大数据基础架构是指支持大数据收集、存储、处理、分析和可视化的技术框架。它包括硬件、软件、网络、数据源等多个组件,旨在高效地处理大规模、多样化、快速变化的数据集。
大数据基础架构的关键组件包括:
1. 数据收集:收集来自各种来源的数据,如社交媒体、物联网设备、交易系统等。
2. 数据存储:存储大量数据,通常使用分布式文件系统(如Hadoop HDFS)或NoSQL数据库(如MongoDB、Cassandra)。
3. 数据处理:使用分布式计算框架(如Hadoop MapReduce、Spark)处理和分析数据。
4. 数据分析:使用统计方法、机器学习算法和数据分析工具(如R、Python)来提取洞察和模式。
5. 数据可视化:将分析结果以图形和图表的形式呈现,以便于理解和决策。
6. 数据管理:包括数据质量控制、数据安全和数据治理,确保数据的准确性和合规性。
7. 硬件和网络:包括服务器、存储设备、网络设备和云计算资源,以支持大数据处理。
8. 数据集成:将来自不同来源的数据集成到一个统一的数据平台上,以便于分析和查询。
9. 数据访问:提供API和用户界面,以便于用户访问和查询大数据。
10. 数据治理:确保数据的质量、安全和合规性,以及数据的使用和共享策略。
大数据基础架构的选择和设计取决于组织的具体需求和目标,以及数据的规模、复杂性和速度。随着大数据技术的不断发展,大数据基础架构也在不断演变和优化,以适应不断变化的数据处理需求。
大数据基础架构概述
数据采集
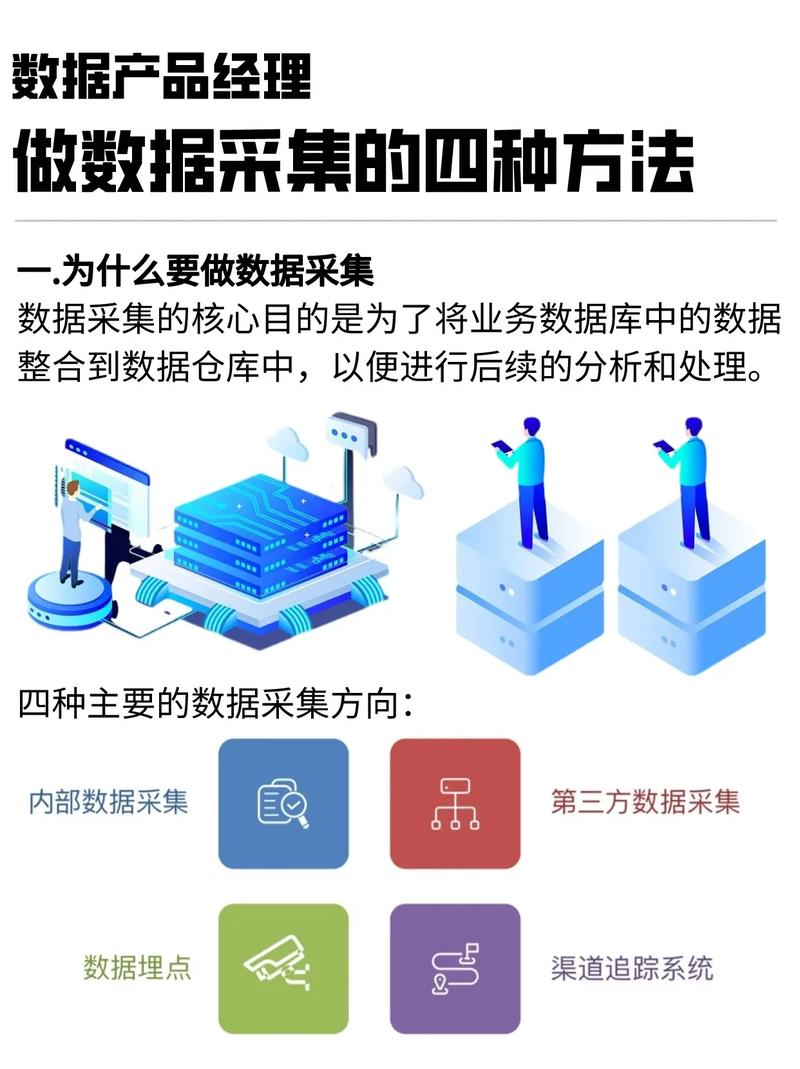
数据采集是大数据处理的第一步,也是最为关键的一步。数据采集主要涉及以下几种方式:
日志采集:通过日志系统收集服务器、应用程序等产生的日志数据。
网络采集:通过爬虫、API等方式从互联网上获取数据。
传感器采集:通过传感器设备收集环境、设备等产生的数据。
数据库采集:从关系型数据库、NoSQL数据库等数据源中提取数据。
数据存储

Hadoop HDFS:分布式文件系统,适用于存储海量非结构化数据。
NoSQL数据库:如MongoDB、Cassandra等,适用于存储海量半结构化或非结构化数据。
关系型数据库:如MySQL、Oracle等,适用于存储结构化数据。
数据湖:如Amazon S3、Google Cloud Storage等,提供海量数据的存储和访问能力。
数据处理

MapReduce:Hadoop的核心计算框架,适用于大规模数据处理。
Spark:基于内存的分布式计算框架,适用于实时数据处理。
Storm:实时数据处理框架,适用于流式数据处理。
Flink:流处理和批处理框架,适用于复杂事件处理。
数据分析

机器学习:通过算法从数据中学习规律,用于预测、分类、聚类等任务。
数据挖掘:从大量数据中挖掘出有价值的信息,用于决策支持。
统计分析:对数据进行统计分析,揭示数据之间的规律。
可视化:将数据以图形、图表等形式展示,便于理解和分析。
大数据可视化
Tableau:数据可视化工具,支持多种数据源和图表类型。
Power BI:数据可视化工具,与Microsoft Office集成良好。
QlikView:数据可视化工具,支持实时数据分析和交互。
Python可视化库:如Matplotlib、Seaborn等,适用于Python编程语言。
大数据安全与隐私
数据加密:对敏感数据进行加密,防止数据泄露。
访问控制:限制对数据的访问权限,确保数据安全。
审计日志:记录数据访问和操作记录,便于追踪和审计。
数据脱敏:对敏感数据进行脱敏处理,保护个人隐私。
大数据基础架构是支撑大数据处理和分析的软硬件环境,包括数据采集、存储、处理、分析和可视化等环节。随着大数据技术的不断发展,大数据基础架构也在不断优化和升级,以满足日益增长的数据处理需求。