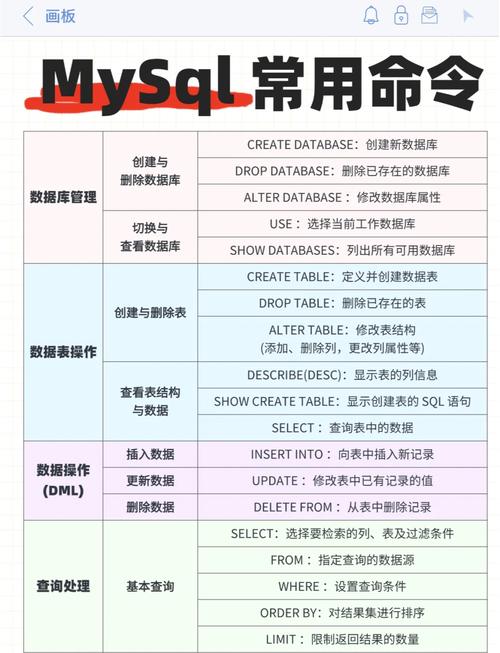
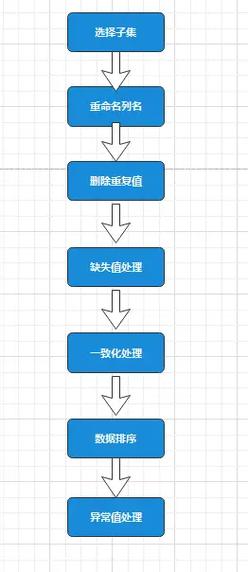
MySQL 数据清洗通常是指通过一系列的步骤来清理和整理数据库中的数据,以提高数据的质量和可用性。数据清洗可能包括以下步骤:
1. 识别数据问题:首先需要识别数据中存在的问题,如缺失值、重复值、异常值、格式不正确等。
2. 数据清理: 删除重复数据:使用 `DELETE` 语句结合 `GROUP BY` 和 `HAVING` 子句来删除重复的记录。 处理缺失值:可以使用 `COALESCE` 函数来替换缺失值,或者使用平均值、中位数等统计方法来填充缺失值。 修正数据格式:使用 `UPDATE` 语句结合 `STR_TO_DATE`、`DATE_FORMAT`、`REPLACE`、`CONCAT` 等函数来修正日期格式、字符串格式等。 删除或修正异常值:通过 `WHERE` 子句来识别和删除或修正异常值。
3. 数据标准化:将数据转换为统一的标准格式,如将所有日期转换为 `YYYYMMDD` 格式,将所有货币金额转换为同一货币单位等。
4. 数据验证:在数据清洗后,验证数据的完整性和准确性,确保清洗后的数据符合预期的质量标准。
5. 数据备份:在进行数据清洗之前,建议对原始数据进行备份,以便在出现问题时可以恢复。
6. 记录清洗过程:记录数据清洗的步骤和所做的更改,以便于跟踪和审计。
下面是一个简单的示例,展示了如何使用 MySQL 语句来删除重复数据:
```sqlDELETE FROM your_tableWHERE id NOT IN FROM your_table GROUP BY column_to_check_for_duplicatesqwe2;```
在这个示例中,`your_table` 是你要清理的表,`id` 是主键或唯一标识符,`column_to_check_for_duplicates` 是你想要检查重复值的列。
请注意,数据清洗是一个复杂的过程,可能需要根据具体的数据和需求来定制解决方案。在进行数据清洗之前,请确保你了解数据的结构和含义,以及清洗可能对业务产生的影响。
MySQL数据清洗:提升数据质量的关键步骤
在当今数据驱动的世界中,数据清洗是确保数据分析准确性和可靠性的关键步骤。MySQL作为一款广泛使用的开源数据库管理系统(DBMS),在数据清洗过程中扮演着重要角色。本文将详细介绍如何在MySQL中实现数据清洗,包括处理缺失值、异常值和重复值等常见问题。
一、数据清洗的重要性
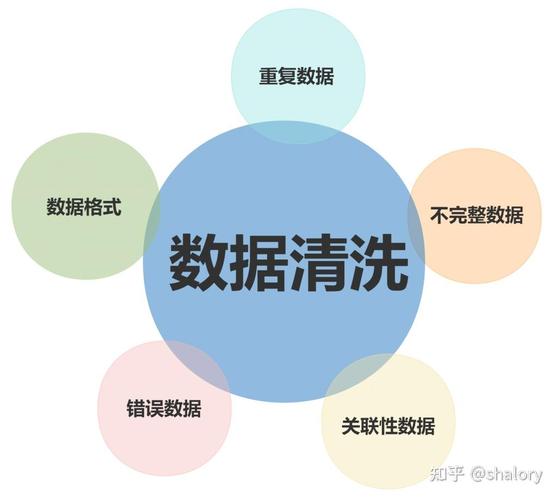
数据清洗是数据预处理的重要环节,它旨在识别和纠正数据中的错误、异常和不一致。以下是数据清洗的一些关键重要性:
提高数据质量:通过清洗数据,可以确保分析结果的准确性和可靠性。
减少错误:清洗数据可以减少因错误数据导致的分析错误。
节省时间:清洗数据可以减少后续分析过程中需要处理的数据量。
提高效率:清洗后的数据可以更快速地用于决策支持。
二、MySQL数据清洗的基本原则
在进行MySQL数据清洗时,以下原则应予以遵循:
备份原始数据:在开始清洗数据之前,确保备份原始数据,以防万一。
尽量不动原表:在清洗数据时,尽量避免直接修改原始数据表,而是创建新的数据表。
逐步清洗:将数据清洗过程分解为多个步骤,逐步处理缺失值、异常值和重复值。
三、处理缺失值

使用IFNULL()函数填充:使用MySQL的IFNULL()函数可以自动填充缺失值。
删除含有缺失值的行:如果缺失值对分析结果影响不大,可以考虑删除含有缺失值的行。
使用平均值、中位数或众数填充:对于数值型数据,可以使用平均值、中位数或众数填充缺失值。
四、处理异常值
使用统计学知识:利用统计学知识,如标准差、四分位数等,识别和剔除异常值。
可视化分析:通过图表和图形,直观地识别异常值。
使用专业工具:借助专业数据清洗工具,如Pandas、NumPy等,自动检测和剔除异常值。
五、处理重复值
使用DISTINCT关键字:使用MySQL的DISTINCT关键字可以去除重复值。
GROUP BY语句:使用GROUP BY语句可以对查询结果进行分组,只保留每个组中的第一行。
创建新表:创建一个新表,将重复值合并到一起,然后删除重复的行。
MySQL数据清洗是确保数据质量的关键步骤。通过遵循上述原则和方法,可以有效地处理缺失值、异常值和重复值,从而提高数据分析和挖掘的准确性和可靠性。在数据驱动的世界中,数据清洗是不可或缺的一环。