MySQL分布式数据库通常是指将MySQL数据库分布在多个服务器或节点上,以提高数据库的性能、可靠性和可扩展性。这种分布式架构可以有多种实现方式,包括但不限于:
1. 主从复制(MasterSlave Replication):在这种架构中,主服务器处理所有的写操作,并将更改记录到二进制日志中。从服务器定期从主服务器同步这些更改,以保持数据的一致性。这种架构可以提高读性能,因为读操作可以在从服务器上分担。
2. 分片(Sharding):分片是一种将数据分布到多个数据库或表中的技术。每个分片包含数据库的一部分数据,通常根据某种键(如用户ID、地区等)进行划分。分片可以大大提高数据库的写性能和水平扩展能力。
3. 集群(Clustering):MySQL集群是一种高可用性的解决方案,它使用多个节点来存储数据,并通过NDB(Network Database)存储引擎提供共享的内存结构。这种架构可以提供故障转移和数据冗余,从而提高数据库的可靠性和可用性。
4. 分布式SQL数据库:如MySQL Cluster、Amazon Aurora等,这些数据库提供了分布式数据库的功能,包括自动扩展、故障转移和自动数据复制等。
5. 分布式中间件:一些第三方中间件,如ProxySQL、MyCat等,可以在MySQL前端提供分布式数据库的功能,如读写分离、分片、负载均衡等。
在选择MySQL分布式数据库解决方案时,需要考虑以下因素:
性能:分布式数据库可以提高性能,但需要考虑网络延迟和数据同步的开销。 可靠性:分布式架构可以提高数据库的可靠性,但需要考虑数据一致性和故障转移的问题。 可扩展性:分布式数据库可以轻松扩展,但需要考虑分片策略和数据迁移的问题。 管理复杂性:分布式数据库的管理比单机数据库复杂,需要考虑监控、备份和恢复等问题。
总的来说,MySQL分布式数据库是一种提高数据库性能、可靠性和可扩展性的有效方式,但需要根据具体需求选择合适的架构和解决方案。
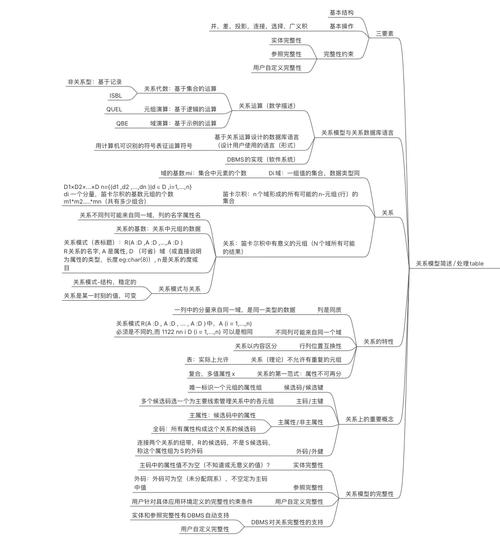
MySQL分布式数据库:原理、方法与实践

一、MySQL分布式数据库的原理
MySQL分布式数据库是指将数据分布在多个独立的服务器上,通过网络进行连接和管理的数据库系统。其核心原理包括以下几个方面:
数据分片:将数据库中的数据按照一定的规则划分到不同的服务器节点上,每个节点存储部分数据。
数据复制:将数据从主节点复制到从节点,实现数据的冗余和故障转移。
负载均衡:通过分布式算法将请求均匀地分配到各个节点,提高系统性能。
事务处理:保证在分布式环境下的事务一致性和可靠性。
二、MySQL分布式数据库的实现方法
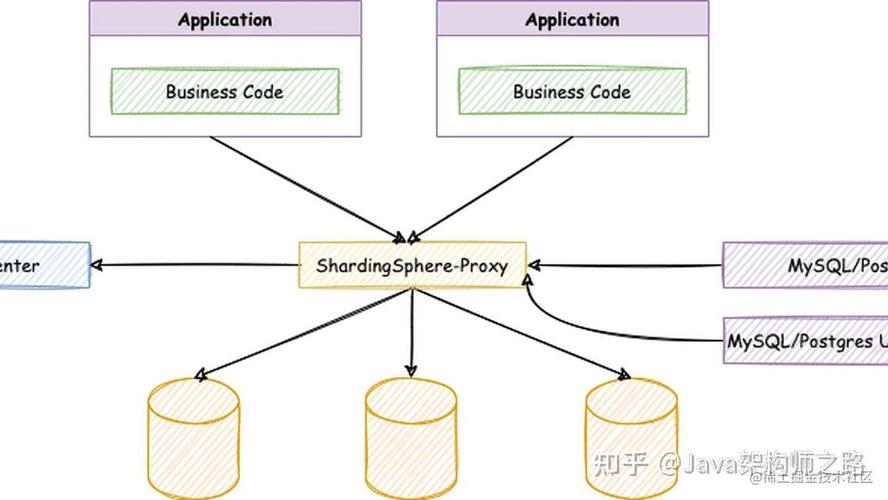
MySQL分布式数据库的实现方法主要有以下几种:
MySQL Cluster:MySQL Cluster是一种基于共享存储的分布式数据库,支持实时读写操作和容错。它通过NDB存储引擎实现数据分片和数据复制,并通过自己的协议进行节点之间的通信。
MySQL分片:MySQL分片是通过应用层的方式将数据分片,将数据按照一定的规则划分到不同的服务器节点上。常见的分片策略包括基于范围、哈希和列表等。
MySQL复制:MySQL复制是将数据从主节点复制到从节点,实现数据的冗余和故障转移。MySQL支持主从复制和主主复制两种模式。
读写分离:读写分离是将读操作和写操作分配到不同的服务器节点上,提高系统性能。MySQL支持通过配置文件或编程方式实现读写分离。
三、MySQL分布式数据库的实践案例
以下是一个MySQL分布式数据库的实践案例:
案例背景
某电商公司业务快速发展,数据库存储和处理需求不断增长。为了提高系统性能和可靠性,公司决定采用MySQL分布式数据库架构。
实现步骤
选择合适的MySQL版本和硬件资源。
搭建MySQL Cluster或MySQL分片集群。
配置数据分片策略,将数据按照规则划分到不同的节点上。
配置数据复制,实现数据的冗余和故障转移。
配置读写分离,提高系统性能。
测试和优化系统性能。
效果评估
通过采用MySQL分布式数据库架构,该电商公司实现了以下效果:
系统性能大幅提升,满足业务快速发展需求。
数据可靠性得到保障,降低故障风险。
系统可扩展性强,可根据业务需求动态调整。
MySQL分布式数据库是一种高效、可靠的数据库解决方案,适用于大规模、高并发的数据存储和处理需求。通过合理的设计和配置,MySQL分布式数据库可以为企业带来显著的性能和可靠性提升。在实际应用中,企业应根据自身业务需求和资源情况,选择合适的分布式数据库架构和实现方法。