向量数据库(Vector Database)是一种专门用于存储和查询高维向量的数据库系统。这些向量通常用于机器学习、自然语言处理、图像识别等领域的特征表示。向量数据库的设计旨在高效地处理这些高维数据,并支持复杂的查询操作,如相似性搜索、聚类、分类等。
以下是向量数据库的一些关键特点和使用场景:
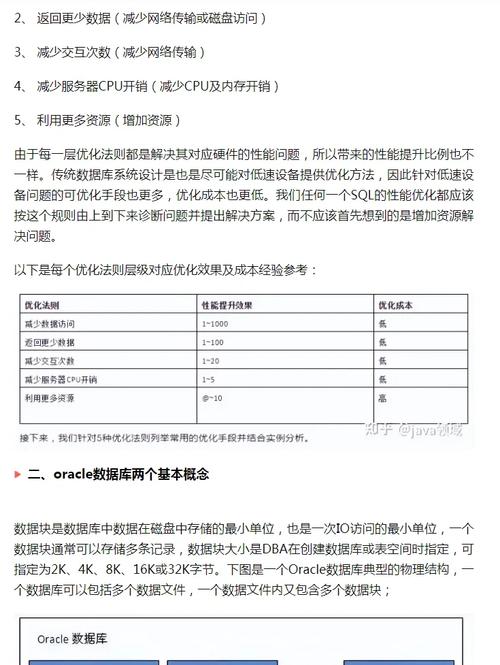
1. 高维数据存储:向量数据库能够高效地存储和处理高维数据,如机器学习模型中的特征向量。
2. 快速相似性搜索:向量数据库支持快速检索与给定查询向量最相似的向量,这对于推荐系统、图像搜索、语音识别等应用非常重要。
3. 可扩展性:向量数据库通常设计为可扩展的,以支持大规模数据集和查询负载。
4. 支持多种查询类型:除了相似性搜索,向量数据库还支持其他查询类型,如范围查询、最近邻查询、聚类等。
5. 集成机器学习:一些向量数据库与机器学习框架集成,支持在数据库中直接执行机器学习任务。
使用向量数据库的步骤通常包括:
数据预处理:将原始数据转换为向量表示,这可能涉及特征提取、归一化等步骤。 数据导入:将预处理后的向量数据导入向量数据库。 查询设计:设计查询,以检索与给定查询向量最相似的向量或执行其他类型的向量操作。 结果分析:分析查询结果,以提取有用的信息或支持决策。
在选择向量数据库时,需要考虑以下因素:
数据规模:数据库需要能够处理的数据量。 查询类型:需要支持的查询类型。 性能要求:查询的响应时间要求。 可扩展性:数据库的扩展能力,以适应未来的增长。 集成和兼容性:与现有系统的集成和兼容性。
一些流行的向量数据库包括:
Faiss:由Facebook AI Research开发的库,用于高效相似性搜索和密集向量聚类。 Annoy:由Spotify开发的库,用于近似最近邻搜索。 Elasticsearch:虽然主要是搜索和数据分析引擎,但也可以用于向量搜索。 Milvus:一个开源的向量数据库,支持多种查询类型和可扩展性。
请注意,向量数据库的选择和使用应根据具体的应用需求和场景来决定。
深入浅出向量数据库:原理、应用与实战

一、向量数据库的原理
向量数据库是一种专门用于存储和管理向量数据的数据库。在人工智能和机器学习领域,向量是表示数据的一种方式,它可以将复杂的数据结构转化为简单的数值表示,便于计算机处理和分析。
向量数据库的核心原理是利用空间索引技术,对向量数据进行高效存储和检索。常见的空间索引技术包括球树、k-d树、R树等。这些索引技术可以将向量数据组织成一种层次结构,使得查询操作能够在极短的时间内完成。
二、向量数据库的应用场景
向量数据库在众多领域都有广泛的应用,以下列举几个典型的应用场景:
1. 人工智能与机器学习
在人工智能和机器学习领域,向量数据库可以用于存储和检索特征向量、词向量、图像向量等数据,从而提高模型的训练和推理效率。
2. 搜索引擎
向量数据库可以用于构建高效的搜索引擎,通过向量相似度计算,实现快速、准确的搜索结果。
3. 推荐系统
向量数据库可以用于存储用户行为数据,通过向量相似度计算,为用户提供个性化的推荐结果。
4. 图像识别与处理
向量数据库可以用于存储图像特征向量,通过向量相似度计算,实现图像识别、图像检索等功能。
三、向量数据库的实战案例
以下是一个使用向量数据库构建图像检索系统的实战案例:
1. 数据准备
首先,我们需要准备一批图像数据,并对这些图像进行特征提取,得到对应的特征向量。
2. 选择向量数据库
根据实际需求,选择合适的向量数据库,如Milvus、Pinecone、Faiss等。
3. 数据导入
将提取的特征向量导入向量数据库,并建立相应的索引。
4. 查询与检索
当用户输入查询图像时,将查询图像的特征向量与数据库中的向量进行相似度计算,返回相似度最高的图像列表。
向量数据库作为一种高效的数据存储和管理技术,在人工智能、大数据等领域具有广泛的应用前景。通过本文的介绍,相信读者对向量数据库有了更深入的了解。在实际应用中,选择合适的向量数据库和索引技术,可以有效提高数据存储和检索效率。