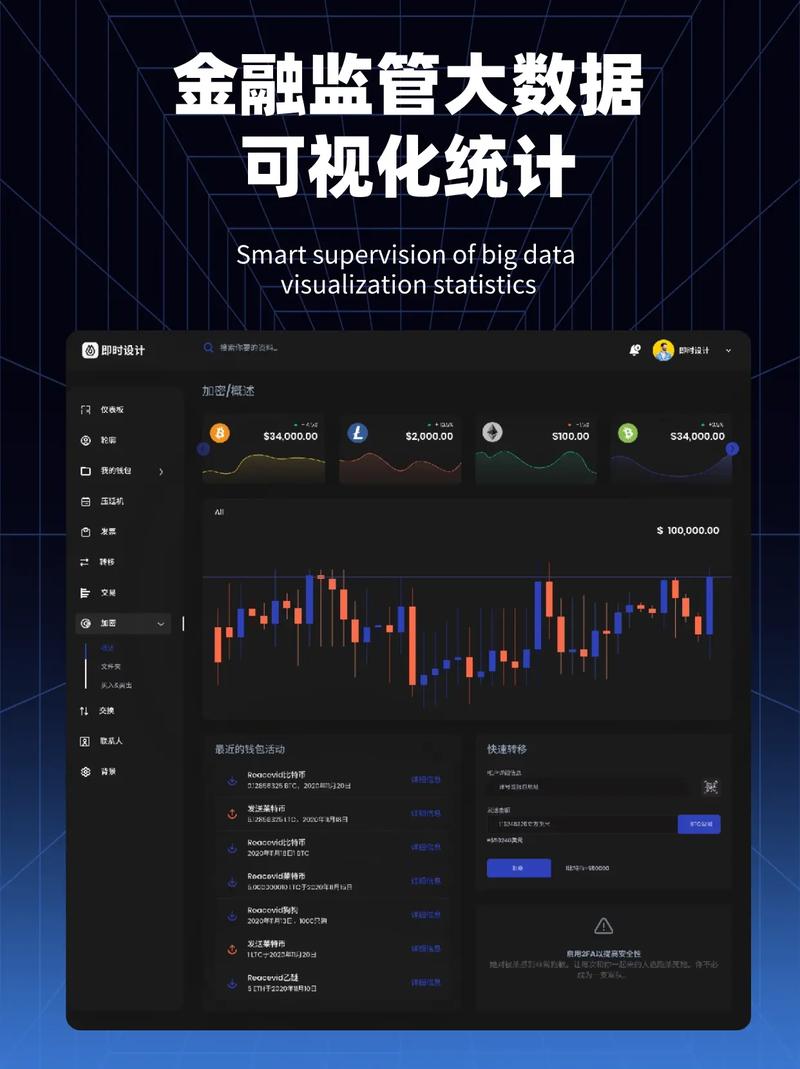
SAP HANA(全称SAP Highperformance ANalytic Appliance)是由SAP开发的一款高性能分析工具,它将数据存储在内存中,而不是传统的硬盘上。这种内存数据库的设计使得数据处理速度大大提升,能够支持企业近乎零延迟地处理海量数据,并实现即时查询和由数据驱动的决策。
核心特点1. 内存计算:SAP HANA是一种内存计算型数据库,它将数据存储在计算机主内存(RAM)中,而不是传统的磁盘或固态硬盘(SSD)。这使得数据的读写速度极快,比传统磁盘快百万倍。2. 列式存储:SAP HANA采用了列式存储技术,这种存储方式特别适合于数据分析,因为它能够高效地处理大量数据的聚合和计算。3. 多模型支持:SAP HANA支持多种数据模型,包括关系型、图形、文本和空间数据,能够处理复杂的数据分析任务。4. 实时分析:SAP HANA能够进行实时分析和事务处理,集联机分析处理(OLAP)和联机事务处理(OLTP)于一体,处理速度远超市场上的其他数据库管理系统。5. 数据压缩和传输优化:SAP HANA采用数据字典的方法对数据进行压缩,减少了数据传输和存储的需求,提高了系统效率。
功能与用途SAP HANA不仅是一个数据库管理系统,它还集成了高级分析功能(如预测分析、空间数据处理、文本分析等)、ETL功能以及应用程序服务器。这使得它成为一个强大的平台,能够支持各种业务应用和数据分析需求。
应用场景 企业资源规划(ERP):SAP HANA可以用于优化ERP系统,提高数据处理速度和业务决策效率。 业务智能:通过SAP HANA,企业可以快速进行数据分析和报告,支持实时决策。 数据集成:SAP HANA能够集成来自不同来源的数据,支持数据仓库和大数据分析。
PGG.Han汉族基因组数据库:助力基因组研究的新里程碑
随着基因组测序技术的飞速发展,基因组研究已成为生物医学领域的重要分支。为了更好地服务于全球基因组研究,特别是针对汉族人群的研究,PGG.Han汉族基因组数据库应运而生。本文将详细介绍PGG.Han数据库的构建背景、功能特点及其在基因组研究中的应用价值。
在基因组研究领域,西方国家已经启动了多个大规模的基因组测序项目,如UK10K项目、爱沙尼亚基因组计划(EGP)和NHLBI精准医学跨组学(TOPMed)计划等。尽管一些基因组资源为东亚人群提供了数据支持,但汉族人群的研究相对较少。此外,全基因组关联研究(GWAS)主要在欧洲血统人群中开展,导致基因组研究的欧洲偏倚。因此,构建汉族人群特异性的群体基因组数据库具有重要意义。
PGG.Han数据库是基于114783个汉族的全基因组测序数据构建的。该数据库旨在提供以下功能:
汉族人群精细遗传结构可视化的交互界面
汉族亚群体的全基因组等位基因频率
基于祖先信息遗传标记(AIMs)面板的个体样本祖先推断和群体分层控制
基因型表型关联研究的群体结构共享数据(例如GWASs)
用于基因型填补的汉族人群特异性参考面板
PGG.Han数据库具有以下功能特点:
精细遗传结构可视化:数据库提供了交互界面,用户可以直观地了解汉族人群的遗传结构,包括群体分层、遗传变异等。
等位基因频率信息:数据库收录了汉族人群的详细等位基因频率信息,为研究基因变异与疾病的关系提供了重要数据支持。
祖先推断与群体分层控制:基于祖先信息遗传标记(AIMs)面板,数据库可以推断个体样本的祖先来源,并实现群体分层控制,提高研究结果的准确性。
群体结构共享数据:数据库提供了基因型表型关联研究的群体结构共享数据,有助于研究者开展跨群体研究。
基因型填补参考面板:针对汉族人群,数据库提供了特异性参考面板,有助于提高基因型填补的准确性。
PGG.Han数据库在基因组研究中的应用价值主要体现在以下几个方面:
促进汉族人群基因组研究:PGG.Han数据库为汉族人群的基因组研究提供了重要数据支持,有助于揭示汉族人群的遗传特征和疾病易感性。
推动个性化医疗发展:通过分析汉族人群的基因组数据,可以更好地了解个体差异,为个性化医疗提供依据。
促进跨群体研究:PGG.Han数据库提供了群体结构共享数据,有助于研究者开展跨群体研究,提高研究结果的普适性。
提高基因型填补准确性:针对汉族人群的特异性参考面板,有助于提高基因型填补的准确性,为后续研究提供更可靠的数据。
PGG.Han汉族基因组数据库的构建,为基因组研究提供了重要数据支持,有助于推动汉族人群基因组研究的发展。随着基因组测序技术的不断进步,PGG.Han数据库将继续发挥重要作用,为全球基因组研究贡献力量。