1. 选择向量数据库软件: 首先,你需要选择一个适合你的需求的向量数据库软件。市面上有多个向量数据库可供选择,如Faiss、Milvus、Zilliz、Pinecone等。你可以根据自己的具体需求(如数据量、查询性能、易用性等)来选择合适的数据库。
2. 安装和配置数据库服务器: 在本地部署向量数据库,你需要安装和配置数据库服务器。这通常涉及到安装数据库软件、设置数据库参数、配置网络和安全设置等。具体步骤可能因所选的数据库软件而异。
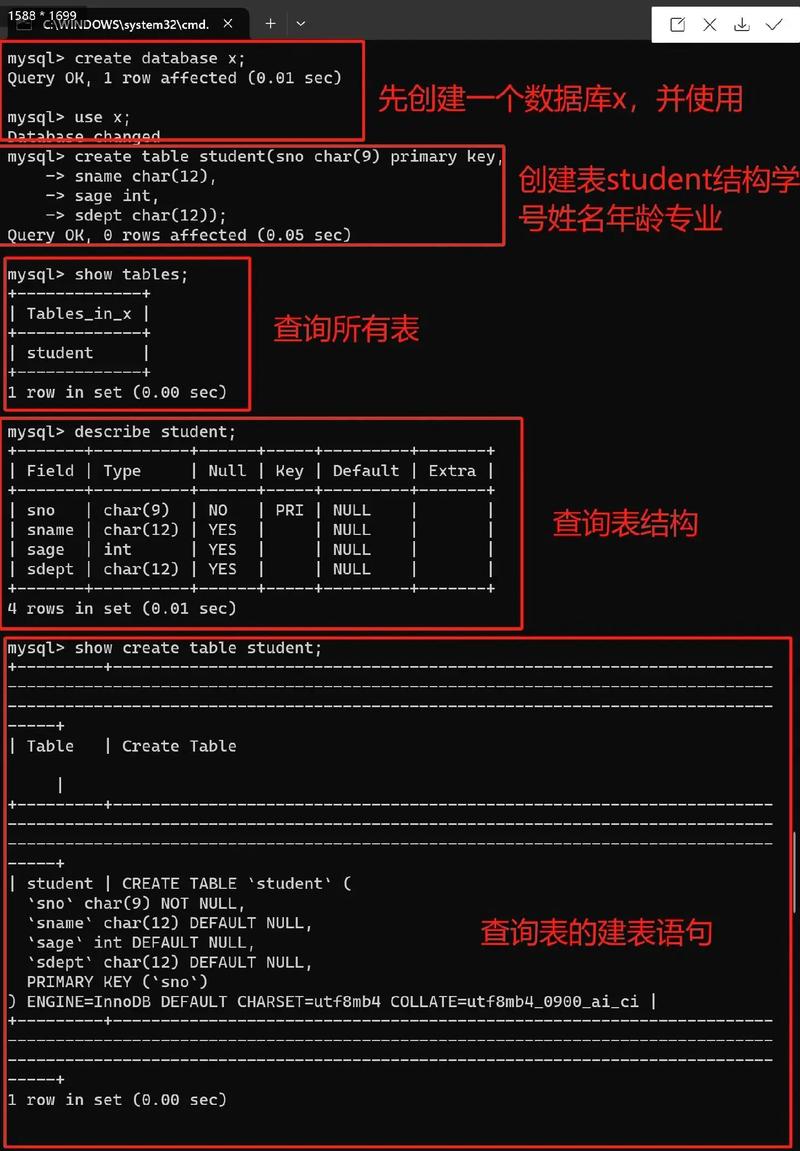
3. 设置数据库环境: 在安装和配置数据库服务器之后,你需要设置数据库环境。这包括创建数据库、设置用户权限、配置数据表等。你需要根据自己的需求来设置数据库环境。
4. 导入和存储数据: 在设置好数据库环境之后,你可以开始导入和存储数据。这通常涉及到将数据转换为向量格式,并将其存储到数据库中。你需要根据所选的数据库软件和你的数据格式来选择合适的数据导入方法。
5. 进行查询和检索: 一旦数据被导入和存储到数据库中,你就可以开始进行查询和检索。这通常涉及到使用向量搜索算法来查找与给定查询向量最相似的数据点。你需要根据所选的数据库软件和你的查询需求来选择合适的查询和检索方法。
6. 维护和优化数据库: 在数据库部署和运行之后,你需要定期维护和优化数据库。这包括备份和恢复数据、监控数据库性能、优化查询和检索性能等。你需要根据所选的数据库软件和你的需求来制定合适的维护和优化策略。
请注意,以上步骤仅供参考,具体步骤可能因所选的数据库软件和你的需求而异。在部署向量数据库之前,建议仔细阅读所选数据库软件的官方文档和教程,以了解具体的安装、配置和使用方法。
本地部署向量数据库:轻松构建高效搜索系统

随着大数据和人工智能技术的快速发展,向量数据库在处理大规模向量数据方面发挥着越来越重要的作用。本文将详细介绍如何在本地环境中部署向量数据库,帮助您轻松构建高效搜索系统。
一、什么是向量数据库?

向量数据库是一种专门用于存储、索引和管理向量数据的数据库。它可以将非结构化数据(如图像、文本等)转换为向量形式,并利用向量空间模型进行相似度搜索,从而实现高效的数据检索。
二、选择合适的向量数据库

目前市面上有许多优秀的向量数据库,如Milvus、Qdrant、Weaviate等。在选择向量数据库时,需要考虑以下因素:
性能:数据库的查询速度、索引构建速度等。
易用性:数据库的安装、配置、使用是否简单。
功能:数据库是否支持所需的特性,如向量搜索、聚合查询等。
社区支持:是否有活跃的社区,能否获得及时的技术支持。
三、本地部署向量数据库——以Milvus为例
Milvus是一款高性能的向量数据库,支持多种索引算法,易于使用和扩展。以下是在本地环境中部署Milvus的步骤:
下载Milvus Docker镜像
创建Docker Compose文件
启动Milvus服务
创建集合和索引
插入数据
进行搜索
1. 下载Milvus Docker镜像
首先,从Docker Hub下载Milvus的最新镜像:
docker pull milvusdb/milvus:latest
2. 创建Docker Compose文件
在本地创建一个名为`docker-compose.yaml`的文件,并添加以下内容:
version: '3.8'
services:
milvus:
image: milvusdb/milvus:latest
container_name: milvus
ports:
- \