1. 请简述大数据的定义及其重要性。 回答示例: 大数据是指规模巨大、类型多样、处理速度快的数据集合。大数据的重要性在于它可以帮助企业、政府和个人更好地理解复杂问题,做出更明智的决策,提高效率和生产力。
2. 请解释Hadoop生态系统中的主要组件及其作用。 回答示例: Hadoop生态系统包括HDFS(Hadoop Distributed File System)、MapReduce、YARN(Yet Another Resource Negotiator)、Hive、HBase、Pig、Sqoop、Flume等组件。HDFS用于存储大数据,MapReduce用于处理大数据,YARN用于资源管理,Hive用于数据仓库,HBase用于实时数据访问,Pig用于数据处理,Sqoop用于数据导入/导出,Flume用于数据采集。
3. 请解释什么是数据挖掘,以及它在大数据中的应用。 回答示例: 数据挖掘是从大量数据中提取有价值信息的过程。在大数据中,数据挖掘可以帮助发现隐藏的模式、趋势和关联,从而为商业决策、市场营销、风险管理等提供支持。
4. 请简述Spark与Hadoop MapReduce的区别。 回答示例: Spark是一个快速、通用的计算引擎,支持内存计算,提供多种API(如Scala、Java、Python、R)。Hadoop MapReduce是一个基于磁盘的计算框架,主要用于批处理。Spark比Hadoop MapReduce更快,因为它是基于内存的,并且提供了更丰富的API。
5. 请解释什么是数据仓库,以及它在大数据中的应用。 回答示例: 数据仓库是一个集中存储大量数据的系统,用于支持数据分析和报告。在大数据中,数据仓库可以存储来自多个来源的数据,并提供一个统一的数据视图,以便进行数据分析和报告。
6. 请简述什么是机器学习,以及它在大数据中的应用。 回答示例: 机器学习是一种让计算机自动学习和改进的技术。在大数据中,机器学习可以用于预测分析、推荐系统、图像识别、自然语言处理等。
7. 请解释什么是数据治理,以及它在大数据中的应用。 回答示例: 数据治理是指管理数据质量、数据安全、数据隐私等问题的过程。在大数据中,数据治理可以帮助确保数据的质量和安全性,遵守相关法规和政策。
8. 请简述什么是数据湖,以及它在大数据中的应用。 回答示例: 数据湖是一个存储原始、未加工数据的系统,用于支持大数据分析和机器学习。在大数据中,数据湖可以存储来自多个来源的数据,并提供一个灵活、可扩展的数据存储解决方案。
9. 请解释什么是数据可视化,以及它在大数据中的应用。 回答示例: 数据可视化是将数据转换为图形、图表等视觉形式的过程。在大数据中,数据可视化可以帮助用户更直观地理解数据,发现数据中的模式和趋势。
10. 请简述什么是数据安全,以及它在大数据中的应用。 回答示例: 数据安全是指保护数据免受未授权访问、泄露、篡改等威胁的过程。在大数据中,数据安全是非常重要的,因为大数据通常包含敏感和重要的信息。
这些面试题只是大数据领域的一小部分。在实际面试中,面试官可能会根据你的背景和经验提出更具体的问题。因此,在准备面试时,最好了解大数据领域的最新趋势和技术,以及相关的实际应用案例。
大数据面试题全解析,助你轻松应对面试挑战

随着大数据技术的快速发展,越来越多的企业开始重视大数据人才的培养。大数据面试题成为了求职者进入心仪企业的重要关卡。本文将为您全面解析大数据面试题,助您轻松应对面试挑战。
一、大数据基础知识

1. 什么是大数据?
大数据是指数据量非常庞大、多样化、高速增长、难以处理的数据。它具有4个特征:大量(Volume)、多样(Variety)、快速(Velocity)和价值(Value)。
2. 大数据技术的特点是什么?
大数据技术具有以下特点:
分布式存储:如HDFS、HBase等。
分布式计算:如MapReduce、Spark等。
实时处理:如Storm、Flink等。
数据挖掘与分析:如Hive、Pig等。
二、Hadoop生态圈
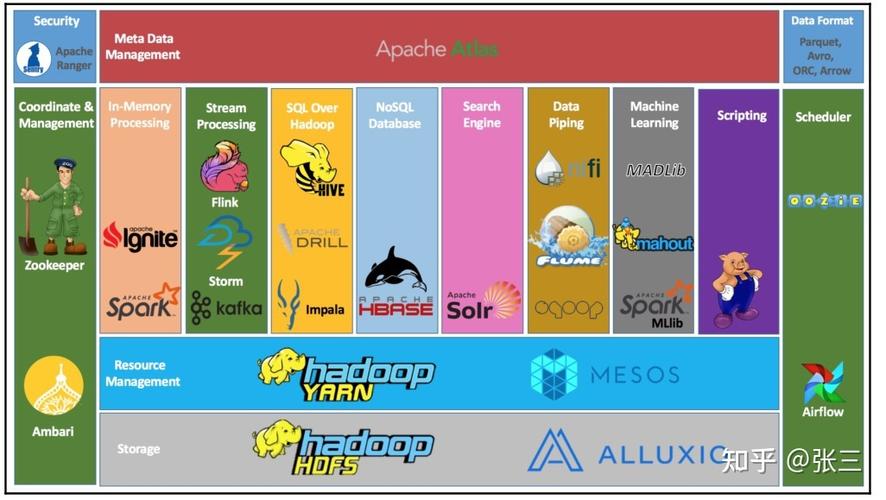
1. 什么是Hadoop?
Hadoop是一个开源的分布式计算框架,用于存储和处理大规模数据集。
2. Hadoop的核心组件是什么?
Hadoop的架构可以划分为两个主要部分:HDFS和MapReduce。
HDFS:分布式文件系统,负责存储数据。
MapReduce:分布式计算框架,负责处理数据。
三、Spark技术栈
1. 什么是Spark?
Spark是一个开源的分布式计算系统,用于大规模数据处理。它具有以下特点:
速度快:Spark的运行速度比Hadoop快100倍。
通用性:Spark支持多种编程语言,如Java、Scala、Python等。
易用性:Spark提供了丰富的API和工具,方便用户进行数据处理。
2. Spark的核心组件有哪些?
Spark Core:Spark的核心组件,提供分布式计算框架。
Spark SQL:Spark的SQL接口,用于处理结构化数据。
Spark Streaming:Spark的实时数据处理组件。
MLlib:Spark的机器学习库。
四、Kafka
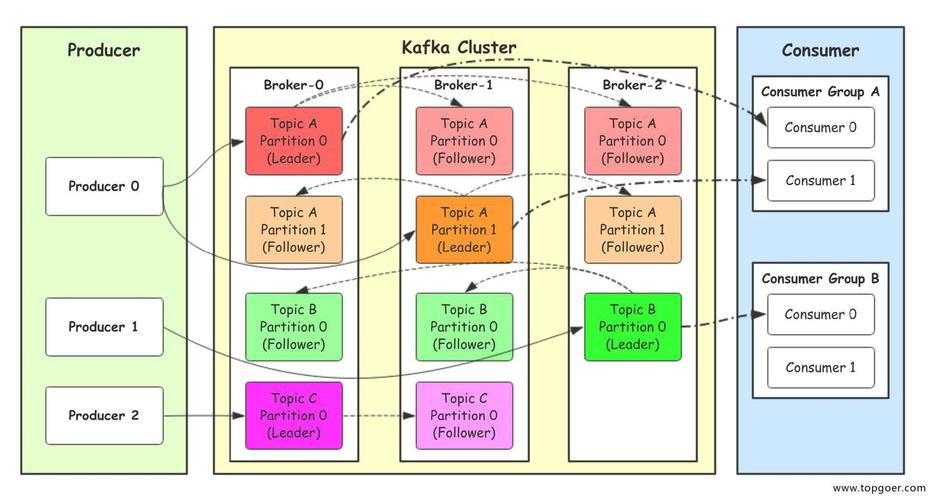
1. 什么是Kafka?
Kafka是一个开源的分布式流处理平台,用于构建实时数据管道和流应用程序。
2. Kafka的主要特点有哪些?
高吞吐量:Kafka可以处理高吞吐量的数据。
可扩展性:Kafka可以水平扩展,以适应不断增长的数据量。
持久性:Kafka可以保证数据的持久性,即使在系统故障的情况下也不会丢失数据。
五、HBase
1. 什么是HBase?
HBase是一个分布式、可扩展的NoSQL数据库,建立在HDFS之上。
2. HBase的主要特点有哪些?
高吞吐量:HBase可以处理高吞吐量的数据。
可扩展性:HBase可以水平扩展,以适应不断增长的数据量。
强一致性:HBase保证数据的强一致性。
六、数据仓库与数据湖
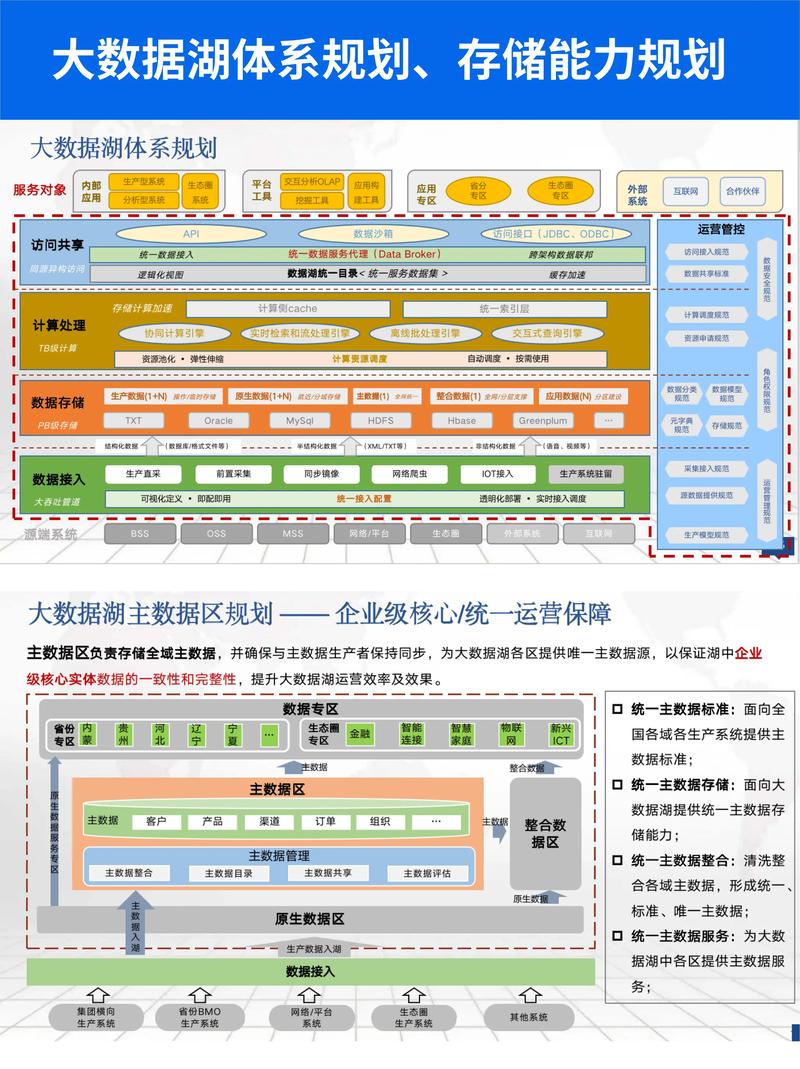
1. 什么是数据仓库?
数据仓库是一个用于存储、管理和分析大量数据的系统。
2. 什么是数据湖?
数据湖是一个用于存储原始数据的系统,它不依赖于特定的数据格式或结构。
七、必备SQL题与算法题

1. SQL题
编写一个SQL查询,统计每个部门员工的平均薪资。
编写一个SQL查询,找出销售额最高的前10个产品。
2. 算法题
实现一个快速排序算法。
实现一个二分查找算法。
大数据面试题