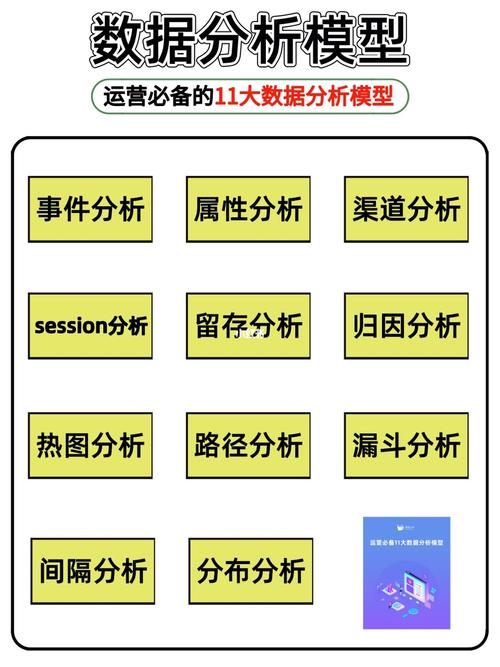
大数据建模是处理和分析大量数据以提取有价值信息的过程。随着大数据时代的到来,建模方法也在不断发展和演变。以下是几种常见的大数据建模方法:
1. 统计分析:统计分析是大数据建模中最基础的方法之一,它通过数据收集、处理、分析和解释来揭示数据中的规律和趋势。常用的统计分析方法包括描述性统计、推断性统计、回归分析、方差分析等。
2. 机器学习:机器学习是一种让计算机从数据中自动学习并改进性能的技术。在大数据建模中,机器学习方法被广泛应用于分类、回归、聚类、异常检测等任务。常见的机器学习算法包括决策树、支持向量机、随机森林、神经网络等。
3. 数据挖掘:数据挖掘是从大量数据中提取有价值信息和知识的过程。它通常涉及到数据预处理、数据挖掘算法选择、模型评估和解释等步骤。数据挖掘技术可以应用于市场分析、客户细分、推荐系统、欺诈检测等领域。
4. 深度学习:深度学习是机器学习的一个分支,它利用人工神经网络模拟人脑的工作原理,通过多层网络结构自动学习和提取数据中的特征。深度学习在图像识别、语音识别、自然语言处理等领域取得了显著的成果。
5. 图像处理:图像处理是针对图像数据进行建模和分析的过程。它包括图像预处理、特征提取、图像分类、目标检测等任务。图像处理技术在计算机视觉、医学影像分析、遥感等领域有广泛的应用。
6. 时间序列分析:时间序列分析是针对时间序列数据进行的建模和分析。它通常涉及到时间序列预测、时间序列分类、时间序列聚类等任务。时间序列分析在金融分析、天气预报、交通预测等领域有重要的应用。
7. 文本分析:文本分析是针对文本数据进行建模和分析的过程。它包括文本预处理、文本表示、文本分类、情感分析等任务。文本分析技术在自然语言处理、社交媒体分析、舆情监测等领域有广泛的应用。
8. 优化算法:优化算法是寻找最优解或近似最优解的方法。在大数据建模中,优化算法可以应用于资源分配、路径规划、调度优化等任务。常见的优化算法包括线性规划、整数规划、遗传算法等。
以上是几种常见的大数据建模方法,根据具体的应用场景和需求,可以选择合适的建模方法进行数据处理和分析。
大数据建模方法概述
随着信息技术的飞速发展,大数据已经成为各行各业关注的焦点。大数据建模方法作为大数据分析的核心,对于挖掘数据价值、辅助决策具有重要意义。本文将介绍几种常见的大数据建模方法,并分析其优缺点。
1. 机器学习建模方法
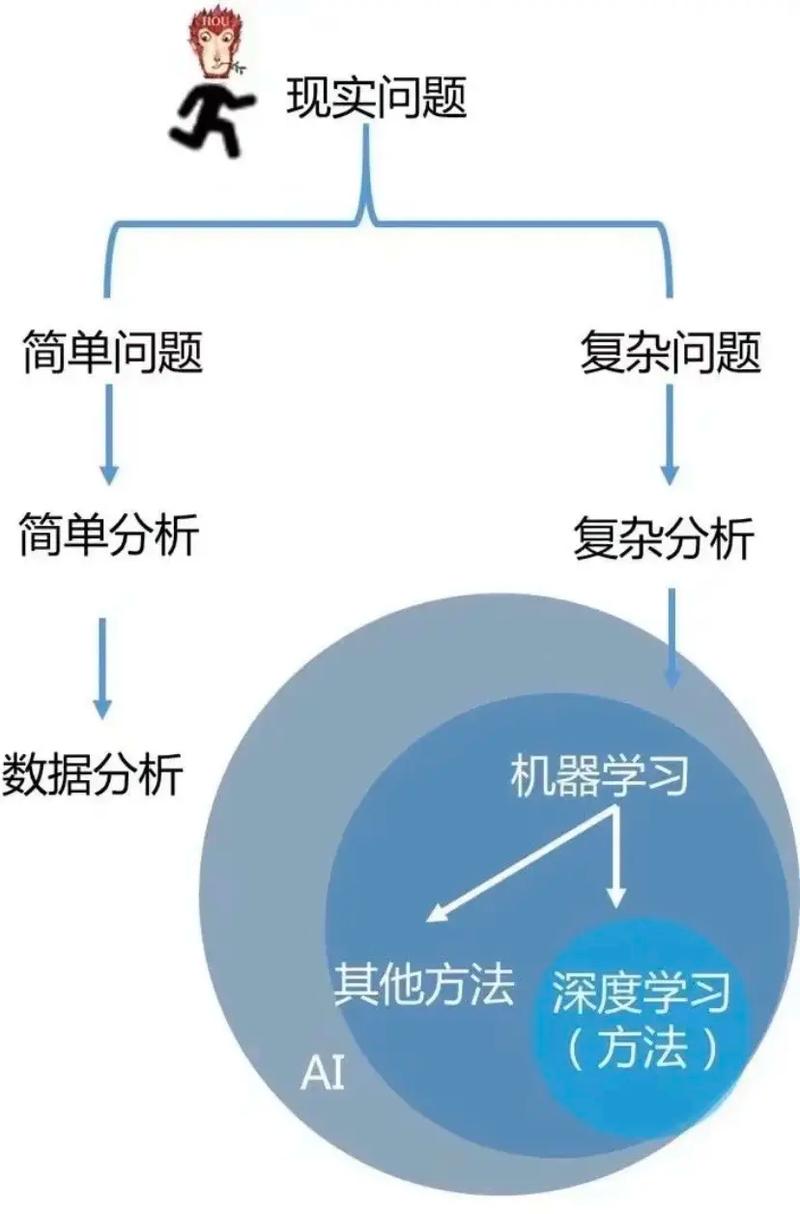
机器学习建模方法是通过算法自动从数据中学习规律,从而对未知数据进行预测或分类。以下是几种常见的机器学习建模方法:
1.1 线性回归
线性回归是一种简单的预测模型,通过拟合数据点与因变量之间的线性关系来预测目标值。其优点是易于理解和实现,但缺点是对于非线性关系的数据拟合效果较差。
1.2 逻辑回归
逻辑回归是一种用于分类问题的预测模型,通过拟合数据点与目标变量之间的逻辑关系来预测概率。其优点是能够处理非线性关系,且易于解释。
1.3 决策树
决策树是一种基于树形结构的预测模型,通过递归地将数据集划分为多个子集,并选择最优的特征进行分割。其优点是易于理解和实现,且能够处理非线性关系。
1.4 随机森林
随机森林是一种集成学习方法,通过构建多个决策树,并对预测结果进行投票来提高预测精度。其优点是能够处理非线性关系,且具有较好的泛化能力。
2. 关联规则挖掘方法
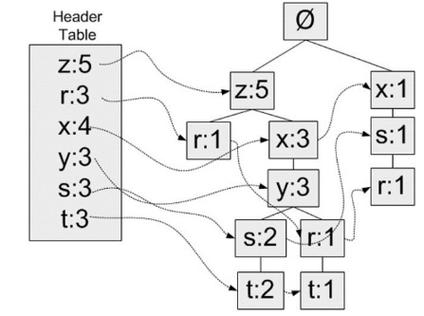
关联规则挖掘方法用于发现数据集中不同属性之间的关联关系。以下是几种常见的关联规则挖掘方法:
2.1 Apriori算法
Apriori算法是一种基于频繁项集的关联规则挖掘算法,通过迭代地生成频繁项集,并从中提取关联规则。其优点是易于理解和实现,但缺点是计算复杂度较高。
2.2 FP-growth算法
FP-growth算法是一种基于频繁模式树的关联规则挖掘算法,通过构建频繁模式树来减少计算复杂度。其优点是计算效率较高,且能够处理大数据集。
3. 聚类分析建模方法
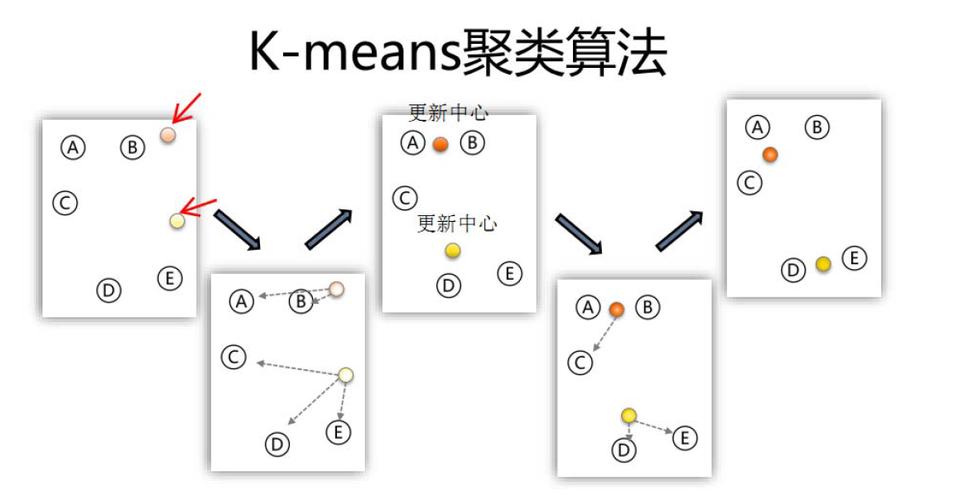
聚类分析是一种将数据集划分为若干个相似子集的建模方法。以下是几种常见的聚类分析建模方法:
3.1 K-means算法
K-means算法是一种基于距离的聚类算法,通过迭代地优化聚类中心,将数据点分配到最近的聚类中心。其优点是易于理解和实现,但缺点是对于初始聚类中心的选择敏感。
3.2 DBSCAN算法
DBSCAN算法是一种基于密度的聚类算法,通过计算数据点之间的距离,将数据点划分为不同的簇。其优点是能够处理噪声和异常值,且对于初始聚类中心的选择不敏感。
大数据建模方法在各个领域都有广泛的应用,本文介绍了机器学习、关联规则挖掘和聚类分析等几种常见的大数据建模方法。在实际应用中,应根据具体问题和数据特点选择合适的建模方法,以提高预测精度和决策效果。