3. Apache Flink 介绍:一个开源流处理框架,用于实时数据处理和分析。 应用砛n4. ClickHouse 介绍:一个用于在线分析处理(OLAP)的列式数据库管理系统,能够快速处理和分析大量数据。 应用砛n5. DataSphere Studio 介绍:微众银行自研的数据应用开发管理集成框架,支持数据交换、脱敏清洗、分析挖掘、质量检测、可视化展现、定时调度到数据输出应用等全流程砛n6. Apache Beam 介绍:一个统一的数据处理模型,支持批处理和流处理。 应用砛n7. Apache Atlas 介绍:一个数据治理开源框架,用于支持数据管理团队在整个组织中协作管理大数据资产和元数据。 特点:可扩展的数据模型和高度集成的管理解决方案。
8. 飞象大数据分析平台(OpenFEA) 介绍:一款国产开源的一站式大数据敏捷分析平台,结合了 AI 和 BI 技术。 应用砛n这些项目涵盖了大数据的各个方面,从分布式存储和处理到数据分析和可视化,适合不同层次的技术人员和开发者的需求。希望这些推荐对你有所帮助。
探索大数据领域的开源项目:助力企业高效数据处理与分析
随着大数据时代的到来,企业对海量数据的处理和分析需求日益增长。开源项目因其灵活性和成本效益,成为大数据领域的重要解决方案。本文将介绍几个在大数据领域具有影响力的开源项目,帮助读者了解这些项目的基本功能和优势。
Apache Hadoop:大数据处理的开山鼻祖

Apache Hadoop是最早的大数据开源项目之一,由Apache软件基金会维护。它提供了一套完整的分布式存储和计算框架,能够高效地处理海量数据。Hadoop的核心组件包括HDFS(Hadoop Distributed File System,分布式文件系统)和MapReduce(一种编程模型,用于大规模数据集的并行运算)。
HDFS负责存储海量数据,采用分布式存储方式,将数据分散存储在多个节点上,提高了数据的可靠性和扩展性。MapReduce则负责数据的并行处理,将大规模数据集分解成多个小任务,在多个节点上并行执行,最终合并结果。
Apache Spark:大数据处理与分析的利器
Apache Spark是继Hadoop之后,大数据领域又一重要的开源项目。Spark提供了丰富的数据处理和分析功能,包括实时数据处理、SQL、图计算、机器学习等。Spark的核心组件包括Spark Core、Spark SQL、Spark Streaming、MLlib和GraphX。
Spark Core是Spark的基础框架,提供了内存计算和弹性分布式数据集(RDD)等核心功能。Spark SQL允许用户使用SQL查询大数据集,简化了数据处理和分析过程。Spark Streaming提供了实时数据处理能力,可以实时处理和分析数据流。MLlib提供了机器学习算法库,GraphX则专注于图处理。
Apache Kafka:分布式流处理平台
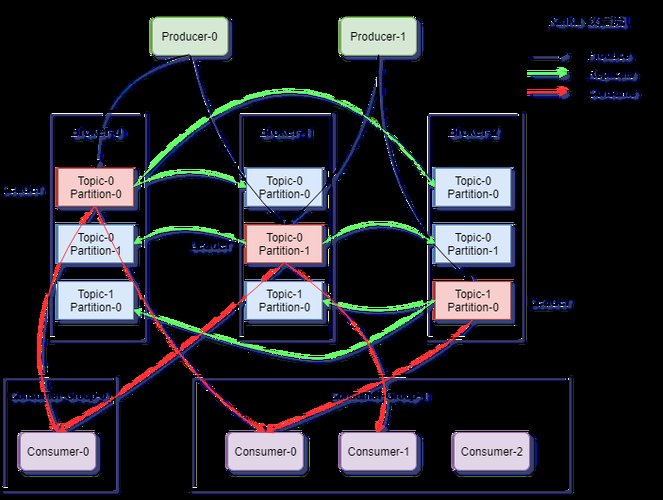
Apache Kafka是一个分布式流处理平台,主要用于构建实时数据流应用。Kafka具有高吞吐量、可扩展性和容错性等特点,适用于处理大规模数据流。Kafka的核心组件包括生产者(Producer)、消费者(Consumer)、主题(Topic)和分区(Partition)。
生产者负责将数据发送到Kafka,消费者负责从Kafka中读取数据。主题是Kafka中的数据分类,每个主题可以包含多个分区。Kafka通过分区机制,实现了数据的水平扩展和负载均衡。
Apache Flink:实时流处理框架
Apache Flink是一个流处理框架,专注于实时数据处理。Flink提供了高效、可扩展和可靠的流处理解决方案,适用于各种实时应用场景。Flink的核心组件包括DataStream API、Table API和Flink SQL。
DataStream API允许用户使用Java或Scala编写流处理程序,Table API和Flink SQL则提供了类似SQL的查询语言,简化了数据处理和分析过程。
Pentaho Big Data Plugin:大数据集成利器
Pentaho Big Data Plugin是一个开源项目,旨在为Pentaho生态系统中的大数据社区提供支持。该项目是一个Kettle插件,可以在Pentaho Data Integration(Kettle)、Pentaho Reporting和Pentaho BI平台中使用。它支持与多种大数据项目的交互,如Hadoop、Hive、HBase、Cassandra、MongoDB等。
Pentaho Big Data Plugin的核心功能是为Kettle引擎提供与大数据平台的集成支持,使用户能够在Pentaho生态系统中轻松地与这些大数据平台进行数据处理和分析。
大数据开源项目为企业和开发者提供了丰富的数据处理和分析工具。本文介绍了几个具有代表性的开源项目,包括Apache Hadoop、Apache Spark、Apache Kafka、Apache Flink和Pentaho Big Data Plugin。了解这些项目的基本功能和优势,有助于企业选择合适的技术方案,提高数据处理和分析效率。