
模式识别和机器学习是计算机科学和人工智能领域中两个紧密相关的概念。它们都涉及到让计算机系统从数据中学习并做出决策或预测。下面是这两个概念的一些基本介绍:
模式识别
模式识别是人工智能的一个重要分支,它涉及到通过某种方式识别出数据中的模式或规律。这通常是通过将数据分类到不同的类别中来实现的。模式识别可以应用于许多领域,如语音识别、图像识别、生物识别等。
模式识别的基本步骤包括:
1. 数据采集:收集需要分析的数据。2. 预处理:对数据进行清洗、归一化等处理,以便更好地进行分析。3. 特征提取:从数据中提取出有用的特征,这些特征可以用来区分不同的类别。4. 分类:使用机器学习算法对数据进行分类,将数据分配到不同的类别中。5. 评估:评估分类器的性能,如准确率、召回率等。
机器学习
机器学习是人工智能的一个子领域,它涉及到让计算机系统从数据中学习并做出决策或预测。机器学习算法可以通过训练数据来学习,然后使用这些学习到的知识来处理新的数据。
机器学习可以分为以下几种类型:
模式识别与机器学习的关系
模式识别和机器学习是相互关联的。模式识别通常使用机器学习算法来实现,而机器学习算法也可以用于模式识别任务。例如,在图像识别中,可以使用机器学习算法来训练模型,然后使用这个模型来识别图像中的对象。
总的来说,模式识别和机器学习是人工智能领域中两个非常重要的概念,它们在许多领域都有广泛的应用。
模式识别与机器学习概述

模式识别是人工智能领域的一个重要分支,它涉及从数据中提取有用信息,识别和分类模式。随着大数据时代的到来,模式识别在各个领域都得到了广泛应用。机器学习则是实现模式识别的关键技术,它通过算法让计算机从数据中学习,从而实现自动识别和分类。
模式识别的基本概念
模式识别的基本任务是从给定的数据集中提取有用的信息,并对其进行分类或聚类。模式识别通常包括以下几个步骤:
数据预处理:对原始数据进行清洗、转换和标准化,以提高后续处理的质量。
特征提取:从数据中提取有助于分类或聚类的特征。
模式分类:根据提取的特征对数据进行分类。
模式聚类:将相似的数据点归为一类。
机器学习的基本概念

机器学习是使计算机从数据中学习的一种方法。它通过算法让计算机从数据中自动提取规律,从而实现智能决策。机器学习可以分为以下几种类型:
监督学习:通过已标记的训练数据,让计算机学习如何对新的数据进行分类或回归。
无监督学习:通过未标记的数据,让计算机自动发现数据中的规律和结构。
半监督学习:结合监督学习和无监督学习,利用少量标记数据和大量未标记数据来训练模型。
强化学习:通过奖励和惩罚机制,让计算机在特定环境中学习最优策略。
模式识别与机器学习的应用领域
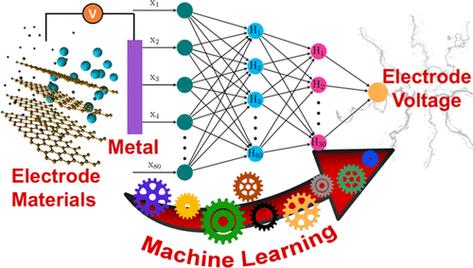
模式识别与机器学习在各个领域都有广泛的应用,以下列举一些典型应用:
图像识别:如人脸识别、指纹识别、车牌识别等。
语音识别:如语音助手、语音翻译等。
自然语言处理:如机器翻译、情感分析、文本分类等。
医疗诊断:如疾病预测、药物研发、医学影像分析等。
金融风控:如信用评分、欺诈检测、投资策略等。
模式识别与机器学习的挑战

尽管模式识别与机器学习在各个领域取得了显著成果,但仍面临一些挑战:
数据质量:数据质量对模式识别与机器学习的效果至关重要。噪声、缺失值和异常值等都会影响模型的性能。
特征工程:特征工程是模式识别与机器学习中的关键步骤。如何选择合适的特征,以及如何对特征进行预处理,对模型的性能有很大影响。
过拟合与欠拟合:过拟合和欠拟合是机器学习中的常见问题。过拟合会导致模型在训练数据上表现良好,但在测试数据上表现不佳;欠拟合则会导致模型在训练数据和测试数据上都表现不佳。
计算复杂度:随着数据量的增加,模式识别与机器学习的计算复杂度也会增加。如何提高计算效率,是一个值得关注的课题。
模式识别与机器学习是人工智能领域的重要分支,它们在各个领域都取得了显著成果。仍面临一些挑战。随着技术的不断进步,相信模式识别与机器学习将在未来发挥更大的作用。
模式识别 机器学习 人工智能 数据预处理 特征提取 分类 聚类 监督学习 无监督学习 应用领域 挑战








