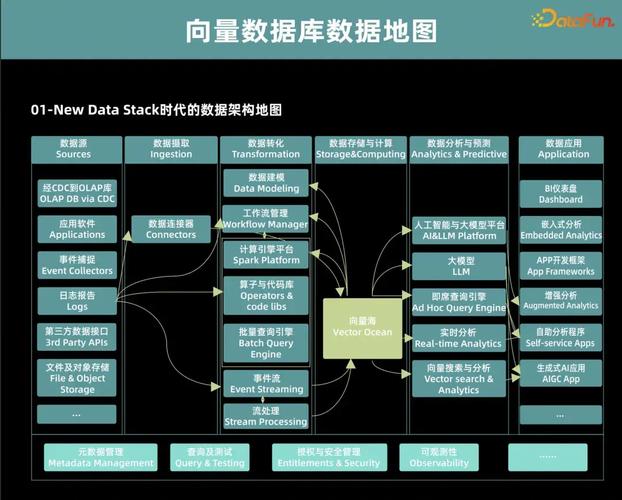
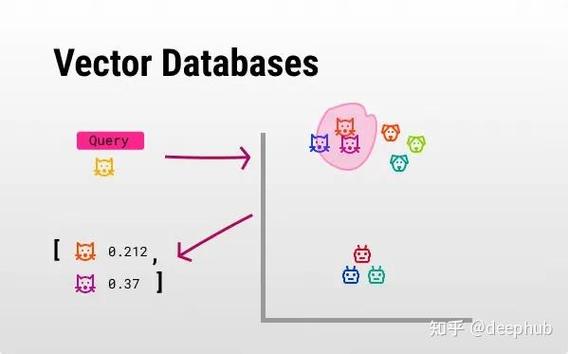
向量数据库(Vector Database)是一种专门用于存储和处理高维数据(如文本、图像、音频等)的数据库系统。它们通常用于机器学习和人工智能领域,其中数据以向量形式表示,并且可以高效地进行相似性搜索和比较。
配置向量数据库的要求可能因具体的使用车状况对于确保其稳定运行至关重要。
请注意,这些要求可能因具体的向量数据库和应用程序而异。在选择和配置向量数据库时,最好参考特定数据库的官方文档和指南。
向量数据库配置要求详解
随着大数据和人工智能技术的快速发展,向量数据库在处理大规模向量数据方面发挥着越来越重要的作用。本文将详细介绍向量数据库的配置要求,帮助您更好地搭建和使用向量数据库。
一、硬件配置要求
1. CPU:向量数据库对CPU的处理能力要求较高,建议使用多核CPU,以便并行处理大量向量数据。
2. 内存:内存是影响向量数据库性能的关键因素之一。根据存储的向量数据量和查询需求,建议配置足够的内存,以便缓存索引和查询结果。

3. 存储:向量数据库需要存储大量的向量数据,因此需要配置大容量、高速度的存储设备。SSD硬盘是较好的选择,因为它具有较快的读写速度。
4. 网络:如果向量数据库需要支持分布式部署,则需要配置高速、稳定的网络环境,以确保数据传输的效率。
二、软件配置要求
1. 操作系统:向量数据库支持的操作系统包括Linux、Windows等。建议选择稳定、性能较好的操作系统,如CentOS、Ubuntu等。
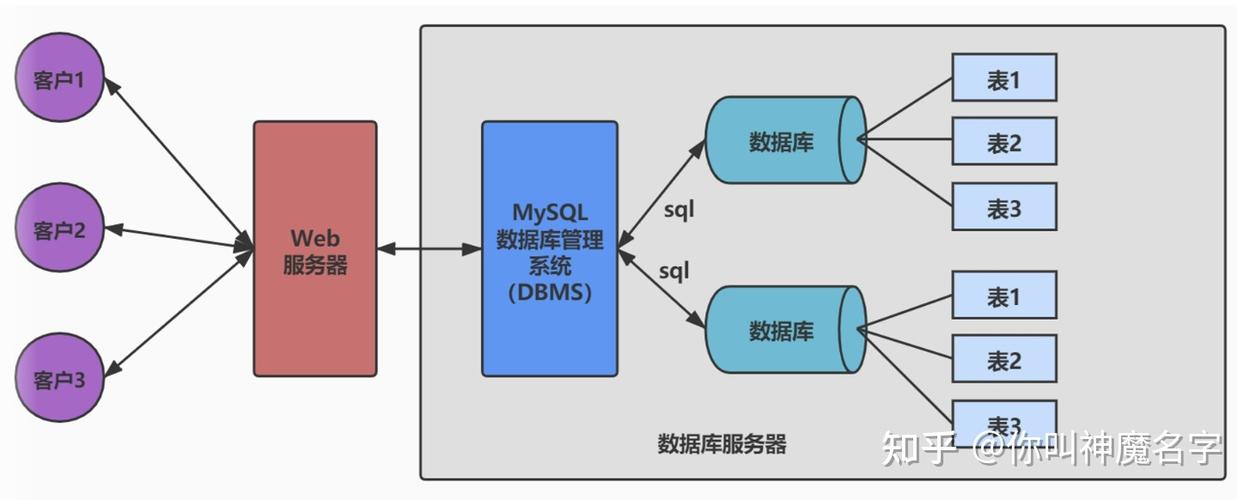
2. 数据库引擎:向量数据库通常基于特定的数据库引擎,如MySQL、PostgreSQL等。选择合适的数据库引擎,需要考虑数据存储、查询性能等因素。
3. 编程语言支持:向量数据库需要支持多种编程语言,以便用户能够方便地进行开发。常见的编程语言支持包括Python、Java、C 等。
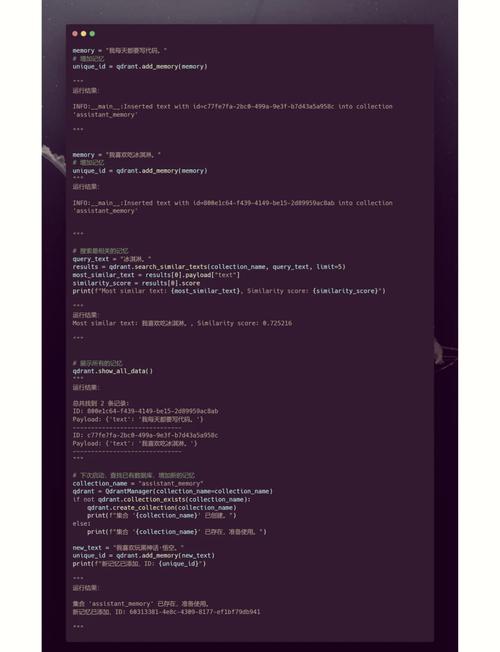
4. 第三方库和工具:向量数据库可能需要依赖一些第三方库和工具,如Faiss、Milvus等。在配置过程中,需要确保这些库和工具的兼容性和稳定性。
三、向量数据库配置步骤
1. 安装操作系统:首先,在服务器上安装支持的操作系统。
2. 安装数据库引擎:根据需求选择合适的数据库引擎,并按照官方文档进行安装。
3. 安装向量数据库:下载向量数据库的安装包,并按照官方文档进行安装。
4. 配置数据库参数:根据实际需求,配置数据库的参数,如内存大小、存储路径等。
5. 创建数据库和表:使用数据库管理工具创建数据库和表,并设置相应的字段和数据类型。
6. 导入数据:将向量数据导入到数据库中,可以使用命令行工具或图形界面工具进行操作。
7. 创建索引:根据查询需求,为表中的字段创建索引,以提高查询效率。
8. 测试和优化:对数据库进行测试,确保其性能满足需求。根据测试结果,对数据库进行优化,如调整参数、优化查询语句等。

四、向量数据库性能优化
1. 合理配置内存:根据向量数据量和查询需求,合理配置内存大小,以提高缓存命中率。
2. 优化索引结构:选择合适的索引结构,如IVF、HNSW等,以提高查询效率。