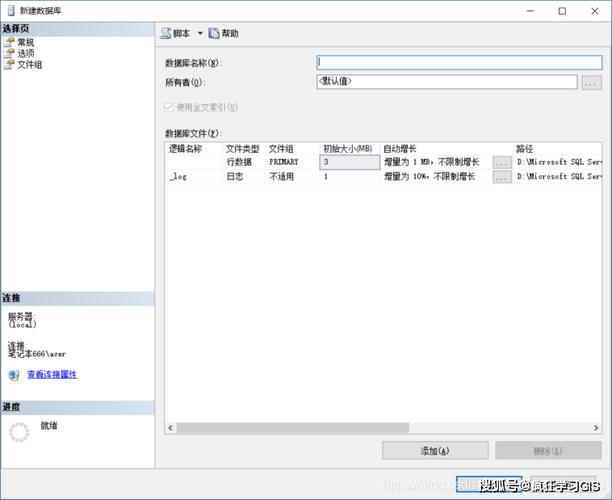
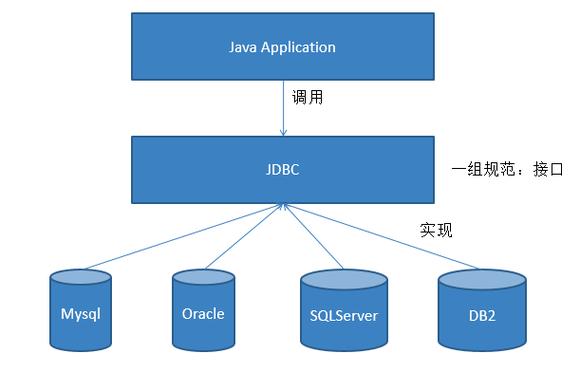
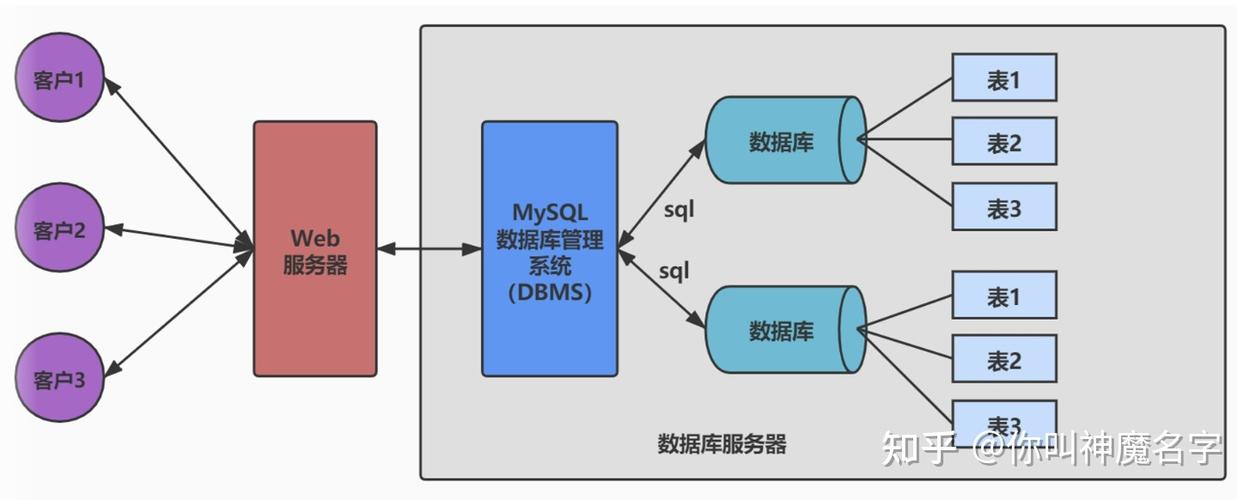
分布式数据库系统(Distributed Database Management System, DDBMS)是一种数据库管理系统,它将数据分布在多个物理位置,但逻辑上作为一个整体进行管理。这种系统允许用户和应用程序透明地访问分布在多个地点的数据,而无需知道数据的具体位置。以下是几种常见的分布式数据库:
1. Amazon DynamoDB 这是一个由Amazon Web Services(AWS)提供的托管NoSQL数据库服务,旨在提供快速和可扩展的性能。
2. Google Spanner 由Google开发,是一个全球分布式的、多版本、同步复制的数据库,支持跨多个数据中心的交易。
3. CockroachDB 这是一个开源的、云原生的分布式SQL数据库,旨在提供可扩展性、高可用性和数据一致性。
4. Cassandra 由Apache软件基金会维护的开源NoSQL分布式数据库,设计用于处理大量数据,提供高可用性和无单点故障。
5. MongoDB 虽然MongoDB本身是一个文档存储数据库,但它可以通过复制集和分片(Sharding)来实现分布式存储。
6. Microsoft Azure Cosmos DB 由Microsoft提供,是一个全球分布式的、多模型数据库服务,支持多种数据模型和API。
7. Amazon Aurora 这是一个由Amazon提供的托管关系数据库服务,虽然它本身不是分布式的,但可以通过多区域复制来实现数据的地理分布。
8. TiDB 这是一个开源的、云原生的分布式SQL数据库,旨在提供水平扩展、高可用性和数据一致性。
9. Amazon Redshift 虽然主要用于数据仓库,但Amazon Redshift也支持数据分布,通过集群和节点来实现数据的存储和处理。
10. Pivotal GemFire 这是一个内存数据网格解决方案,支持分布式数据管理,提供高速缓存和实时数据访问。
这些数据库系统在性能、可扩展性、数据一致性和高可用性等方面各有特点,用户可以根据具体需求选择合适的分布式数据库系统。
分布式数据库概述
分布式数据库(Distributed Database)是一种将数据存储在多个地理位置的数据库系统中,通过计算机网络连接起来,形成一个逻辑上统一的数据库。它具有高可用性、高扩展性和高容错性等特点,适用于大规模数据存储和复杂业务场景。
分布式数据库的分类
分布式数据库主要分为以下几类:
物理上分布,逻辑上集中:数据存储在多个物理节点上,但逻辑上视为一个整体。
物理上集中,逻辑上分布:数据存储在多个逻辑分区中,每个分区对应一个物理节点。
联邦式分布式数据库:由多个自治的数据库系统组成,通过统一的接口访问。
分布式数据库的关键技术
分布式数据库涉及以下关键技术:
数据分片(Sharding):将数据按照一定的规则分散到不同的物理节点上。
数据复制(Replication):将数据从源节点复制到多个目标节点,提高数据可用性和容错性。
分布式事务管理:保证分布式数据库中事务的原子性、一致性、隔离性和持久性(ACID属性)。
分布式锁(Distributed Lock):协调多个节点上的并发访问,保证数据的一致性。
分布式数据库的应用场景
分布式数据库适用于以下场景:
大规模数据存储:处理海量数据,满足业务增长需求。
高可用性:保证系统在部分节点故障的情况下仍能正常运行。
高扩展性:支持系统在线水平扩展,满足业务增长需求。
地理分布:支持跨地域的数据访问和业务处理。
分布式数据库的挑战与解决方案
分布式数据库在应用过程中面临以下挑战:
数据一致性问题:如何保证分布式数据库中数据的一致性。
分布式事务管理:如何实现分布式事务的ACID属性。
网络延迟和带宽限制:如何提高分布式数据库的网络性能。
一致性协议:如Raft、Paxos等,保证数据一致性。
分布式事务管理:如两阶段提交(2PC)、三阶段提交(3PC)等,实现分布式事务的ACID属性。
数据压缩和缓存:提高网络传输效率和降低延迟。
分布式数据库的未来发展趋势
随着云计算、大数据和物联网等技术的发展,分布式数据库在未来将呈现以下发展趋势:
云原生分布式数据库:基于云平台的分布式数据库,具有更高的可扩展性和弹性。
多模型数据库:支持多种数据模型,如关系型、文档型、键值型等,满足不同业务需求。
智能化数据库:利用人工智能技术,实现自动化运维、智能优化等。