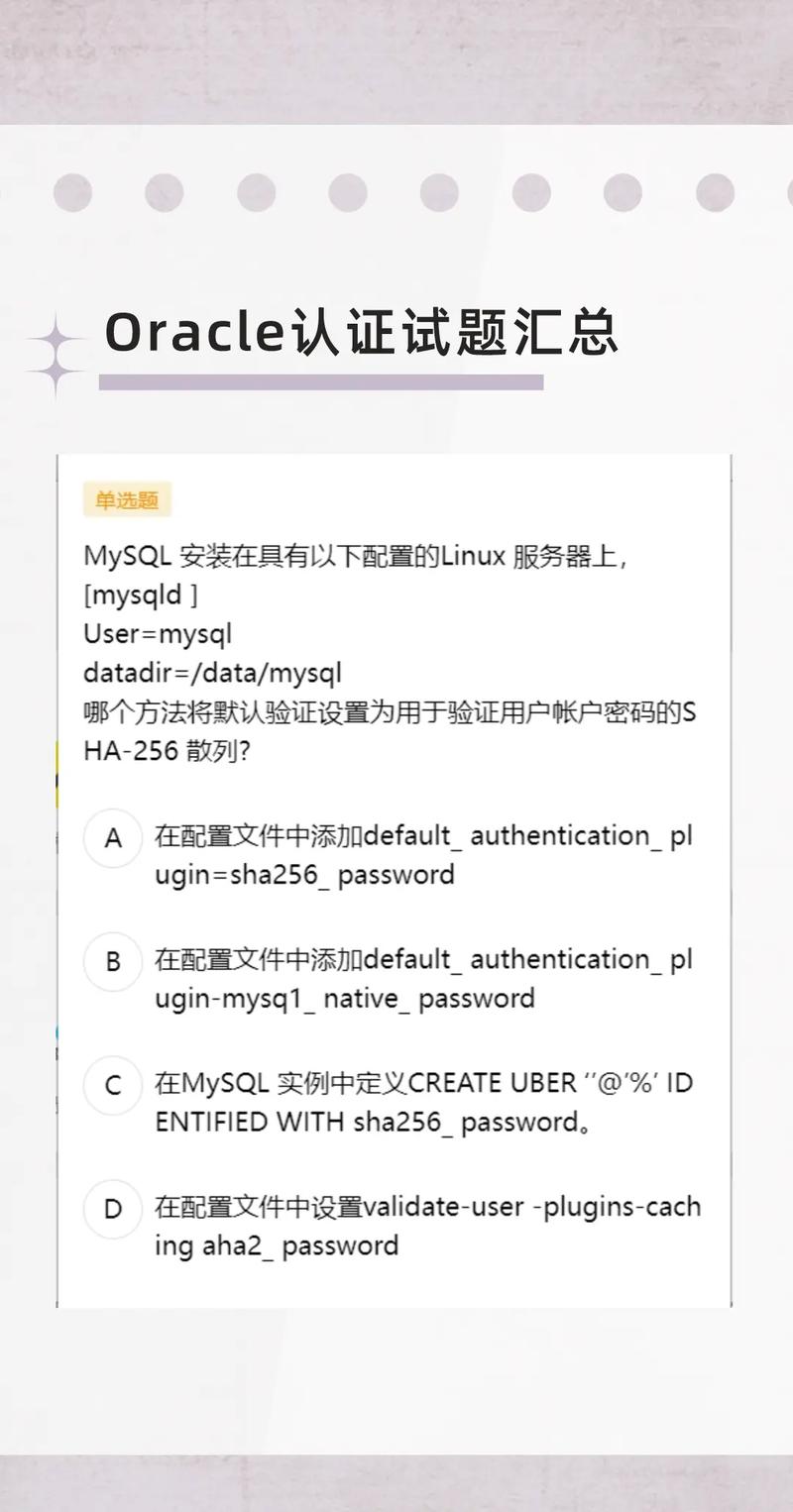
1. 了解基础知识: 学习基本的编程语言,如Python或R,它们在大数据处理中非常常用。 了解数据库的基本概念,包括关系型数据库(如MySQL)和非关系型数据库(如MongoDB)。 学习基本的统计学和数据分析方法。
2. 掌握大数据工具和技术: 学习Hadoop生态系统,包括HDFS、MapReduce、Hive、Pig、HBase等。 了解Spark,一个快速、通用的大数据处理引擎。 学习NoSQL数据库,如Cassandra、MongoDB等。 了解数据流处理技术,如Apache Kafka、Apache Flink等。
3. 实践项目: 通过实际项目来应用你的知识。可以从简单的数据集开始,逐渐处理更复杂的数据。 参与开源项目,如GitHub上的大数据相关项目,可以帮助你了解实际应用和最佳实践。
4. 学习机器学习和数据挖掘: 了解机器学习的基本概念和算法,如分类、回归、聚类等。 学习数据挖掘技术,如关联规则学习、序列模式挖掘等。
5. 参与社区和论坛: 加入大数据相关的社区和论坛,如Stack Overflow、Kaggle等,与其他学习者交流。 参加在线课程和研讨会,如Coursera、edX、Udacity等平台上的大数据课程。
6. 持续学习和更新知识: 大数据领域不断发展,新的工具和技术不断涌现。保持学习的态度,不断更新你的知识库。 阅读相关的书籍、博客和论文,了解最新的研究和发展。
7. 考虑专业认证: 如果你想在职业生涯中进一步提升,可以考虑获得大数据相关的专业认证,如Cloudera Certified Professional Data Scientist、 Hortonworks Certified Apache Spark Developer等。
记住,自学大数据是一个长期的过程,需要耐心和毅力。通过不断学习和实践,你将能够逐步掌握大数据的技能和知识。
零基础小白如何自学大数据:系统化学习指南

随着信息技术的飞速发展,大数据已经成为各行各业不可或缺的一部分。对于零基础的小白来说,自学大数据可能是一项挑战,但通过合理的规划和系统化的学习,完全能够掌握这一领域的核心知识和技能。本文将为您提供一个自学大数据的详细指南。
一、了解大数据的基本概念和应用场景

在开始学习大数据之前,首先需要了解什么是大数据以及它在各个行业中的应用。
大数据的核心概念:
大数据通常被概括为“5V”特征:数据量(Volume)、数据速度(Velocity)、数据多样性(Variety)、数据价值(Value)和数据真实性(Veracity)。
大数据的应用领域:
大数据在金融、医疗、零售、制造、政府、交通等行业中广泛应用,如市场分析、风险管理、欺诈检测、患者护理、库存管理和个性化营销等。
二、学习编程语言

编程语言是大数据处理的基础,以下几种语言在大数据领域较为常用:
Python:
Python广泛应用于数据处理和分析,尤其适合数据科学。
Java:
Java在大数据领域应用广泛,如Hadoop、Spark等框架都是用Java编写的。
Scala:
Scala是Java的一种扩展语言,在Spark等大数据框架中应用较多。
三、学习大数据平台
Hadoop:
Hadoop是一个分布式存储和计算框架,适用于处理大规模数据集。
Spark:
Spark是一个快速、通用的大数据处理引擎,支持多种编程语言。
Storm:
Storm是一个分布式实时计算系统,适用于处理实时数据。
四、学习数据存储与计算
分布式文件系统:
如HDFS(Hadoop Distributed File System)和Alluxio。
数据采集与同步:
如Flume、Logstash、Sqoop、DataX和MySQL Binlog。
数据存储与计算框架:
如Hadoop、Spark、Flink等。
五、学习数据分析与挖掘
数据预处理:
如数据清洗、数据集成、数据转换等。
统计分析:
如描述性统计、推断性统计、假设检验等。
机器学习:
如分类、回归、聚类、关联规则等。
参与开源项目:
通过参与开源项目,可以了解大数据技术的实际应用,并与其他开发者交流学习。
解决实际问题:
将所学知识应用于实际项目中,解决实际问题,提升自己的能力。
自学大数据需要耐心和毅力,但只要按照以上步骤进行系统化的学习,相信您一定能够掌握大数据的核心知识和技能。祝您学习顺利,早日成为大数据领域的专家!