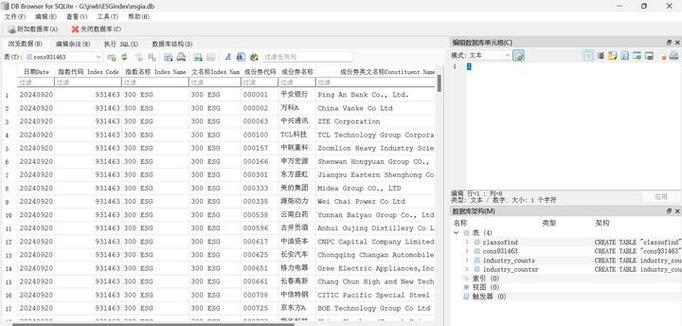
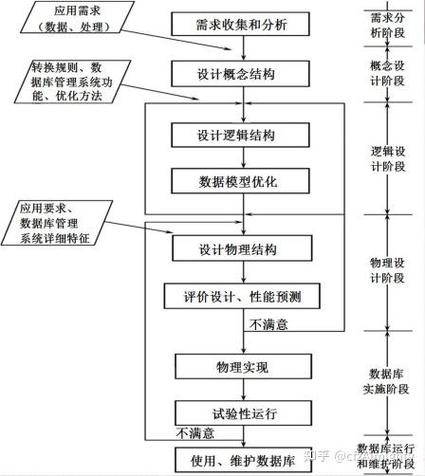
向量存储数据库(Vector Database)是一种专门用于存储和查询高维向量的数据库系统。在高维空间中,每个向量代表一个数据点,这些向量通常用于机器学习、图像识别、自然语言处理等领域。向量存储数据库的主要特点包括:
1. 高效的向量索引:为了快速查询相似向量,向量存储数据库通常使用专门的索引结构,如LSH(局部敏感哈希)、PQ(乘积量化)等,这些索引结构能够减少搜索空间,提高查询效率。
2. 支持向量搜索:向量存储数据库支持各种向量搜索操作,如最近邻搜索(Nearest Neighbor Search)、范围搜索(Range Search)等。这些操作可以帮助用户找到与给定查询向量最相似的向量。
3. 支持向量更新:向量存储数据库允许用户添加、删除或更新向量数据。这对于动态数据集或需要实时更新数据的应用场景非常重要。
4. 可扩展性:向量存储数据库需要能够处理大规模数据集,因此它们通常具有可扩展性,可以支持分布式存储和计算。
5. 支持多种向量格式:向量存储数据库支持多种向量格式,如浮点数、整数、稀疏向量等,以满足不同应用场景的需求。
6. 支持多种查询语言:向量存储数据库支持多种查询语言,如SQL、NoSQL等,以方便用户进行查询和数据分析。
7. 集成机器学习库:一些向量存储数据库还集成了机器学习库,如TensorFlow、PyTorch等,以便用户可以直接在数据库中进行机器学习模型的训练和预测。
8. 支持多种操作系统和编程语言:向量存储数据库通常支持多种操作系统和编程语言,以便用户可以在不同的环境中使用它们。
9. 高可用性:向量存储数据库需要具有高可用性,以支持关键业务应用。这通常通过数据备份、故障转移和负载均衡等技术实现。
10. 安全性:向量存储数据库需要具有安全性,以保护敏感数据。这通常通过访问控制、数据加密和审计等技术实现。
总之,向量存储数据库是一种专门用于存储和查询高维向量的数据库系统,它们具有高效、可扩展、支持多种查询操作等特点,广泛应用于机器学习、图像识别、自然语言处理等领域。
什么是向量存储数据库?
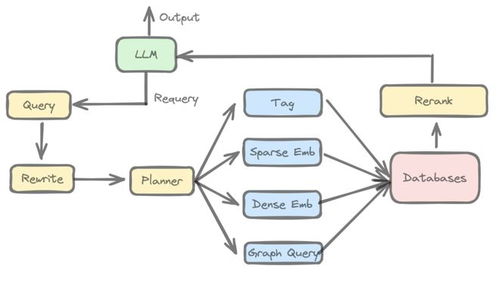
向量存储数据库,顾名思义,是一种专门用于存储和检索向量数据的数据库系统。在人工智能和机器学习领域,向量数据扮演着至关重要的角色。这类数据库能够高效地处理大规模的向量搜索和相似性比较任务,广泛应用于图像检索、推荐系统、自然语言处理等领域。
向量数据库的特点

与传统的关系型数据库相比,向量数据库具有以下特点:
向量数据模型:向量数据库采用向量数据模型来存储数据,将每个数据项表示为一个向量,并通过向量的角度、长度等属性来表示数据之间的关系。
高效索引结构:向量数据库采用高效的索引结构,如基于树或图的索引结构,来加速向量的检索和相似度计算。
近似查询:由于向量数据库中的数据存在噪声和异常值,因此它采用近似查询的方式来获取查询结果,保证查询效率的同时,尽可能地减少误差。
并行处理:向量数据库支持并行处理,能够利用多核处理器或多台计算机来加速大规模数据的处理和查询。
向量数据库的工作原理

向量数据库的工作原理主要包括以下几个方面:
向量嵌入:将非结构化数据(如文本、图像或音频)转换为向量表示,以便于存储和检索。
索引构建:使用KD树、球树或局部敏感哈希(LSH)等技术构建索引,加速向量搜索。
相似性度量:支持多种相似性度量方法,如欧氏距离、余弦相似度等,用于计算向量之间的相似度。
查询处理:根据用户查询,在索引中搜索与查询向量最相似的向量,并返回查询结果。
向量数据库的应用场景
图像检索:通过向量表示图像特征,实现快速的图像搜索和分类。
推荐系统:利用用户和商品的向量表示,向量数据库可以高效地进行推荐匹配。
自然语言处理:向量数据库在处理文本向量化后的数据,用于语义搜索和文本相似性比较。
语音识别:将语音信号转换为向量表示,用于语音识别和语音合成。
生物信息学:用于基因序列分析、蛋白质结构预测等。
流行的向量数据库解决方案
Milvus:一个开源的向量数据库,专为大规模特征向量检索设计。
FAISS:由Facebook AI Research开发的库,用于高效相似性搜索和密集向量聚类。
Annoy:Spotify开发的轻量级近似最近邻搜索库。
Elasticsearch:一个分布式搜索和分析引擎,可以用作向量数据库的解决方案。
向量数据库的未来趋势
多模态学习:结合不同类型的数据,如文本、图像、音频等,实现更全面的向量表示。
实时应用:向量数据库将支持更快的查询速度,满足实时应用场景的需求。
可扩展性:向量数据库将具备更高的可扩展性,以应对大规模数据集的挑战。
安全性:向量数据库将加强数据安全防护,确保数据的安全性和隐私性。