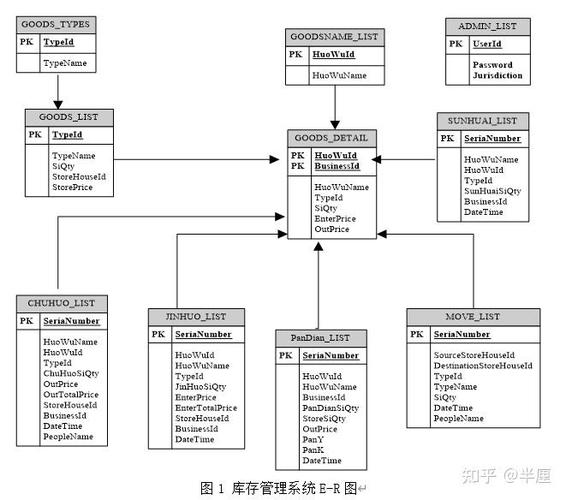
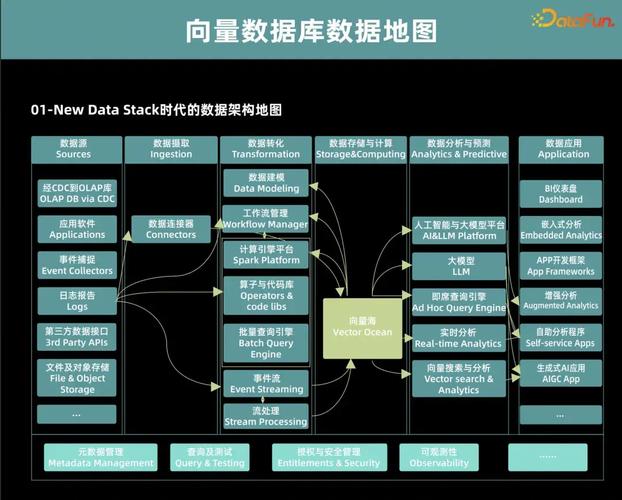
向量数据库的工作原理主要基于向量搜索技术,它允许高效地存储和检索高维空间中的数据点。这种数据库类型在处理复杂数据集,特别是涉及图像、音频、文本等非结构化数据的相似性搜索时非常有效。以下是向量数据库的一些关键组件和它们的工作原理:
1. 数据表示: 向量数据库中的数据通常表示为高维向量。这些向量可以是原始数据(如文本、图像或音频的嵌入表示)或者通过某种算法(如词嵌入、卷积神经网络或循环神经网络)转换而来的。
2. 索引结构: 向量数据库使用特定的索引结构来高效地存储和检索向量。常见的索引结构包括局部敏感哈希(LSH)、倒排索引、树状索引(如KD树、球树)等。这些索引结构设计用于快速找到与查询向量最相似的数据点。
3. 相似性度量: 向量数据库使用相似性度量来确定向量之间的相似度。常用的相似性度量包括余弦相似度、欧几里得距离、曼哈顿距离等。选择合适的相似性度量取决于具体的应用场景和数据类型。
4. 查询处理: 当用户提交一个查询向量时,向量数据库会使用索引结构来快速定位与查询向量最相似的数据点。这个过程可能涉及多个步骤,包括向量转换、相似性度量计算和结果排序。
5. 优化: 为了提高查询性能,向量数据库可能会采用各种优化技术,如批量查询、近似最近邻搜索(ANN)和缓存策略。这些优化技术旨在减少计算开销并提高响应速度。
6. 支持向量运算: 向量数据库通常提供对向量运算的支持,如向量加法、向量乘法、点积和向量归一化等。这些运算对于许多机器学习和数据分析任务至关重要。
7. 可扩展性: 向量数据库设计为可扩展的,以便能够处理大规模数据集和复杂的查询。这可能涉及分布式存储、负载均衡和故障转移等技术。
8. 多模态支持: 一些向量数据库支持多模态数据,这意味着它们可以同时处理不同类型的数据(如图像、文本和音频)。这种能力对于构建复杂的机器学习模型和数据分析应用非常有用。
总之,向量数据库通过高效的数据表示、索引结构和相似性度量技术,为处理高维空间中的数据提供了强大的支持。它们在许多领域,如推荐系统、图像搜索、自然语言处理和计算机视觉中发挥着关键作用。
向量数据库的工作原理
随着大数据和人工智能技术的快速发展,向量数据库作为一种新型的数据库技术,逐渐成为数据存储和检索的重要工具。本文将深入探讨向量数据库的工作原理,帮助读者更好地理解这一技术。
一、什么是向量数据库

向量数据库是一种专门用于存储和检索高维空间中向量数据的数据库。与传统的关系型数据库不同,向量数据库的核心在于对向量数据的存储、索引和查询。它广泛应用于图像识别、语音识别、推荐系统等领域。
二、向量数据库的工作原理

向量数据库的工作原理主要包括以下几个步骤:
1. 数据存储
向量数据库将向量数据以二进制形式存储在磁盘上。每个向量由多个维度组成,每个维度对应一个特征。例如,一个图像的向量可能包含颜色、形状、纹理等特征。
2. 向量索引
为了提高查询效率,向量数据库需要对向量数据进行索引。常见的索引方法包括:
IVF(Inverted File)索引:将向量数据分成多个簇,通过查询最接近簇的向量来提高搜索效率。
LSH(Locality Sensitive Hashing)索引:将向量数据映射到哈希空间,通过比较哈希值来查找相似向量。
FAISS(Facebook AI Similarity Search)索引:一种高效的相似性搜索算法,适用于大规模向量数据。
3. 向量查询
向量查询是向量数据库的核心功能。用户可以通过输入一个查询向量,数据库会根据索引方法快速找到与查询向量最相似的向量。常见的查询方法包括:
相似度查询:根据查询向量和数据库中向量的相似度,返回相似度最高的向量。
范围查询:根据查询向量和数据库中向量的距离,返回距离在一定范围内的向量。
三、向量数据库的优势
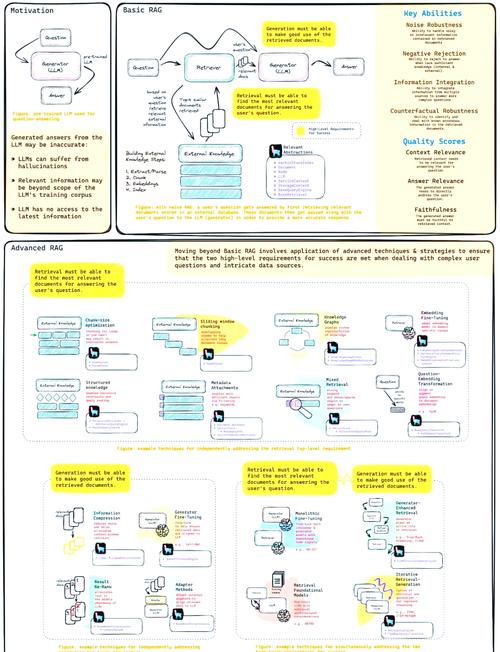
向量数据库具有以下优势:
高效:向量数据库通过索引和查询优化,能够快速检索相似向量,提高查询效率。
灵活:向量数据库支持多种索引和查询方法,可以根据实际需求选择合适的方案。
可扩展:向量数据库能够处理大规模向量数据,支持分布式存储和计算。
四、向量数据库的应用场景
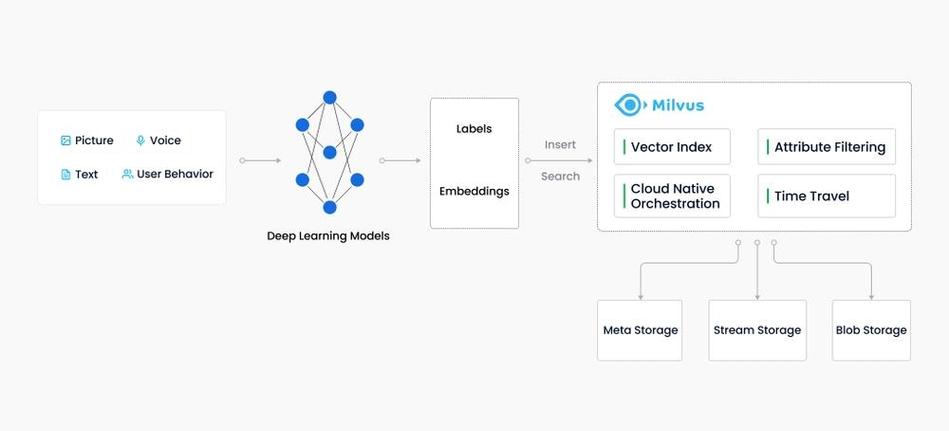
向量数据库在以下领域具有广泛的应用:
图像识别:通过向量数据库存储和检索图像特征,实现图像分类、物体检测等功能。
语音识别:将语音信号转换为向量表示,通过向量数据库进行相似度查询,实现语音识别。
推荐系统:根据用户的历史行为和兴趣,通过向量数据库检索相似用户或物品,实现个性化推荐。
自然语言处理:将文本数据转换为向量表示,通过向量数据库进行语义相似度查询,实现文本分类、情感分析等功能。
向量数据库作为一种新型的数据库技术,在数据存储和检索方面具有显著优势。随着技术的不断发展,向量数据库将在更多领域发挥重要作用。
向量数据库, 数据存储, 索引, 查询, 图像识别, 语音识别, 推荐系统, 自然语言处理