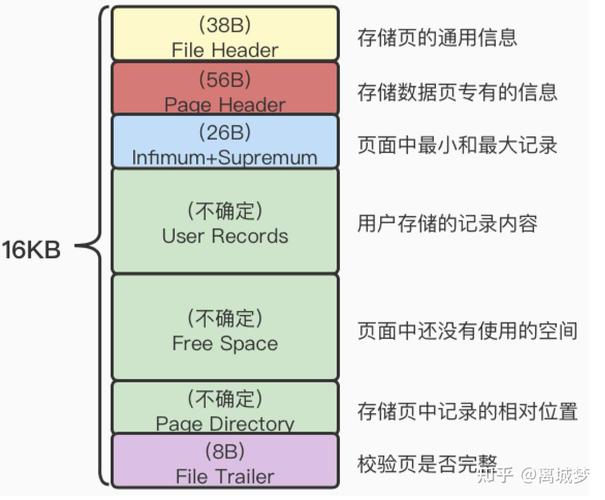
MySQL数据库设计中的三大范式是数据库设计理论的基础,它们指导我们如何合理地设计数据库结构,以提高数据存储的效率、减少数据冗余,并确保数据的一致性和完整性。三大范式分别是:
1. 第一范式(1NF): 定义:第一范式要求每个属性(列)都是不可再分的原子值。 目的:确保每列的原子性,即每列中的数据不能再分解为更小的数据单元。 例子:在学生信息表中,将“地址”列拆分为“省”、“市”、“区”等更具体的列。
2. 第二范式(2NF): 定义:在满足第一范式的基础上,第二范式要求表中的所有非主键列必须完全依赖于主键列。 目的:消除非主属性对主键的部分依赖,确保数据表的每行记录只包含一个主题的信息。 例子:将一个包含学生信息和课程信息的表拆分为两个表:一个学生信息表,一个选课信息表,选课信息表中包含学生ID和课程ID,这样可以确保每个表只包含一个主题的信息。
3. 第三范式(3NF): 定义:在满足第二范式的基础上,第三范式要求表中的非主属性不依赖于其他非主属性。 目的:消除非主属性对主属性或非主属性之间的传递依赖,进一步减少数据冗余。 例子:在学生选课信息表中,如果课程信息(如课程名称、学分等)重复出现在多条记录中,可以将这些信息独立出来,创建一个课程信息表,通过课程ID与选课信息表关联。
遵循这三大范式可以有效地提高数据库的设计质量,减少数据冗余,保证数据的完整性和一致性。在实际应用中,有时为了性能考虑,可能会适当地违反某些范式,例如,通过增加冗余数据来提高查询效率。这需要根据具体的应用场景和需求来权衡。
什么是MySQL的三大范式?
MySQL的三大范式是数据库设计中非常重要的规范,它们分别是第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。这些范式旨在通过减少数据冗余、提高数据完整性和查询效率来优化数据库结构。
第一范式(1NF)
第一范式要求数据库表中的每一列都是不可分割的原子值。这意味着每个字段都必须是不可再分的最小数据单元,不能包含多个值。第一范式的目标是确保每列的原子性,从而避免数据冗余和更新异常。
例如,一个学生信息表,如果包含一个“联系方式”字段,其中同时存储了电话和邮箱信息,那么这个表就不符合第一范式。正确的做法是将“联系方式”拆分成“电话”和“邮箱”两个字段。
第二范式(2NF)
第二范式建立在第一范式的基础上,它要求表中的每个实例或行必须可以被唯一地区分,并且所有非主属性都完全依赖于主键。所谓完全依赖是指不能存在仅依赖主键一部分的属性,如果存在,那么这个属性和主键的这一部分应该分离出来形成一个新的实体。
例如,一个学生成绩表,如果包含学生ID、课程ID、成绩和课程名称,其中主键是由学生ID和课程ID组成的联合主键,但课程名称只依赖于课程ID,而与学生ID无关,那么这个表就不符合第二范式。正确的做法是将课程名称分离出来,形成一个新的课程信息表。
第三范式(3NF)

第三范式建立在第二范式的基础上,它要求表中的每一列都只能依赖于主键,而不依赖于其他非主键列。也就是说,不存在传递依赖,即一个字段依赖于另一个非主键字段。
例如,一个员工信息表,如果包含部门编号和部门经理两个字段,而部门经理又依赖于部门编号,那么这个表就不符合第三范式。正确的做法是将部门信息分离出来,形成一个新的部门信息表。
三大范式的优点

遵循三大范式可以带来以下优点:
减少数据冗余:避免相同数据在多个地方重复存储,减少存储空间需求。
确保数据一致性:通过消除传递依赖,减少因数据更新不一致导致的错误。
简化数据管理:使数据库结构更清晰,便于维护和扩展。
三大范式的应用
设计学生信息管理系统时,遵循三大范式可以确保学生信息的准确性和完整性。
设计电子商务平台时,遵循三大范式可以优化商品信息、订单信息和用户信息的管理。
设计企业资源规划(ERP)系统时,遵循三大范式可以提高数据的一致性和查询效率。
MySQL的三大范式是数据库设计中不可或缺的规范。遵循这些范式可以优化数据库结构,减少数据冗余,提高数据完整性和查询效率。在实际应用中,我们应该根据具体需求,合理地应用三大范式,以构建高效、稳定的数据库系统。