`etree.html` 是一个字符串,它代表了一个 HTML 文档。这个字符串可以被用来创建一个 `ElementTree` 对象,该对象可以被用来解析和操作 HTML 文档。
例如,以下是如何使用 `etree.html` 来解析 HTML 文档并提取其中的
```pythonimport xml.etree.ElementTree as ET
HTML 文档字符串html_doc = 我的网页 欢迎来到我的网页 这是一个示例 HTML 文档。
使用 etree.html 解析 HTML 文档tree = ET.fromstring
获取标题title = tree.find.textprint```
输出结果将是:
```标题: 我的网页```
在这个例子中,我们首先定义了一个 HTML 文档字符串 `html_doc`。我们使用 `ET.fromstring` 方法来解析这个字符串,并创建了一个 `ElementTree` 对象 `tree`。我们使用 `tree.find` 方法来查找标题元素,并提取其文本内容。
`etree.html` 可以用来处理各种 HTML 文档,包括复杂的文档。它提供了丰富的 API 来操作 XML 和 HTML 文档,包括查找元素、修改元素、添加元素、删除元素等。
使用lxml库的etree.HTML()方法解析HTML文档
在处理HTML文档时,Python开发者通常会使用lxml库中的etree模块。etree模块提供了强大的XML和HTML解析功能,使得开发者能够轻松地解析、查询和修改XML和HTML文档。本文将详细介绍lxml库中的etree.HTML()方法,并展示其在实际应用中的使用方法。
etree.HTML()方法简介
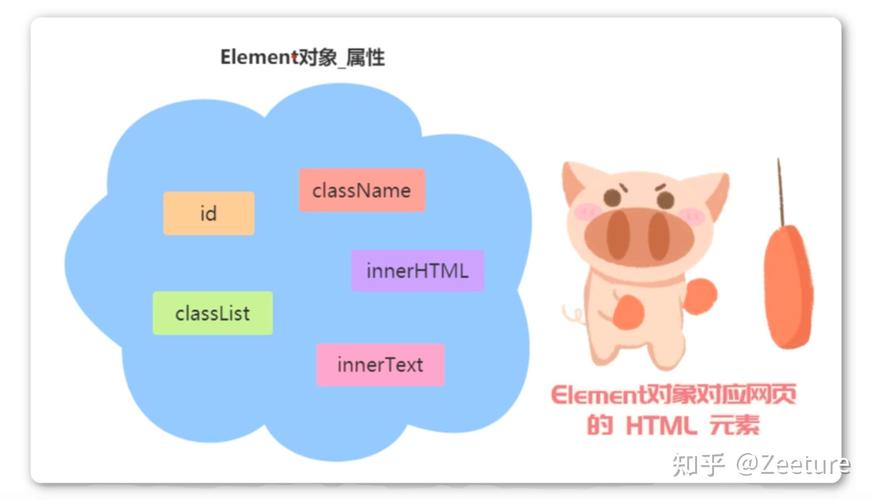
etree.HTML()是lxml库中etree模块的一个方法,用于将字符串格式的HTML文档解析成Element对象。Element对象是lxml库中用于表示XML和HTML文档的基本单元,它包含了文档的结构信息。
1. 解析HTML文档

使用etree.HTML()方法可以将字符串格式的HTML文档解析成Element对象。以下是一个简单的示例:
```python
from lxml import etree
html_text = '''
示例页面
欢迎来到我的博客
这是一个示例段落。
html = etree.HTML(html_text)
print(html.tag) 输出:html
2. 使用Element对象
- `.xpath()`:根据XPath表达式查询元素。
- `.find()`:查找第一个匹配的元素。
- `.findall()`:查找所有匹配的元素。
- `.getparent()`:获取当前元素的父元素。
- `.getchildren()`:获取当前元素的子元素。
以下是一个使用Element对象查询HTML文档的示例:
```python
查询标题
title = html.xpath('//title/text()')[0]
print(title) 输出:示例页面
查询所有段落
paragraphs = html.xpath('//p')
for paragraph in paragraphs:
print(paragraph.text) 输出:这是一个示例段落。
etree.tostring()方法
除了解析HTML文档外,etree模块还提供了etree.tostring()方法,用于将Element对象转换成字符串格式的HTML文档。
1. 转换Element对象
使用etree.tostring()方法可以将Element对象转换成字符串格式的HTML文档。以下是一个示例:
```python
from lxml import etree
html = etree.HTML(html_text)
new_html = etree.tostring(html, pretty_print=True).decode()
print(new_html)
在上面的示例中,我们首先解析了一个HTML文档,然后使用etree.tostring()方法将其转换成字符串格式的HTML文档,并打印出来。
2. pretty_print参数
etree.tostring()方法有一个可选的pretty_print参数,用于控制输出格式。当pretty_print=True时,输出格式将更加美观,便于阅读。
本文介绍了lxml库中的etree.HTML()方法,并展示了其在实际应用中的使用方法。通过使用etree.HTML()方法,我们可以轻松地将字符串格式的HTML文档解析成Element对象,并对其进行查询、修改和操作。此外,etree.tostring()方法还可以将Element对象转换成字符串格式的HTML文档,方便我们进行输出和存储。
```html
etree.html方法详解
使用lxml库的etree.HTML()方法解析HTML文档
在处理HTML文档时,Python开发者通常会使用lxml库中的etree模块。etree模块提供了强大的XML和HTML解析功能,使得开发者能够轻松地解析、查询和修改XML和HTML文档。本文将详细介绍lxml库中的etree.HTML()方法,并展示其在实际应用中的使用方法。
etree.HTML()方法简介
etree.HTML()是lxml库中etree模块的一个方法,用于将字符串格式的HTML文档解析成Element对象。Element对象是lxml库中用于表示XML和HTML文档的基本单元,它包含了文档的结构信息。
解析HTML文档
使用etree.HTML()方法可以将字符串格式的HTML文档解析成Element对象。以下是一个简单的示例:
etree.tostring()方法
除了解析HTML文档外,etree模块还提供了etree.tostring()方法,用于将Element对象转换成字符串