Python 读取 HTML 文件:深入解析与数据提取指南
在当今的互联网时代,HTML 文件作为网页内容的主要载体,其重要性不言而喻。Python 作为一种功能强大的编程语言,提供了多种库和工具来读取和解析 HTML 文件。本文将深入探讨如何使用 Python 读取 HTML 文件,包括基本概念、常用库介绍以及实际操作步骤。
一、Python 读取 HTML 文件的基本概念
HTML 文件格式

Python 库介绍
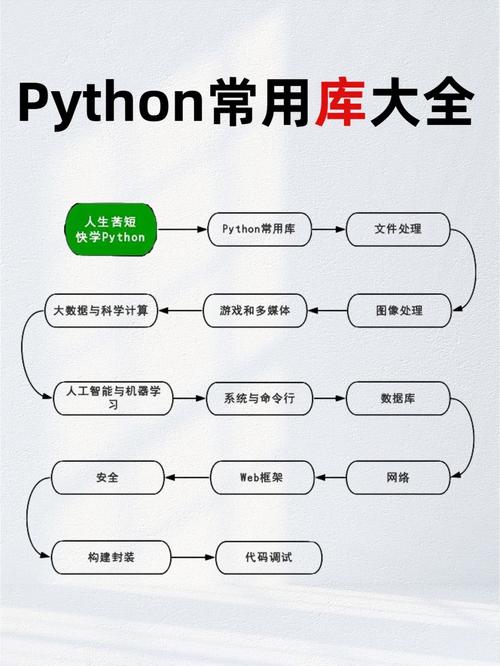
在 Python 中,有几个库可以用来读取和解析 HTML 文件,包括:
- BeautifulSoup:一个从 Python 代码中构建文档树结构的库,用于解析 HTML 和 XML 文档。
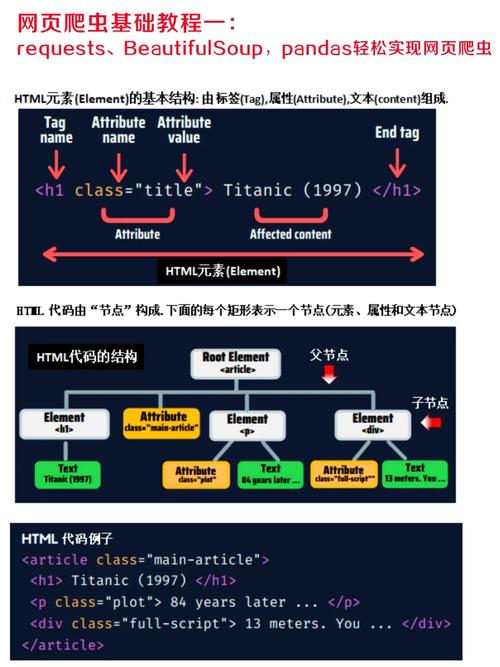
- lxml:一个基于 C 的库,提供了高效的 XML 和 HTML 解析器。

- html.parser:Python 标准库中的一个简单 HTML 解析器。
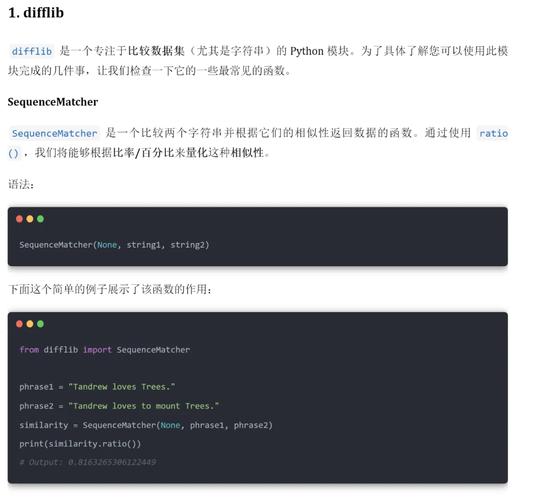
二、安装必要的库

安装 BeautifulSoup

```python
pip install beautifulsoup4
安装 lxml
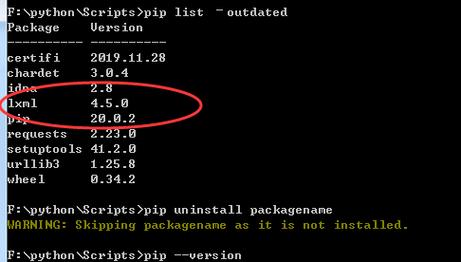
```python
pip install lxml
三、读取 HTML 文件
使用 BeautifulSoup 读取 HTML 文件
```python
from bs4 import BeautifulSoup
打开 HTML 文件
with open('example.html', 'r', encoding='utf-8') as file:
html_content = file.read()
解析 HTML 文件
soup = BeautifulSoup(html_content, 'html.parser')
打印解析后的 HTML 文档
print(soup.prettify())
使用 lxml 读取 HTML 文件
```python
from lxml import etree
解析 HTML 文件
tree = etree.parse('example.html')
打印解析后的 HTML 文档
print(etree.tostring(tree, pretty_print=True).decode('utf-8'))
四、解析 HTML 文件
使用 BeautifulSoup 解析 HTML 元素
```python
titles = soup.find_all('h1')
for title in titles:
print(title.get_text())
获取特定 ID 的元素
element = soup.find(id='my-id')
print(element.get_text())
使用 lxml 解析 HTML 元素
```python
titles = tree.xpath('//h1/text()')
for title in titles:
print(title)
获取特定 ID 的元素
element = tree.xpath('//div[@id=\