
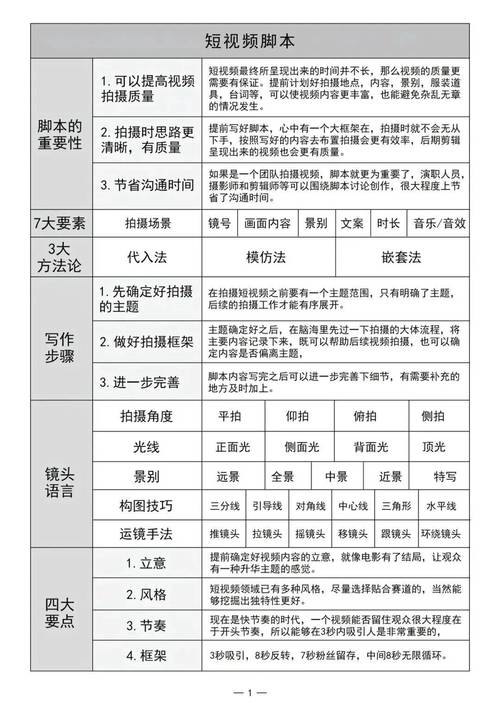
两个数据库同步数据通常涉及到以下几个步骤:
1. 确定同步需求: 需要同步哪些数据? 同步的频率(实时、定时等)? 同步的方向(单向、双向)?
2. 选择同步工具或方法: 使用数据库自带的同步功能(如MySQL的Replication)。 使用第三方数据同步工具(如Talend、Informatica等)。 自行编写脚本(如使用Python、Shell等)。
3. 建立连接: 确保两个数据库都能互相访问。 配置相应的用户名和密码。
4. 设计同步逻辑: 确定哪些数据需要被同步。 设计数据同步的触发条件(如基于时间戳、基于数据变化等)。 考虑数据冲突的处理机制(如优先级、版本控制等)。
5. 测试同步过程: 在测试环境中进行同步,确保数据能够正确地从一个数据库传输到另一个数据库。 检查同步过程中可能出现的错误或异常情况。
6. 部署和监控: 将同步逻辑部署到生产环境中。 设置监控系统,实时监控同步状态,及时发现并解决问题。
7. 维护和优化: 定期检查同步日志,确保同步过程正常运行。 根据实际使用情况,对同步逻辑进行调整和优化。
请注意,具体的实现步骤和工具选择可能会因数据库类型、数据规模、同步需求等因素而有所不同。在进行数据同步时,还需要考虑到数据的安全性和隐私性,确保同步过程不会泄露敏感信息。
两个数据库同步数据:方法与最佳实践
在当今的信息化时代,数据同步已成为企业级应用中不可或缺的一部分。两个数据库之间的数据同步不仅能够保证数据的一致性,还能提高系统的可靠性和可用性。本文将详细介绍两种常见的数据库同步方法,并探讨其最佳实践。
一、数据库同步方法
1.1 使用ETL工具
ETL工具同步

ETL(Extract, Transform, Load)工具是一种专门用于数据提取、转换和加载的工具。它能够从源数据库中提取数据,进行计算和处理,然后将数据加载到目标数据库。
操作步骤:
提取数据:从源数据库提取数据。
转换数据:在ETL工具中进行计算和处理。
加载数据:将处理后的数据同步到目标数据库。
常用ETL工具:
Apache Nifi
Talend
Apache Airflow
Informatica
1.2 数据库触发器

数据库触发器同步
数据库触发器是一种在源数据库中设置的特殊程序,当数据发生变化时,自动进行计算处理并更新到目标数据库。
操作步骤:
创建触发器:在源数据库中创建触发器,当数据变化时触发计算处理。
编写触发器逻辑:在触发器中编写计算和同步逻辑,将结果更新到目标数据库。
注意事项:
触发器适合实时处理小量数据,对于大规模数据处理效率较低。
1.3 自定义脚本
自定义脚本同步
编写自定义脚本,定期从源数据库提取数据,进行计算处理后,同步到目标数据库。
操作步骤:
编写脚本:编写脚本(如Python、Bash),从源数据库提取数据,进行计算处理。
连接数据库:在脚本中配置源和目标数据库连接。
处理数据:在脚本中进行计算处理。
同步数据:将处理后的数据插入到目标数据库。
计划任务:使用任务调度工具(如cron)定期运行脚本。
常用脚本语言:
Python脚本(使用库如pandas、SQLAlchemy)
Shell脚本
PowerShell脚本
1.4 数据流处理平台
数据流处理平台同步

使用数据流处理平台,如Apache Kafka,进行实时数据处理和同步。
操作步骤:
配置数据源:将源数据库的数据推送到数据流处理平台。
处理数据:在数据流处理平台中进行数据处理和转换。
同步数据:将处理后的数据推送到目标数据库。
二、最佳实践
2.1 选择合适的同步方法
根据实际需求选择合适的同步方法,如数据量、实时性、准确性等因素。
2.2 确保数据一致性

在同步过程中,确保数据的一致性,避免数据丢失或重复。
2.3 监控同步状态

定期监控同步状态,及时发现并解决同步过程中出现的问题。
2.4 安全性考虑
在同步过程中,确保数据传输的安全性,避免数据泄露。
两个数据库同步数据是保证数据一致性和系统可靠性的重要手段。本文介绍了常见的数据库同步方法,并探讨了最佳实践。在实际应用中,根据具体需求选择合适的同步方法,并遵循最佳实践,能够有效提高数据同步的效率和可靠性。







