1. 数据库管理系统: MySQL:一种关系型数据库管理系统,常用于处理结构化数据。 MongoDB:一种NoSQL数据库,适用于存储非结构化数据。 Hadoop:一个开源框架,用于在分布式系统上处理大数据集。 Cassandra:一个分布式NoSQL数据库,适用于高可用性和可扩展性。
2. 数据分析和可视化工具: Tableau:一个数据可视化工具,用于创建交互式图表和仪表板。 Power BI:微软的数据可视化工具,可以连接多种数据源并创建报告。 QlikView:一个数据发现和可视化工具,用于探索和可视化数据。 R语言:一种统计计算和图形展示的语言,常用于数据分析和可视化。
3. 数据挖掘工具: Weka:一个开源的数据挖掘工具,包含多种机器学习算法。 Scikitlearn:一个Python库,用于数据挖掘和数据分析。 TensorFlow:一个开源的机器学习框架,适用于深度学习。 Keras:一个高级神经网络API,用于构建和训练模型。
4. 大数据处理平台: Apache Spark:一个开源的大数据处理平台,支持实时处理和批处理。 Apache Flink:一个流处理框架,用于处理无界和有界数据集。 Apache Storm:一个实时流处理框架,适用于实时大数据处理。
5. 云平台和托管服务: Amazon Web Services :提供各种大数据处理服务,如Amazon Redshift、Amazon EMR等。 Microsoft Azure:提供大数据处理服务,如Azure HDInsight、Azure Databricks等。 Google Cloud Platform :提供大数据处理服务,如Google BigQuery、Google Cloud Dataflow等。
这些软件和工具可以帮助你处理、分析和可视化大数据,从而提取有价值的信息和洞察。选择合适的工具取决于你的具体需求和数据类型。
大数据处理软件:助力企业高效应对海量数据挑战

一、Hadoop生态系统
Hadoop生态系统是大数据处理领域的事实标准,它由多个组件组成,共同实现大数据的存储、处理和分析。
1. Hadoop分布式文件系统(HDFS)
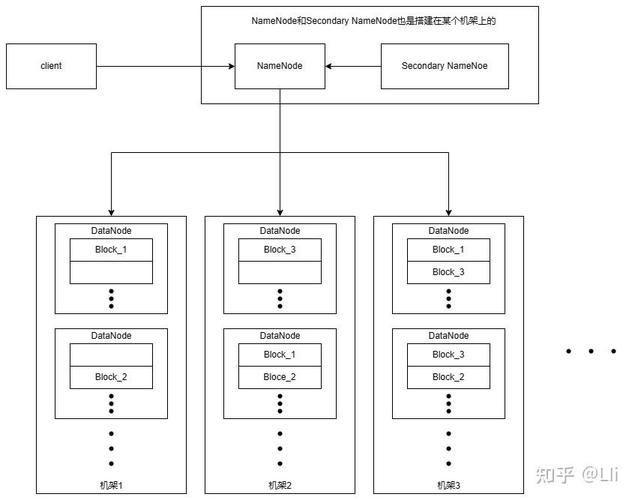
HDFS是Hadoop的核心存储系统,它将文件分割成多个数据块,并将这些数据块存储在集群中的不同节点上。HDFS具有高容错性,能够自动检测和恢复数据块的丢失或损坏。
2. Hadoop分布式计算框架(MapReduce)
MapReduce是Hadoop的核心计算框架,它将大数据分割成多个小的数据块,分布存储在集群中的不同节点上,然后通过分布式计算框架对这些数据进行处理和分析。
3. YARN

YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,它负责管理集群中的资源,并将资源分配给不同的应用程序。
4. Hive

Hive是一个数据仓库工具,它可以将结构化数据映射为Hive表,并使用类似SQL的查询语言进行数据查询和分析。
5. HBase
HBase是一个分布式列式数据库,它适用于存储非结构化和半结构化数据,并支持实时读取和写入。
二、Spark生态系统
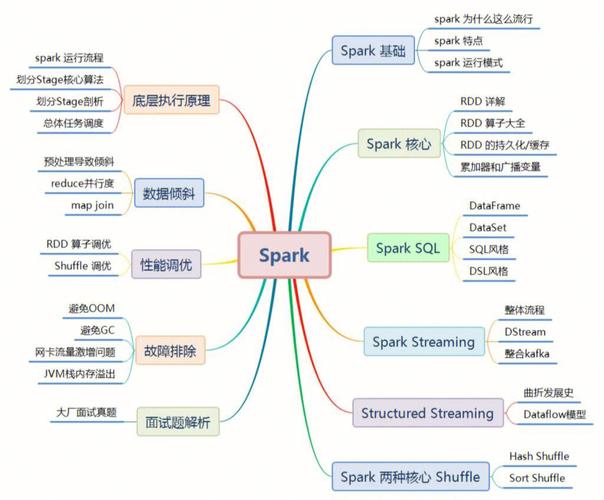
Spark是Hadoop生态系统的有力补充,它提供了更高效、更灵活的大数据处理能力。
1. Spark Core
Spark Core是Spark的基础框架,它提供了内存计算、弹性分布式数据集(RDD)等核心功能。
2. Spark SQL
Spark SQL是Spark的数据处理工具,它支持结构化数据处理,并提供了类似SQL的查询语言。
3. Spark Streaming
Spark Streaming是Spark的实时数据处理工具,它能够实时处理数据流,并支持多种数据源。
4. MLlib
MLlib是Spark的机器学习库,它提供了多种机器学习算法和工具,方便用户进行数据挖掘和分析。
5. GraphX
GraphX是Spark的图处理库,它提供了图算法和工具,方便用户进行图数据分析和挖掘。
三、其他大数据处理软件
除了Hadoop和Spark,还有一些其他优秀的大数据处理软件,以下列举几款:
1. Kafka

Kafka是一个分布式的流处理平台,它支持高吞吐量、可扩展性和可靠性的分布式消息传递。
2. Elasticsearch
Elasticsearch是一个开源的搜索引擎,它能够快速、高效地处理海量数据,并支持多种数据源。
3. Flink

Flink是一个流处理框架,它支持实时数据处理,并具有高吞吐量和低延迟的特点。
4. Logstash
Logstash是一个开源的数据收集和传输工具,它能够从各种数据源中收集数据,并将其传输到目标系统。