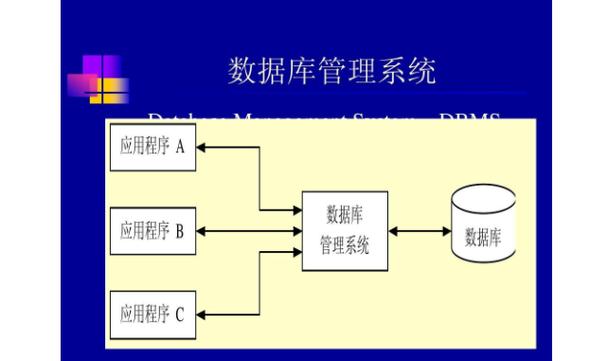
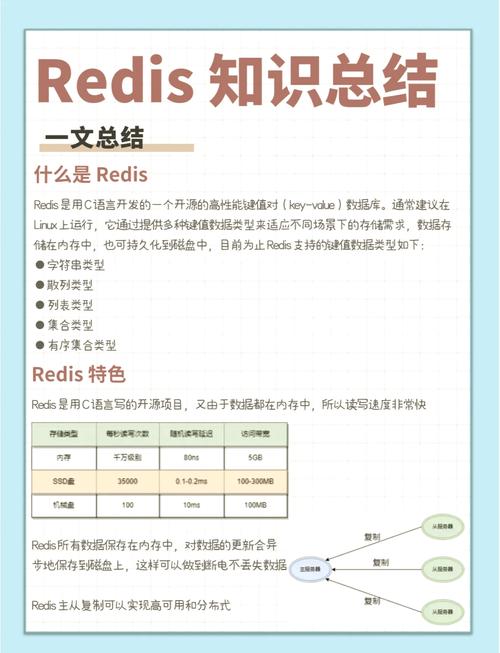
1. 数据集成:将来自不同来源的数据整合到一个统一的数据集中。2. 数据清洗:识别并纠正数据中的错误和不一致,例如缺失值、重复值、异常值等。3. 数据转换:将数据转换为适合分析的格式,例如将字符串转换为数字、日期格式转换等。4. 数据归一化:将数据缩放到一个共同的尺度,以便进行比较和分析。5. 数据去重:删除重复的数据记录,以确保数据集的唯一性。6. 数据压缩:减少数据的大小,以便于存储和传输。7. 数据加密:保护敏感数据,防止未经授权的访问。8. 数据备份:创建数据副本,以防止数据丢失或损坏。
大数据清洗通常使用编程语言(如Python、R等)和数据处理工具(如Hadoop、Spark等)来完成。这些工具和语言提供了丰富的库和函数,用于数据清洗、转换、分析和可视化。
大数据清洗是一个迭代的过程,可能需要多次迭代才能达到满意的结果。随着数据量的增长和业务需求的变化,大数据清洗的方法和工具也在不断发展和完善。
大数据清洗:提升数据质量的关键步骤

随着信息技术的飞速发展,大数据已经成为各行各业的重要资源。在大数据时代,数据质量问题日益凸显,如何高效地处理和分析这些数据成为一项重要挑战。数据清洗作为提升数据质量的重要工具,对于确保分析结果的准确性和可靠性具有重要意义。
一、数据清洗的定义与重要性

数据清洗是指通过一系列技术和方法,识别和纠正数据集中的错误、冗余和不一致性,从而提升数据质量的过程。在大数据时代,数据清洗的重要性主要体现在以下几个方面:
提高数据质量:数据清洗可以去除数据中的错误、缺失值、异常值等,确保数据的准确性和可靠性。
降低分析成本:高质量的数据可以减少后续分析过程中的错误和偏差,降低分析成本。
提高决策效率:高质量的数据可以为决策者提供更准确的依据,提高决策效率。
二、数据清洗的常见任务

数据清洗涉及多个方面,以下列举了数据清洗的常见任务:
缺失值处理:删除缺失值、填充缺失值、使用其他数据进行替换等。
重复值处理:删除重复值、保留一个重复值、使用其他数据进行替换等。
异常值处理:删除异常值、使用其他数据进行替换、使用异常值检测算法进行检测等。
数据转换:数据类型转换、日期格式处理等,以满足分析需求。
数据标准化:将数据进行归一化或标准化处理,使得不同数据具有可比性。
三、数据清洗的技术与方法
数据清洗的技术与方法多种多样,以下列举了常见的数据清洗技术:
规则匹配:通过编写规则,识别和纠正数据集中的错误。
机器学习:利用机器学习算法,自动识别和纠正数据集中的错误。
数据可视化:通过数据可视化技术,直观地发现数据中的问题。
数据清洗工具:使用数据清洗工具,如 OpenRefine、DataWrangler、Trifacta 等,提高数据清洗效率。
四、大数据清洗的挑战与应对策略
在大数据环境下,数据清洗面临着诸多挑战,以下列举了部分挑战及应对策略:
数据量庞大:大数据量使得数据清洗变得复杂,需要采用分布式计算技术。
数据类型多样:不同类型的数据需要采用不同的清洗方法。
实时性需求:实时数据清洗需要高效的数据处理技术。
针对这些挑战,可以采取以下应对策略:
采用分布式计算技术:如 Hadoop、Spark 等,提高数据清洗效率。
结合多种数据清洗方法:针对不同类型的数据,采用不同的清洗方法。
优化数据清洗流程:通过优化数据清洗流程,提高数据清洗效率。
数据清洗是大数据时代提升数据质量的关键步骤。通过数据清洗,可以确保数据的准确性和可靠性,为后续的分析和决策提供可靠的基础。在大数据环境下,数据清洗面临着诸多挑战,需要采取相应的应对策略。随着技术的不断发展,数据清洗技术将更加成熟,为大数据时代的到来提供有力支持。