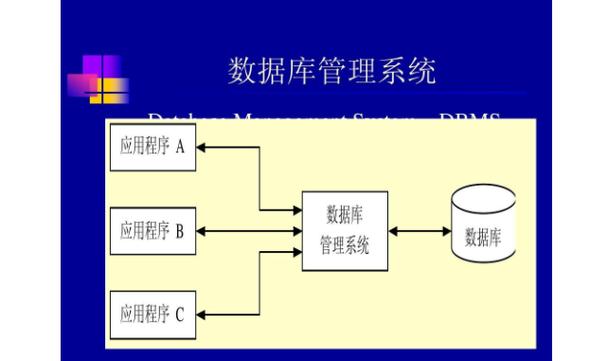
1. Hadoop:Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。它包括HDFS(Hadoop Distributed File System)和MapReduce两个主要组件。
2. Spark:Spark是一个快速、通用、开源的大数据处理引擎。它支持多种数据源,包括HDFS、Cassandra、HBase等,并提供了一个强大的编程模型,包括RDD(Resilient Distributed Dataset)和DataFrame。
3. NoSQL数据库:NoSQL数据库是一种非关系型数据库,用于存储和管理大规模、结构化或非结构化数据。常见的NoSQL数据库包括MongoDB、Cassandra、Redis等。
4. 数据挖掘:数据挖掘是一种从大量数据中提取有价值信息的过程。它通常包括数据预处理、数据挖掘算法、模型评估和可视化等方面。
5. 机器学习:机器学习是一种人工智能技术,用于从数据中学习模式和规律,并用于预测和决策。常见的机器学习算法包括决策树、支持向量机、神经网络等。
6. 数据可视化:数据可视化是一种将数据转换为图形或图像的技术,用于帮助人们更好地理解和分析数据。常见的可视化工具包括Tableau、Power BI、QlikView等。
7. 云计算:云计算是一种基于互联网的计算模式,提供按需分配的计算资源,包括服务器、存储、网络和软件等。常见的云计算平台包括AWS、Azure、Google Cloud等。
8. 数据仓库:数据仓库是一个用于存储和管理企业数据的中央存储库。它通常用于支持报告、分析和数据挖掘等业务需求。
9. 数据集成:数据集成是一种将来自不同来源的数据合并到一个统一的数据源中的过程。它通常包括数据抽取、转换和加载(ETL)等方面。
10. 数据治理:数据治理是一种确保数据质量和合规性的过程。它通常包括数据质量控制、数据安全管理、数据隐私保护等方面。
这些技术可以单独使用,也可以组合使用,以支持各种大数据应用。
大数据概述
大数据常用技术

1. 分布式计算技术
分布式计算技术是大数据处理的核心,它可以将大规模的数据集分散到多个节点上进行并行处理。常见的分布式计算技术包括:
Hadoop:Hadoop是一个开源的分布式计算框架,它包括HDFS(分布式文件系统)和MapReduce(分布式计算模型)等组件,用于存储和处理大规模数据集。
Spark:Spark是一个快速、通用的大数据处理引擎,它支持多种数据处理模式,如批处理、流处理和交互式查询。
Flink:Flink是一个流处理框架,它提供了高吞吐量和低延迟的实时数据处理能力。
2. 数据存储技术

Apache HBase:HBase是一个分布式、可扩展的NoSQL数据库,它建立在Hadoop之上,用于存储非结构化和半结构化数据。
Apache Cassandra:Cassandra是一个分布式、无中心的数据存储系统,它适用于处理大量数据和高并发访问。
MongoDB:MongoDB是一个面向文档的数据库,它适用于存储非结构化和半结构化数据,并提供了丰富的查询功能。
3. 数据处理与分析技术

Hive:Hive是一个基于Hadoop的数据仓库工具,它提供了类似SQL的查询语言,用于处理和分析大规模数据集。
Spark SQL:Spark SQL是Spark的一个组件,它提供了SQL查询接口和DataFrame API,用于处理和分析大规模数据集。
Apache Mahout:Mahout是一个机器学习库,它提供了多种机器学习算法,用于从数据中提取模式和洞察力。
4. 数据可视化技术
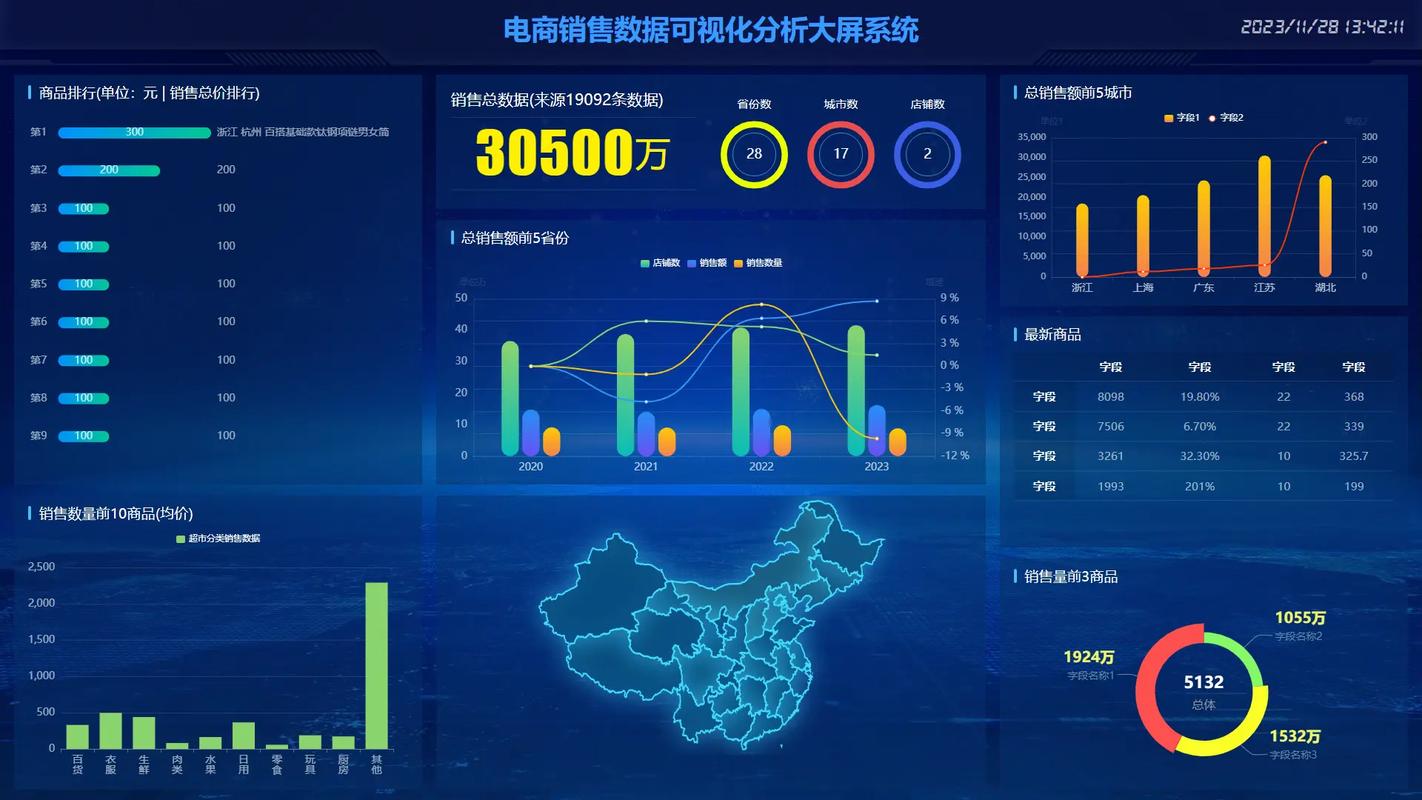
Tableau:Tableau是一个数据可视化工具,它提供了丰富的图表和仪表板,用于创建交互式数据可视化。
Power BI:Power BI是Microsoft的一个商业智能工具,它提供了数据连接、可视化和分析功能。
QlikView:QlikView是一个数据可视化工具,它提供了强大的数据探索和分析功能。
5. 云计算技术

AWS:Amazon Web Services提供了一系列云计算服务,包括弹性计算、存储、数据库和数据分析等。
Google Cloud Platform:Google Cloud Platform提供了一系列云计算服务,包括计算、存储、数据库和机器学习等。
Azure:Microsoft Azure提供了一系列云计算服务,包括计算、存储、数据库和人工智能等。
大数据技术正在不断发展和完善,为企业和组织提供了强大的数据处理和分析能力。掌握这些常用技术,有助于更好地应对大数据时代的挑战,挖掘数据价值,推动业务发展。