1. 分布式文件系统:如Hadoop Distributed File System 和 Apache Cassandra,它们可以在多个节点上分布式地存储和处理数据。
2. 数据湖:数据湖是一个集中存储结构化和非结构化数据的存储库,它允许用户存储大量数据,而无需在存储之前对其进行结构化处理。
3. 关系型数据库:如MySQL、PostgreSQL和Oracle,它们适用于需要严格数据一致性和事务完整性的应用。
4. NoSQL数据库:如MongoDB、Couchbase和Redis,它们适用于需要高可扩展性和高性能的应用。
5. 云存储服务:如Amazon S3、Google Cloud Storage和Microsoft Azure Blob Storage,它们提供可扩展的、按需付费的存储解决方案。
6. 对象存储:如OpenStack Swift和Ceph,它们适用于需要大规模、可扩展的存储解决方案。
7. 分布式数据库:如CockroachDB和Google Spanner,它们适用于需要高可用性和一致性的分布式应用。
8. 数据仓库:如Amazon Redshift、Google BigQuery和Snowflake,它们适用于需要高效查询和分析大量数据的应用。
9. 内存数据网格:如Apache Ignite和 Hazelcast,它们适用于需要高性能和低延迟的数据访问的应用。
10. 数据流处理:如Apache Kafka和Amazon Kinesis,它们适用于需要实时处理和分析数据流的应用。
选择适合的大数据存储方案取决于具体的应用场景、数据类型、性能要求、可扩展性需求以及预算等因素。
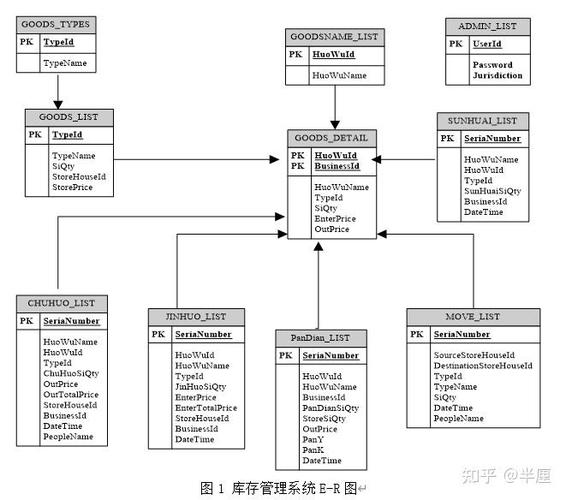
大数据存储方案概述
随着信息技术的飞速发展,大数据已经成为企业决策、创新和市场竞争的重要资源。大数据存储方案作为大数据处理的基础,其重要性不言而喻。本文将探讨大数据存储方案的设计原则、关键技术以及应用场景。
一、大数据存储方案设计原则
1. 高可用性:确保数据在存储过程中不丢失,系统在故障情况下能够快速恢复。

2. 高性能:满足大数据处理对存储速度的要求,提高数据处理效率。
3. 可扩展性:随着数据量的增长,存储系统应能够灵活扩展,满足不断增长的数据存储需求。
4. 安全性:保护数据不被非法访问、篡改或泄露,确保数据安全。

5. 经济性:在满足上述要求的前提下,降低存储成本,提高投资回报率。

二、大数据存储关键技术
1. 分布式存储技术:如Hadoop的HDFS(Hadoop Distributed File System),通过将数据分散存储在多个节点上,提高数据存储的可靠性和扩展性。
2. 对象存储技术:如Amazon S3,适用于存储海量非结构化数据,具有高可用性和可扩展性。
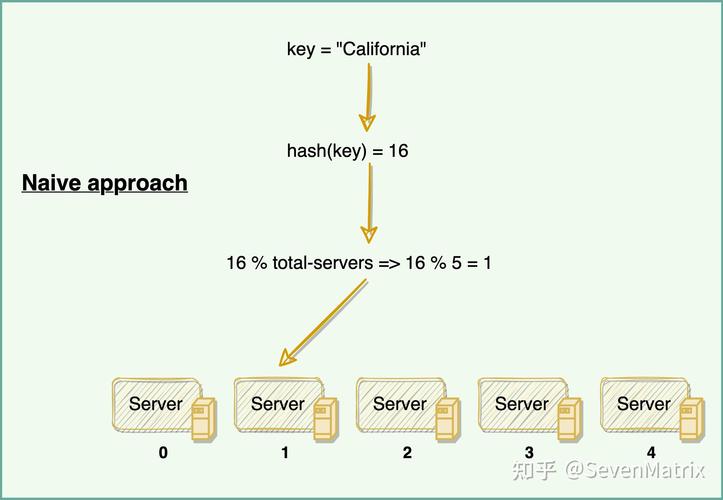
3. 块存储技术:如Ceph,提供高性能、高可靠性的块存储服务,适用于虚拟化环境。
4. 文件存储技术:如NFS(Network File System),适用于存储结构化数据,支持跨平台访问。
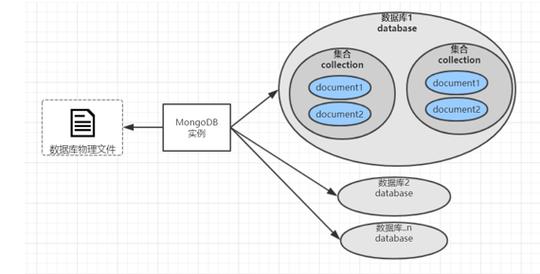
5. 数据库存储技术:如MongoDB,适用于存储半结构化数据,支持灵活的查询和索引。
三、大数据存储方案应用场景
1. 日志存储:企业可以通过分布式存储技术,如HDFS,存储和分析海量日志数据,实现日志数据的实时监控和分析。
2. 视频监控:利用对象存储技术,如Amazon S3,存储海量视频监控数据,实现视频数据的快速检索和回放。
3. 基因测序:通过分布式存储技术,如Ceph,存储和分析海量基因测序数据,提高基因研究的效率。
4. 社交网络:利用数据库存储技术,如MongoDB,存储用户关系数据,实现社交网络的推荐和广告投放。

5. 金融风控:通过大数据存储方案,存储和分析金融交易数据,实现风险预警和防控。

四、大数据存储方案实施建议
1. 需求分析:根据企业实际需求,选择合适的存储技术和方案。

2. 技术选型:综合考虑性能、可靠性、可扩展性等因素,选择合适的存储技术。
3. 系统集成:将存储系统与其他大数据处理组件(如计算、分析等)进行集成,实现数据的高效处理。
4. 安全防护:加强数据安全防护,防止数据泄露和篡改。
5. 运维管理:建立完善的运维管理体系,确保存储系统的稳定运行。
大数据存储方案是企业大数据战略的重要组成部分。通过合理设计、选择合适的技术和方案,企业可以有效地存储和管理海量数据,为业务创新和市场竞争提供有力支持。