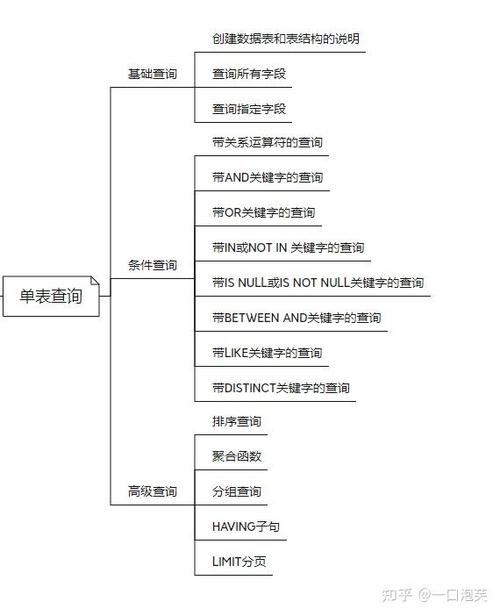
处理大数据是一个涉及多个步骤的复杂过程,包括数据的收集、存储、管理、分析和可视化等。下面是一些处理大数据的基本步骤:
1. 数据收集: 确定需要收集的数据类型和来源。 使用合适的数据收集工具和技术(如API、Web爬虫、传感器数据等)。 确保数据的质量和完整性。
2. 数据存储: 根据数据的大小和访问需求选择合适的存储方案(如关系型数据库、NoSQL数据库、数据湖等)。 使用分布式存储系统(如Hadoop HDFS)来处理大规模数据集。
3. 数据管理: 对数据进行清洗、转换和集成,以消除错误和不一致。 使用数据管理工具(如Apache Hive、Pig等)来组织和查询数据。
4. 数据分析: 应用统计分析和机器学习算法来发现数据中的模式和趋势。 使用数据挖掘和预测建模技术来提取有价值的信息。
5. 数据可视化: 使用数据可视化工具(如Tableau、Power BI、D3.js等)来将数据转化为易于理解的图表和图形。 帮助用户更好地理解数据,并支持决策制定。
6. 数据安全: 确保数据的安全性和隐私性,遵守相关的法律法规。 使用加密、访问控制和审计日志等技术来保护数据。
7. 持续监控和优化: 定期监控大数据处理系统的性能和效率。 根据反馈和需求调整数据处理流程和算法。
8. 人才培养和团队协作: 培养具有大数据处理技能的专业人才。 建立跨部门的数据团队合作,共同推动大数据项目的成功。
处理大数据需要综合运用多种技术和工具,并且需要不断学习和适应新的技术趋势。同时,还需要关注数据伦理和隐私保护,确保数据的合法合规使用。
大数据处理:挑战与策略

在当今信息爆炸的时代,大数据已经成为企业、政府和研究机构的重要资产。如何有效地处理这些海量数据,提取有价值的信息,成为了一个亟待解决的问题。本文将探讨大数据处理的挑战以及相应的策略。
一、大数据处理的挑战
1. 数据量庞大:大数据的特点之一是数据量巨大,这给存储、传输和处理带来了巨大的挑战。
2. 数据类型多样:大数据不仅包括结构化数据,还包括半结构化和非结构化数据,这使得数据处理变得更加复杂。
3. 数据质量参差不齐:由于数据来源的多样性,数据质量参差不齐,需要进行数据清洗和预处理。
4. 数据隐私和安全:在处理大数据时,如何保护个人隐私和数据安全是一个重要的问题。
二、大数据处理的策略
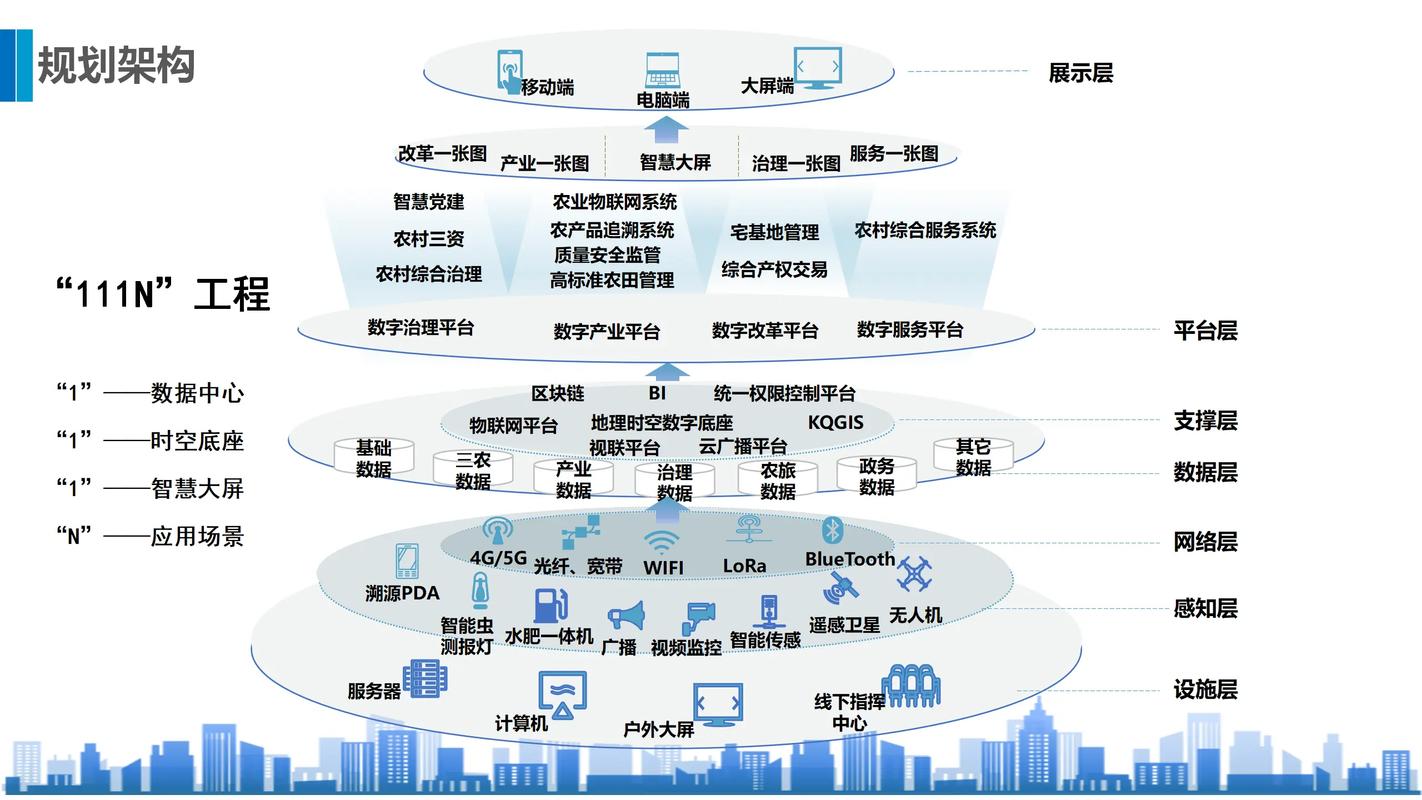
1. 分布式存储:采用分布式存储系统,如Hadoop的HDFS,可以有效地存储海量数据。
2. 分布式计算:利用分布式计算框架,如Hadoop的MapReduce和Spark,可以并行处理大规模数据集。
3. 数据清洗和预处理:通过数据清洗和预处理,提高数据质量,为后续分析打下基础。
4. 数据挖掘和机器学习:运用数据挖掘和机器学习技术,从海量数据中提取有价值的信息。
5. 数据可视化:通过数据可视化,将复杂的数据以直观的方式呈现,便于理解和分析。
6. 数据安全和隐私保护:采用加密、访问控制等技术,确保数据安全和隐私。
三、大数据处理工具
1. Hadoop:一个开源的分布式计算框架,用于存储和处理大规模数据集。
2. Spark:一个快速、通用的大数据处理引擎,支持多种编程语言。
3. Hive:一个基于Hadoop的数据仓库工具,用于数据分析和查询。
4. Impala:一个高性能的SQL查询引擎,用于Hadoop数据。
5. Kafka:一个分布式流处理平台,用于构建实时数据管道和流应用程序。
四、大数据处理案例
1. 智能推荐系统:通过分析用户行为数据,为用户推荐感兴趣的商品或内容。
2. 金融风控:通过分析交易数据,识别潜在的风险,降低金融风险。
3. 健康医疗:通过分析医疗数据,为患者提供个性化的治疗方案。
4. 智能交通:通过分析交通数据,优化交通流量,提高道路通行效率。
大数据处理是一个复杂的过程,需要综合考虑数据量、数据类型、数据质量、数据安全和隐私等多个因素。通过采用合适的策略和工具,可以有效地处理大数据,为企业、政府和研究机构创造价值。