1. UniProt:这是最广泛使用的蛋白质序列数据库,包含大量的蛋白质序列、功能描述和分类信息。
2. NCBI Protein:由美国国家生物技术信息中心(NCBI)维护,包含从GenBank、RefSeq和其他来源收集的蛋白质序列。
3. PDB(Protein Data Bank):存储了生物大分子(包括蛋白质)的三维结构信息。
4. Pfam:一个蛋白质家族数据库,通过多序列比对和隐马尔可夫模型(HMM)来描述蛋白质家族的保守结构域。
5. InterPro:一个整合的蛋白质家族、结构域和功能位点数据库,它结合了多个独立数据库的信息。
7. CATH(Class, Architecture, Topology, Homology):一个蛋白质结构分类数据库,根据蛋白质的结构特征进行分类。
8. SCOP(Structural Classification of Proteins):另一个蛋白质结构分类数据库,根据蛋白质的折叠类型进行分类。
9. ExPASy:瑞士生物信息学研究所(SIB)提供的蛋白质分析工具和数据库集合。
10. STRING:一个蛋白质蛋白质相互作用数据库,提供生物体中蛋白质之间相互作用的网络信息。
11. KEGG(Kyoto Encyclopedia of Genes and Genomes):一个整合了基因组、生物化学路径和疾病信息的数据库,其中也包含蛋白质序列信息。
12. Metacyc:一个关于代谢途径的数据库,其中也包含相关的蛋白质信息。
这些数据库提供了丰富的蛋白质信息,对于生物学家、生物信息学家和医学研究人员来说都是宝贵的资源。选择合适的数据库取决于研究目的和所需信息的类型。
蛋白质数据库:生命科学研究的重要工具
蛋白质是生命活动的基本物质,其结构和功能的研究对于理解生命现象、疾病机制以及药物研发具有重要意义。蛋白质数据库作为存储和检索蛋白质相关信息的平台,为科研工作者提供了强大的数据支持。本文将介绍一些常用的蛋白质数据库,并探讨它们在生命科学研究中的应用。
常用蛋白质数据库介绍
1. UniProt
UniProt(The Universal Protein Resource)是一个综合性的蛋白质数据库,整合了Swiss-Prot、TrEMBL和PIR-PSD三大子数据库的资源。它提供了详细的蛋白质序列、功能信息,如蛋白质功能描述、结构域结构、转录后修饰、修饰位点、变异度、二级结构、三级结构等,同时提供其他数据库的链接。
2. PDB
PDB(Protein Data Bank)是目前最主要的收集生物蛋白质三维结构的数据库。它通过X射线单晶衍射、核磁共振、电子衍射等实验手段确定的三维结构数据库,内容包括蛋白质的原子坐标、参考文献、一级和二级结构信息,也包括了晶体结构因数以及NMR实验数据等。
3. SCOP

SCOP(Structural Classification of Proteins)数据库提供了一个对所有已知结构的蛋白质之间的结构和进化关系的详细和全面的描述。它由人工检查创建,由一系列自动化方法支持,旨在提供对所有已知蛋白质折叠的广泛调查,以及关于任何特定蛋白质的近亲的详细信息。
4. InterPro
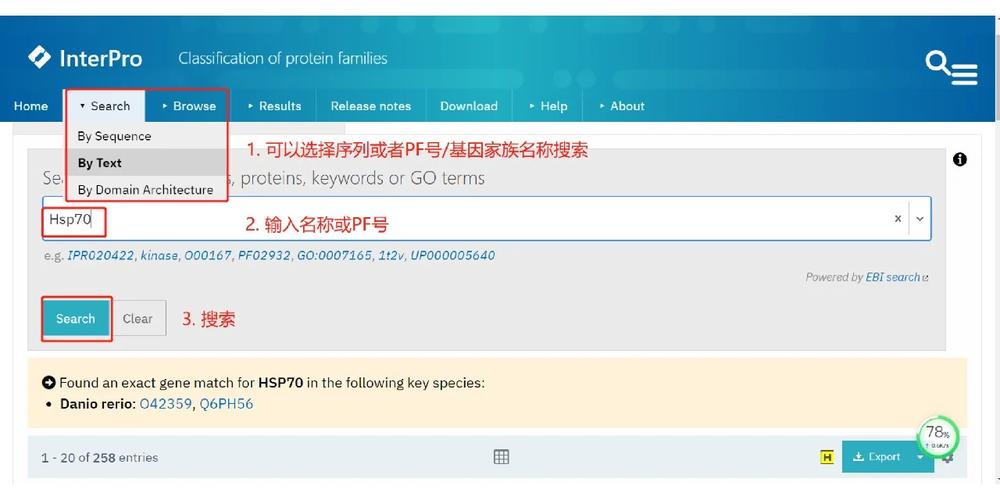
InterPro是一个集成的蛋白质和数据库,包含关于蛋白质家族、域、重复序列、和作用位点等数据资源。它提供了来自不同数据库的诊断签名的,形式多样的蛋白质功能注释。
5. BioXFinder
BioXFinder是国内第一个也是唯一一个生物数据库,收录了50多万条高质量的、整合多个来源数据,手工注释的非冗余的蛋白质信息。它包含蛋白质的基本信息、序列、序列特征、功能、名称和谱系、亚细胞定位、疾病与变异、翻译后修饰、表达、相互作用等信息。
蛋白质数据库的应用
1. 蛋白质序列分析

蛋白质数据库为科研工作者提供了大量的蛋白质序列信息,有助于进行蛋白质序列分析,如序列比对、同源性分析、进化分析等。
2. 蛋白质结构预测
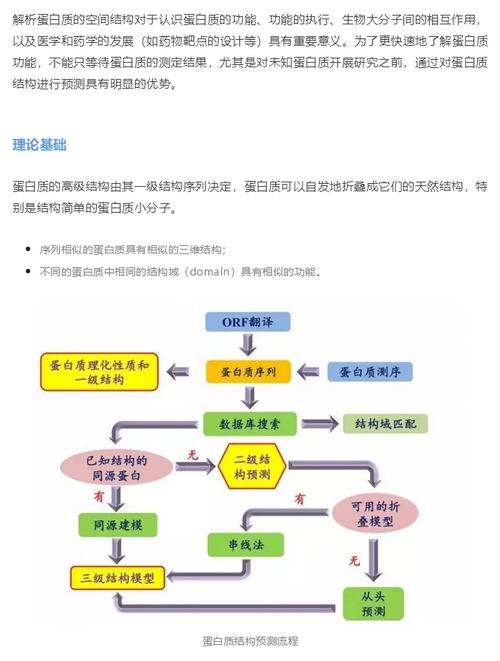
蛋白质数据库中的三维结构数据为蛋白质结构预测提供了重要的参考。科研工作者可以利用这些数据,通过同源建模、模板建模等方法预测未知蛋白质的结构。
3. 蛋白质功能注释

蛋白质数据库中的功能注释信息有助于科研工作者了解蛋白质的功能,为研究蛋白质在生物系统中的作用提供依据。
4. 蛋白质互作网络分析
蛋白质数据库中的蛋白质互作信息有助于构建蛋白质互作网络,揭示蛋白质之间的相互作用关系,为研究信号通路、疾病机制等提供线索。
蛋白质数据库是生命科学研究的重要工具,为科研工作者提供了丰富的蛋白质相关数据。随着生物信息学技术的不断发展,蛋白质数据库将不断完善,为生命科学研究提供更强大的支持。