Java大数据通常指的是使用Java编程语言来处理和分析大规模数据集的技术和工具。Java作为一种广泛使用的高级编程语言,具有跨平台性、稳定性和丰富的库支持,因此在处理大数据时具有很大的优势。
在大数据领域,Java常用于以下几个方面:
1. 数据存储与处理:Java可以用于构建大数据存储系统,如Hadoop生态系统中的HDFS(Hadoop Distributed File System)和HBase等。这些系统可以处理和存储大规模的数据集。
2. 数据处理框架:Apache Spark是一个基于Java的快速、通用的大数据处理引擎,它提供了高效的数据处理和机器学习功能。Spark可以与Hadoop无缝集成,用于处理和分析存储在HDFS中的数据。
3. 数据流处理:Apache Kafka是一个高吞吐量的分布式发布订阅消息系统,它可以用于构建实时的数据流处理系统。Kafka使用Java编写,并支持与Java的集成。
4. 数据挖掘与机器学习:Java提供了多种数据挖掘和机器学习库,如Weka、Mahout等,这些库可以用于构建数据挖掘和机器学习应用。
5. 大数据可视化:Java也可以用于构建大数据可视化工具,如Tableau、Elasticsearch等,这些工具可以帮助用户以图形化的方式展示和分析大数据。
总之,Java大数据指的是使用Java编程语言和相关技术来处理、分析和展示大规模数据集的技术和工具。Java在大数据领域的应用非常广泛,涵盖了数据存储、处理、分析、可视化等多个方面。
什么是Java大数据?
Java大数据的特点
Java大数据具有以下特点:
海量数据:Java大数据技术能够处理PB级别的数据量,满足企业对海量数据的存储、处理和分析需求。
多样性:Java大数据技术支持多种数据类型,包括结构化数据、半结构化数据和非结构化数据,能够满足不同场景下的数据处理需求。
实时性:Java大数据技术支持实时数据处理,能够快速响应业务需求,提高业务效率。
可扩展性:Java大数据技术采用分布式架构,具有良好的可扩展性,能够根据业务需求进行水平扩展。
Java大数据技术架构
Java大数据技术架构主要包括以下几个层次:
数据采集层:负责从各种数据源采集数据,如日志文件、数据库、传感器等。
数据存储层:负责存储海量数据,如Hadoop、HBase、Cassandra等。
数据处理层:负责对数据进行处理和分析,如MapReduce、Spark、Flink等。
数据应用层:负责将处理后的数据应用于实际业务场景,如数据挖掘、机器学习、可视化等。
Java大数据常用工具
Java大数据领域常用的工具包括:
Hadoop:一个开源的分布式计算框架,用于处理大规模数据集。
Spark:一个开源的分布式计算系统,用于大规模数据处理和分析。
HBase:一个分布式、可扩展的NoSQL数据库,用于存储大规模数据。
Flume:一个分布式、可靠的数据收集系统,用于收集、聚合和移动大量日志数据。
Kafka:一个分布式流处理平台,用于构建实时数据管道和流应用程序。
Java大数据应用场景
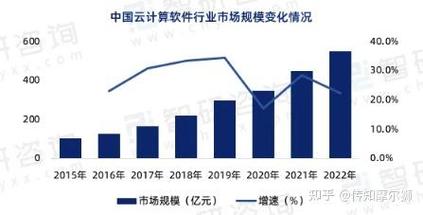
金融行业:用于风险控制、欺诈检测、信用评估等。
电商行业:用于用户行为分析、推荐系统、精准营销等。
医疗行业:用于疾病预测、患者画像、药物研发等。
物联网:用于设备监控、数据分析、智能决策等。
Java大数据发展趋势
随着技术的不断发展和创新,Java大数据领域呈现出以下发展趋势:
实时性:实时数据处理和分析将成为主流,满足企业对实时业务的需求。
智能化:人工智能、机器学习等技术将与大数据技术深度融合,实现更智能的数据分析。
开源生态:开源技术将继续在Java大数据领域发挥重要作用,推动技术发展。
行业应用:Java大数据技术将在更多行业得到应用,推动行业数字化转型。
Java大数据技术作为处理和分析海量数据的重要手段,在各个行业都发挥着重要作用。随着技术的不断发展和创新,Java大数据领域将迎来更加广阔的发展前景。