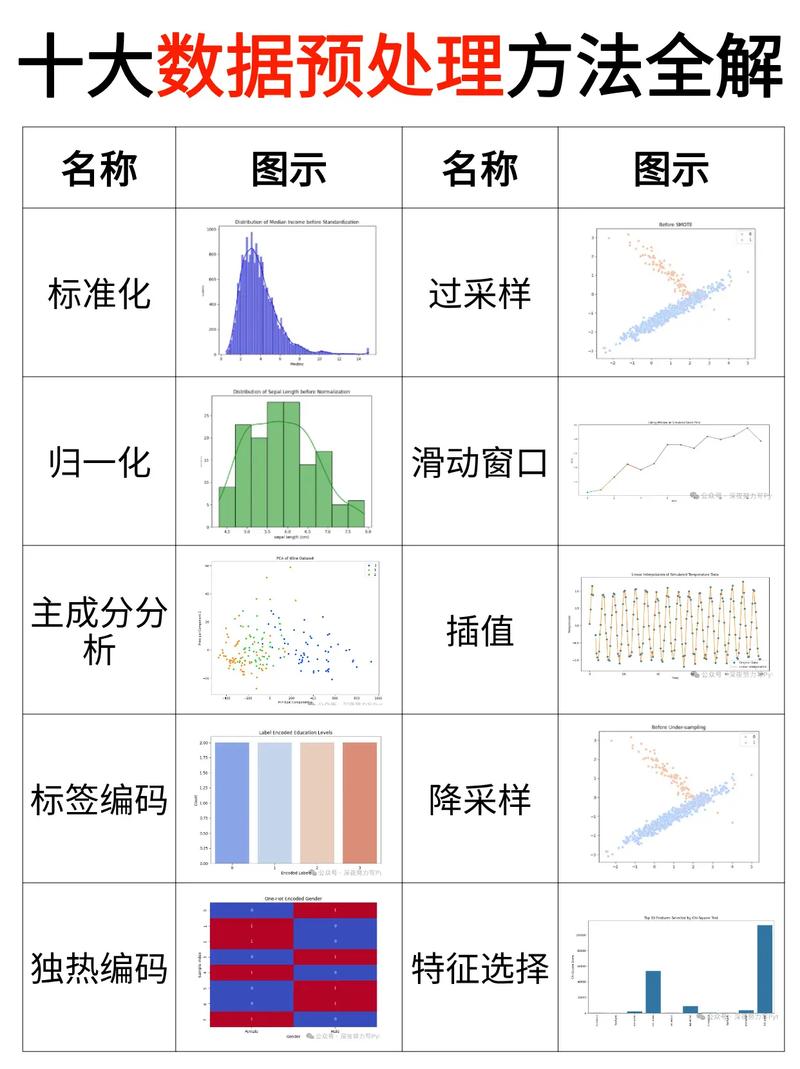
大数据预处理是数据科学和机器学习项目中的关键步骤,它涉及到对原始数据进行清洗、转换和归一化,以便为后续的数据分析和建模做好准备。以下是大数据预处理的一些常用方法:
1. 数据清洗: 去除缺失值:识别并处理缺失数据,可以使用填充、删除或插值等方法。 去除重复数据:识别并删除重复的记录。 处理异常值:识别并处理异常值,可以通过删除、替换或标准化等方法。
3. 数据归一化: 标准化:将数据缩放到具有零均值和单位方差的范围。 归一化:将数据缩放到特定的范围,如0到1或1到1。
4. 数据集成: 合并数据源:将来自不同数据源的数据合并到一起,以形成一个统一的数据集。 数据对齐:确保不同数据源中的数据在时间、空间或其他维度上对齐。
5. 数据抽样: 简单随机抽样:从数据集中随机选择样本。 分层抽样:根据某些特征将数据分层,然后在每个层内进行随机抽样。 系统抽样:按照一定的规律从数据集中选择样本。
6. 数据存储和格式化: 选择合适的数据存储格式:如CSV、Parquet、Avro等,以提高数据存储和处理的效率。 数据分区:将数据分区存储,以提高查询和处理的效率。
7. 数据安全和隐私: 数据脱敏:对敏感数据进行脱敏处理,以保护个人隐私。 数据加密:对数据进行加密,以保护数据的安全。
8. 数据验证: 数据质量检查:检查数据的一致性、准确性和完整性。 数据监控:实时监控数据质量,以确保数据质量符合要求。
9. 数据可视化: 数据探索:通过数据可视化工具探索数据,以发现数据中的模式和趋势。 数据报告:生成数据报告,以向 stakeholders 报告数据预处理的结果。
10. 数据文档: 数据字典:创建数据字典,记录数据的来源、格式、含义等信息。 数据流程图:绘制数据流程图,展示数据预处理的过程。
这些方法可以根据具体的项目需求和数据特点进行选择和组合。大数据预处理是一个迭代的过程,可能需要多次调整和优化,以达到最佳的数据质量。
大数据预处理的重要性

在大数据时代,数据已成为企业和社会的重要资产。原始数据往往存在质量问题,如数据缺失、数据不一致、数据噪声等。为了从这些数据中提取有价值的信息,大数据预处理成为数据分析和挖掘的第一步。有效的预处理方法可以提高数据质量,降低后续分析的成本,提高分析结果的准确性。
数据清洗
去除重复数据:通过比较数据记录的唯一性,删除重复的数据项。
处理缺失值:根据数据的重要性和缺失值的比例,选择合适的处理方法,如删除、插补或使用模型预测缺失值。
纠正错误数据:识别并修正数据中的错误,如拼写错误、格式错误等。
去除噪声数据:通过滤波、平滑等技术去除数据中的噪声。
数据集成
数据合并:将具有相同字段的数据表合并成一个表。
数据转换:将不同格式的数据转换为统一的格式。
数据映射:将不同数据源中的相同字段映射到一起。
数据变换
数据标准化:将数据缩放到一个特定的范围,如[0,1]或[-1,1]。
数据归一化:将数据转换为具有相同均值的分布。
数据离散化:将连续数据转换为离散数据。
数据转换:将数据转换为适合特定算法的形式,如将日期转换为时间戳。
数据规约
数据立方体聚集:通过聚合数据来减少数据集的大小。
维度归约:通过删除不重要的特征来减少数据集的维度。
数据压缩:通过压缩数据来减少数据存储空间。
数值归约:通过合并相似的数据值来减少数据集的大小。
离散化和概念分层:将连续数据转换为离散数据,并按概念层次结构组织数据。
基于粗糙集理论的数据预处理

粗糙集理论是一种处理不精确、不确定知识的数学工具。以下是基于粗糙集理论的数据预处理方法:
属性约简:通过删除冗余属性来减少数据集的维度。
概念分层:将数据集中的概念按照层次结构组织。
基于概念树的数据浓缩
概念树是一种层次结构,用于组织数据集中的概念。以下是基于概念树的数据浓缩方法:
概念树构建:根据领域知识构建概念树。
概念树剪枝:删除不重要的概念,以减少数据集的大小。
基于信息论的数据预处理
信息论是一种研究信息传输和处理的数学理论。以下是基于信息论的数据预处理方法:
信息增益:根据信息增益选择重要的特征。
信息增益率:根据信息增益率选择重要的