1. Hadoop:Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。它由HDFS(Hadoop Distributed File System)和MapReduce组成,可以处理存储在HDFS上的大量数据。
2. Spark:Spark是一个快速、通用的大数据处理引擎。它提供了多种数据处理功能,如批处理、流处理、机器学习等。Spark支持多种编程语言,如Scala、Java、Python等。
3. Hive:Hive是一个基于Hadoop的数据仓库工具,它提供了一个类似SQL的查询语言,称为HiveQL,用于查询存储在HDFS上的数据。
4. Pig:Pig是一个基于Hadoop的大数据处理工具,它提供了一个高级的脚本语言,称为Pig Latin,用于处理和分析大规模数据集。
5. Tableau:Tableau是一个数据可视化工具,它可以帮助用户将大数据转换为易于理解的图表和仪表板。Tableau支持多种数据源,包括Hadoop、Spark等。
6. Power BI:Power BI是一个数据分析和报告工具,它提供了丰富的数据可视化功能,可以帮助用户快速创建和共享数据洞察。Power BI支持多种数据源,包括Hadoop、Spark等。
7. Elasticsearch:Elasticsearch是一个基于Lucene的搜索引擎,它提供了强大的搜索和分析功能,可以处理大规模的数据集。
8. Kibana:Kibana是一个开源的数据可视化工具,它可以帮助用户探索、可视化和分享Elasticsearch中的数据。
9. TensorFlow:TensorFlow是一个开源的机器学习框架,它提供了丰富的工具和库,用于构建和训练机器学习模型。TensorFlow可以处理大规模的数据集,并支持分布式训练。
10. PyTorch:PyTorch是一个开源的机器学习库,它提供了丰富的工具和库,用于构建和训练机器学习模型。PyTorch支持大规模的数据集,并提供了易于使用的API。
这些大数据模板可以根据具体的需求和场景进行选择和使用。
大数据时代的来临:定义与背景

大数据的特点
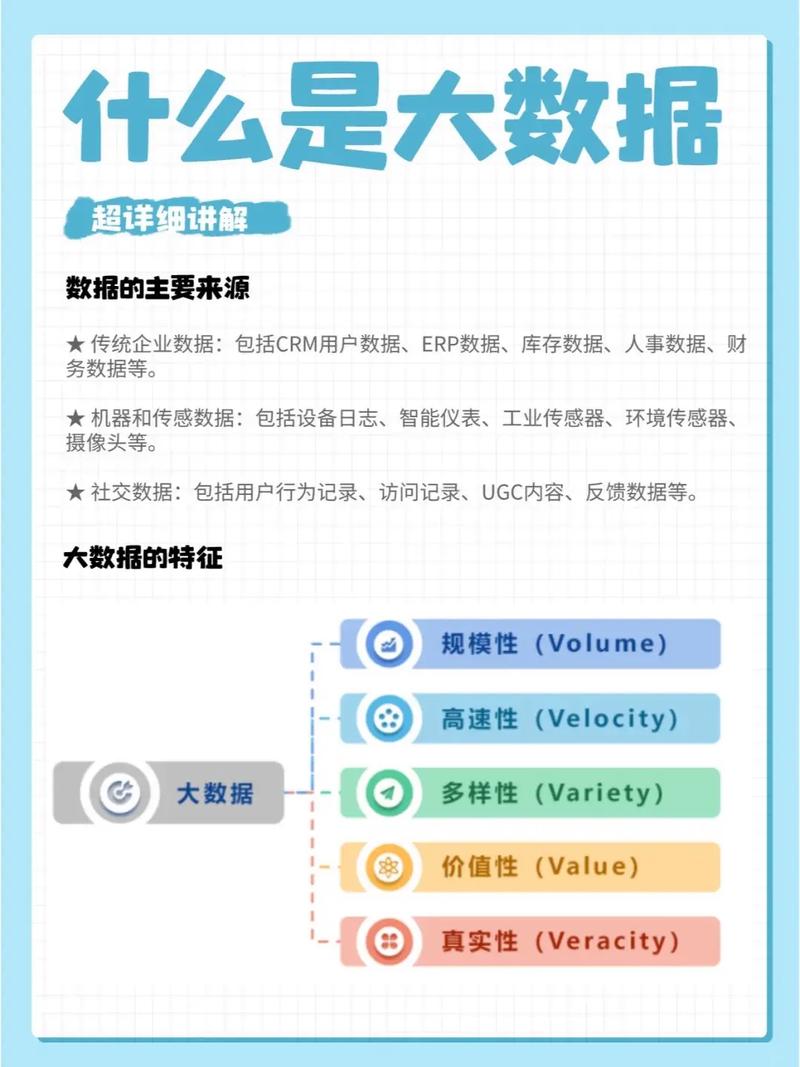
大数据具有以下四个主要特点,通常被简称为“4V”:
Volume(大量):数据量巨大,超出了传统数据库的处理能力。
Velocity(高速):数据产生和流动的速度极快,需要实时处理和分析。
Variety(多样):数据类型丰富,包括结构化数据、半结构化数据和非结构化数据。
Value(价值):数据中蕴含着巨大的价值,但价值密度低,需要通过数据挖掘技术提取。
大数据的应用领域

金融行业:通过分析交易数据,金融机构可以识别欺诈行为,优化风险管理。
医疗健康:利用患者病历和基因数据,可以预测疾病风险,提高治疗效果。
零售业:通过分析消费者行为数据,零售商可以精准营销,提高销售额。
交通出行:利用交通流量数据,可以优化交通信号灯控制,减少拥堵。
社交媒体:分析用户行为和内容,可以提供个性化的推荐服务。
大数据技术体系
为了处理和分析大数据,形成了一套完整的技术体系,主要包括以下几方面:
数据采集:通过各种手段收集数据,如传感器、日志文件等。
数据存储:使用分布式文件系统(如Hadoop HDFS)存储海量数据。
数据处理:利用MapReduce、Spark等计算框架进行数据处理和分析。
数据挖掘:通过机器学习、数据挖掘算法从数据中提取有价值的信息。
可视化分析:使用图表、仪表盘等工具将数据可视化,便于理解和决策。
大数据的挑战与机遇

大数据的发展带来了巨大的机遇,同时也伴随着一系列挑战:
数据安全与隐私:如何保护用户数据的安全和隐私是一个重要问题。
数据质量:大数据的质量参差不齐,需要确保数据的一致性和准确性。
人才短缺:大数据领域需要大量具备专业技能的人才。
技术复杂性:大数据技术体系复杂,需要不断学习和适应。
尽管存在挑战,但大数据带来的机遇远远大于风险。随着技术的不断进步和应用的深入,大数据将为各行各业带来革命性的变革。
结论
大数据时代已经到来,它不仅改变了我们的生活方式,也推动了各行各业的创新和发展。面对大数据带来的机遇和挑战,我们需要积极应对,不断探索和突破,以实现数据价值的最大化。